 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Cross-institution text mining to uncover clinical associations: a case study relating social factors and code status in intensive care medicine
Jan 16, 2023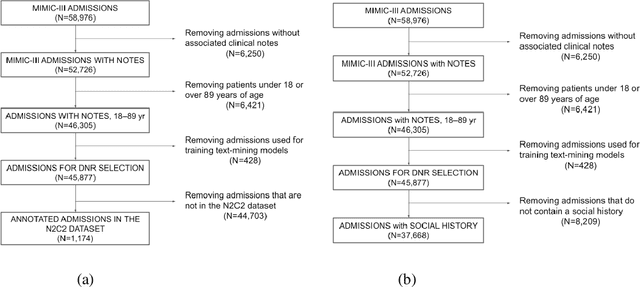

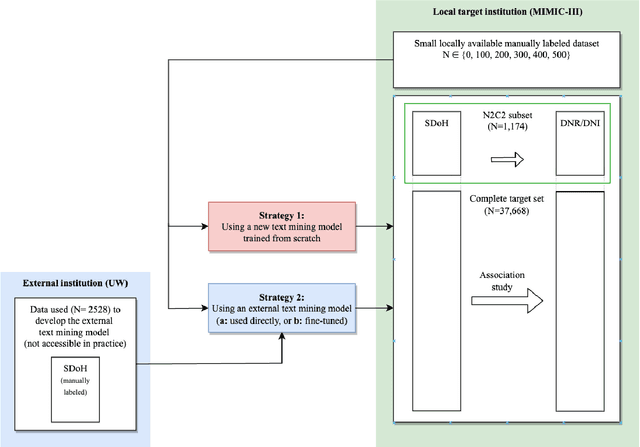
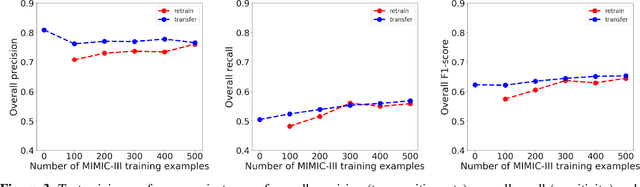
Objective: Text mining of clinical notes embedded in electronic medical records is increasingly used to extract patient characteristics otherwise not or only partly available, to assess their association with relevant health outcomes. As manual data labeling needed to develop text mining models is resource intensive, we investigated whether off-the-shelf text mining models developed at external institutions, together with limited within-institution labeled data, could be used to reliably extract study variables to conduct association studies. Materials and Methods: We developed multiple text mining models on different combinations of within-institution and external-institution data to extract social factors from discharge reports of intensive care patients. Subsequently, we assessed the associations between social factors and having a do-not-resuscitate/intubate code. Results: Important differences were found between associations based on manually labeled data compared to text-mined social factors in