 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThematic Annotation: extracting concepts out of documents
Paper and Code
Dec 30, 2004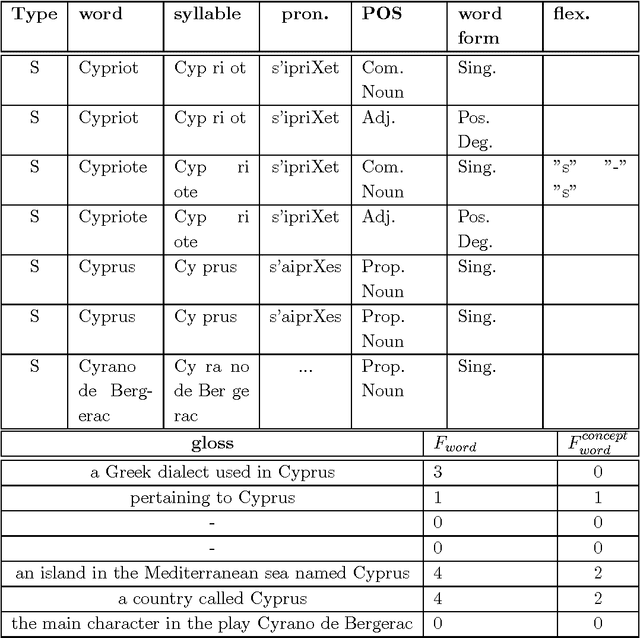
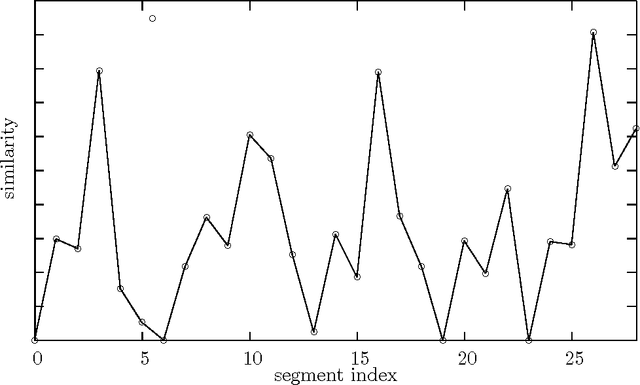
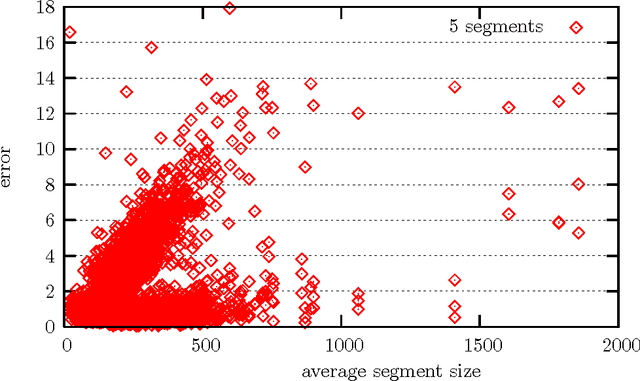
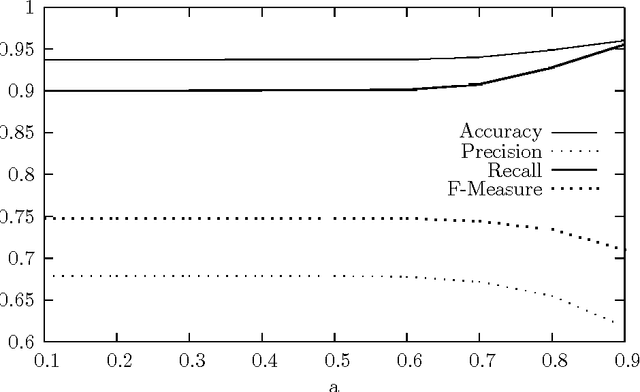
Contrarily to standard approaches to topic annotation, the technique used in this work does not centrally rely on some sort of -- possibly statistical -- keyword extraction. In fact, the proposed annotation algorithm uses a large scale semantic database -- the EDR Electronic Dictionary -- that provides a concept hierarchy based on hyponym and hypernym relations. This concept hierarchy is used to generate a synthetic representation of the document by aggregating the words present in topically homogeneous document segments into a set of concepts best preserving the document's content. This new extraction technique uses an unexplored approach to topic selection. Instead of using semantic similarity measures based on a semantic resource, the later is processed to extract the part of the conceptual hierarchy relevant to the document content. Then this conceptual hierarchy is searched to extract the most relevant set of concepts to represent the topics discussed in the document. Notice that this algorithm is able to extract generic concepts that are not directly present in the document.