 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic filtering by inference on domain knowledge in spoken dialogue systems
Oct 23, 2004General natural dialogue processing requires large amounts of domain knowledge as well as linguistic knowledge in order to ensure acceptable coverage and understanding. There are several ways of integrating lexical resources (e.g. dictionaries, thesauri) and knowledge bases or ontologies at different levels of dialogue processing. We concentrate in this paper on how to exploit domain knowledge for filtering interpretation hypotheses generated by a robust semantic parser. We use domain knowledge to semantically constrain the hypothesis space. Moreover, adding an inference mechanism allows us to complete the interpretation when information is not explicitly available. Further, we discuss briefly how this can be generalized towards a predictive natural interactive system.
* 6 pages
A knowledge-based approach to semi-automatic annotation of multimedia documents via user adaptation
Oct 23, 2004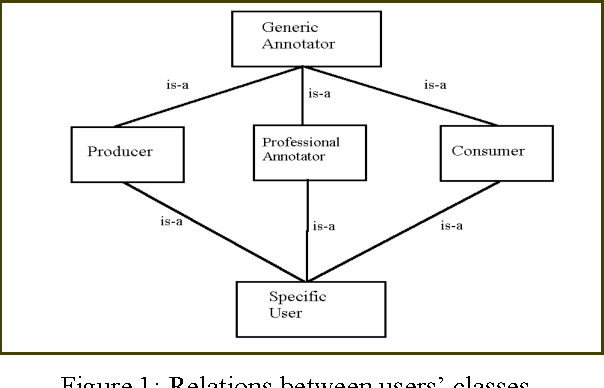
Current approaches to the annotation process focus on annotation schemas, languages for annotation, or are very application driven. In this paper it is proposed that a more flexible architecture for annotation requires a knowledge component to allow for flexible search and navigation of the annotated material. In particular, it is claimed that a general approach must take into account the needs, competencies, and goals of the producers, annotators, and consumers of the annotated material. We propose that a user-model based approach is, therefore, necessary.
* 4 pages
Robust Dialogue Understanding in HERALD
Oct 22, 2004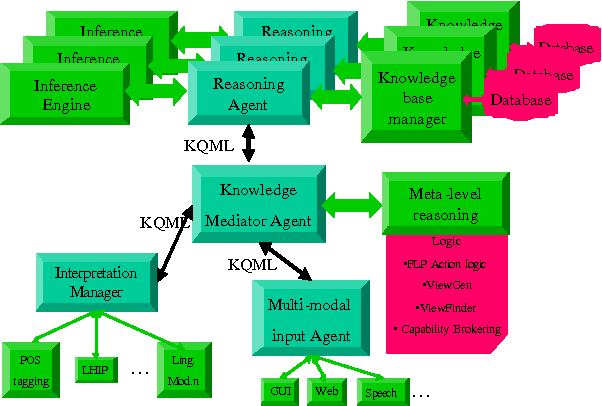
We tackle the problem of robust dialogue processing from the perspective of language engineering. We propose an agent-oriented architecture that allows us a flexible way of composing robust processors. Our approach is based on Shoham's Agent Oriented Programming (AOP) paradigm. We will show how the AOP agent model can be enriched with special features and components that allow us to deal with classical problems of dialogue understanding.
* 6 pages
The role of robust semantic analysis in spoken language dialogue systems
Aug 25, 2004In this paper we summarized a framework for designing grammar-based procedure for the automatic extraction of the semantic content from spoken queries. Starting with a case study and following an approach which combines the notions of fuzziness and robustness in sentence parsing, we showed we built practical domain-dependent rules which can be applied whenever it is possible to superimpose a sentence-level semantic structure to a text without relying on a previous deep syntactical analysis. This kind of procedure can be also profitably used as a pre-processing tool in order to cut out part of the sentence which have been recognized to have no relevance in the understanding process. In the case of particular dialogue applications where there is no need to build a complex semantic structure (e.g. word spotting or excerpting) the presented methodology may represent an efficient alternative solution to a sequential composition of deep linguistic analysis modules. Even if the query generation problem may not seem a critical application it should be held in mind that the sentence processing must be done on-line. Having this kind of constraints we cannot design our system without caring for efficiency and thus provide an immediate response. Another critical issue is related to whole robustness of the system. In our case study we tried to make experiences on how it is possible to deal with an unreliable and noisy input without asking the user for any repetition or clarification. This may correspond to a similar problem one may have when processing text coming from informal writing such as e-mails, news and in many cases Web pages where it is often the case to have irrelevant surrounding information.
* 6 pages
Semantic robust parsing for noun extraction from natural language queries
Sep 02, 1999This paper describes how robust parsing techniques can be fruitful applied for building a query generation module which is part of a pipelined NLP architecture aimed at process natural language queries in a restricted domain. We want to show that semantic robustness represents a key issue in those NLP systems where it is more likely to have partial and ill-formed utterances due to various factors (e.g. noisy environments, low quality of speech recognition modules, etc...) and where it is necessary to succeed, even if partially, in extracting some meaningful information.
LHIP: Extended DCGs for Configurable Robust Parsing
Aug 03, 1994We present LHIP, a system for incremental grammar development using an extended DCG formalism. The system uses a robust island-based parsing method controlled by user-defined performance thresholds.
* 10 pages, in Proc. Coling94