three out of five cases. Adopting external-institution text mining models using manually labeled within-institution data resulted in models with higher F1-scores, but not in meaningfully different associations. Discussion: While text mining facilitated scaling analyses to larger samples leading to discovering a larger number of associations, the estimates may be unreliable. Confirmation is needed with better text mining models, ideally on a larger manually labeled dataset. Conclusion: The currently used text mining models were not sufficiently accurate to be used reliably in an association study. Model adaptation using within-institution data did not improve the estimates. Further research is needed to set conditions for reliable use of text mining in medical research.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022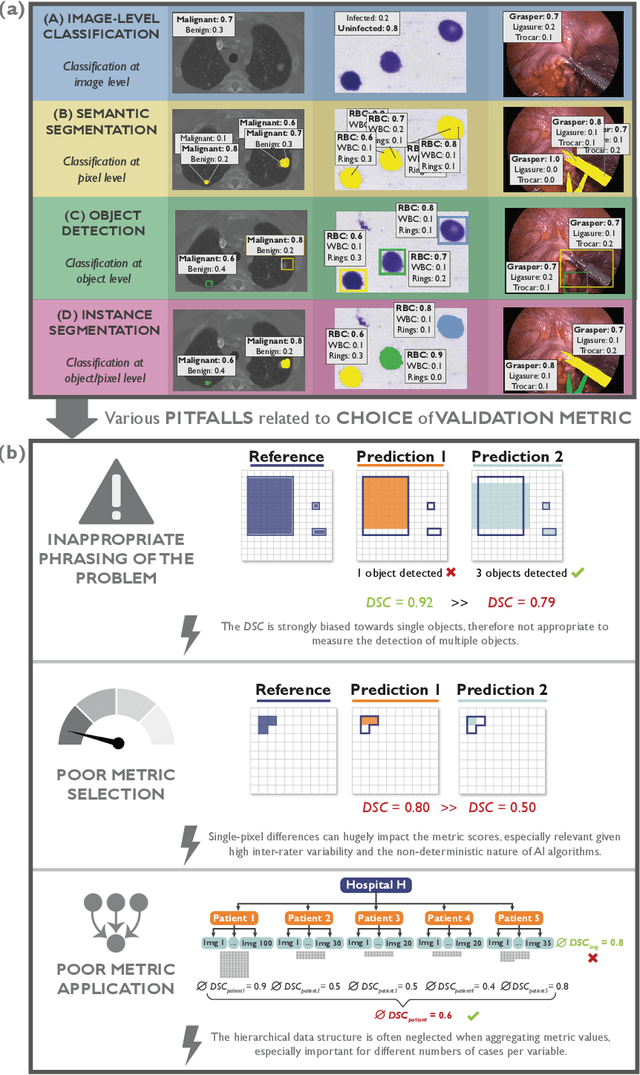
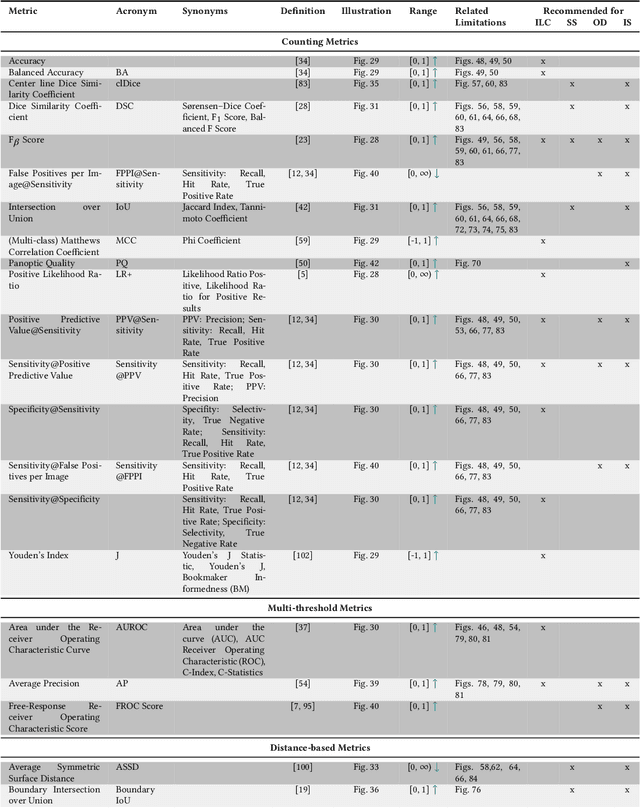
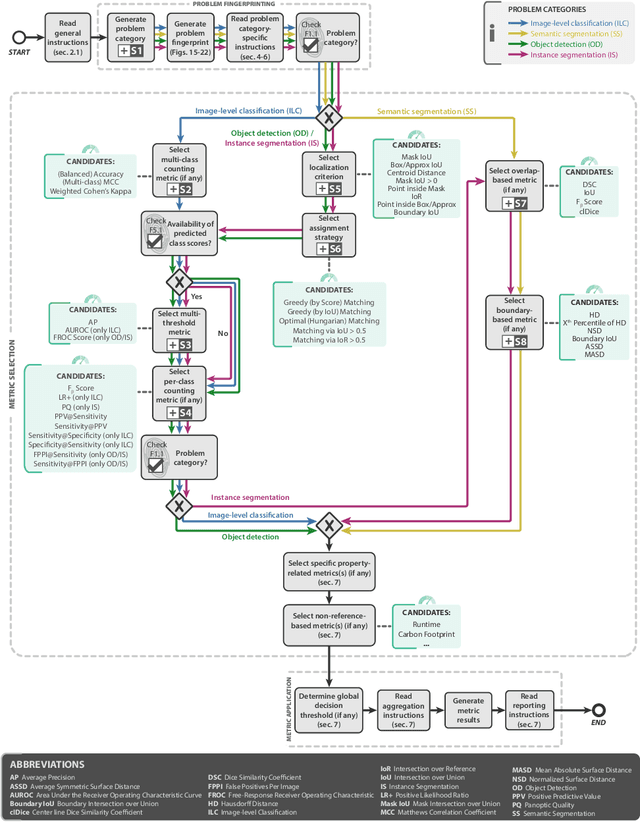
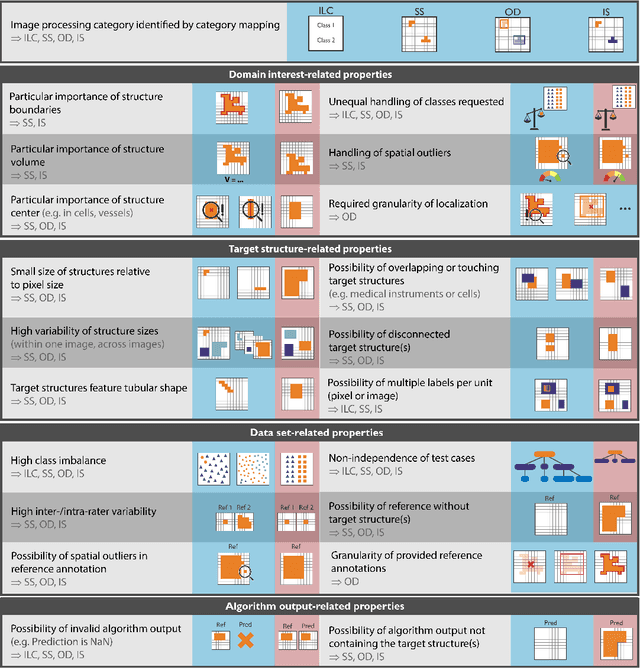
The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Propensity score estimation using classification and regression trees in the presence of missing covariate data
Jul 25, 2018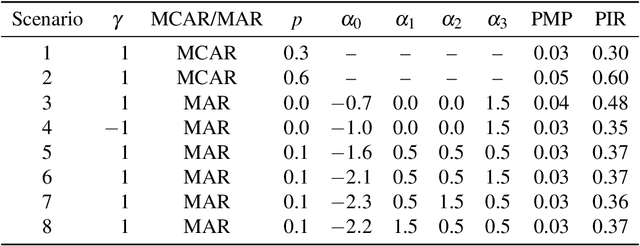
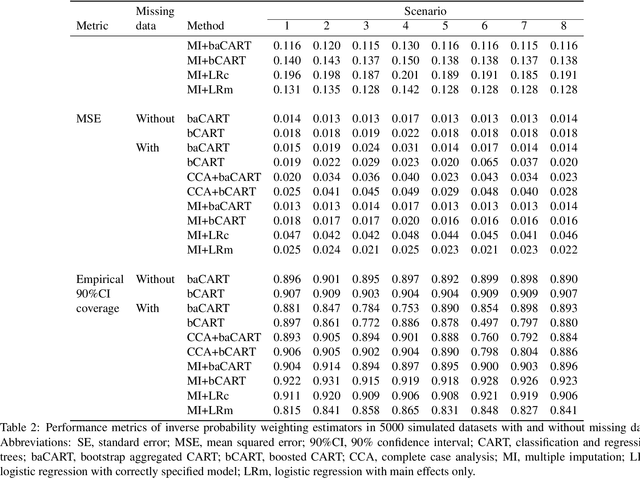
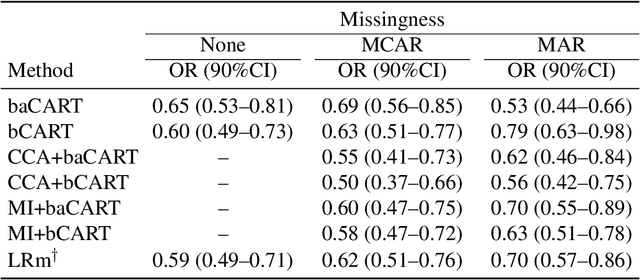
Data mining and machine learning techniques such as classification and regression trees (CART) represent a promising alternative to conventional logistic regression for propensity score estimation. Whereas incomplete data preclude the fitting of a logistic regression on all subjects, CART is appealing in part because some implementations allow for incomplete records to be incorporated in the tree fitting and provide propensity score estimates for all subjects. Based on theoretical considerations, we argue that the automatic handling of missing data by CART may however not be appropriate. Using a series of simulation experiments, we examined the performance of different approaches to handling missing covariate data; (i) applying the CART algorithm directly to the (partially) incomplete data, (ii) complete case analysis, and (iii) multiple imputation. Performance was assessed in terms of bias in estimating exposure-outcome effects \add{among the exposed}, standard error, mean squared error and coverage. Applying the CART algorithm directly to incomplete data resulted in bias, even in scenarios where data were missing completely at random. Overall, multiple imputation followed by CART resulted in the best performance. Our study showed that automatic handling of missing data in CART can cause serious bias and does not outperform multiple imputation as a means to account for missing data.