 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropensity score estimation using classification and regression trees in the presence of missing covariate data
Jul 25, 2018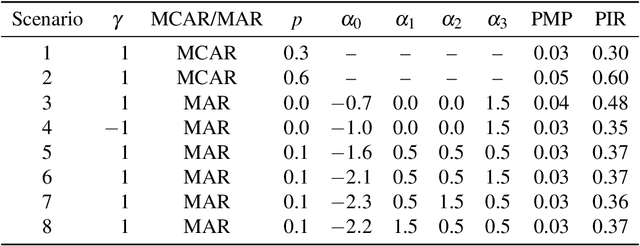
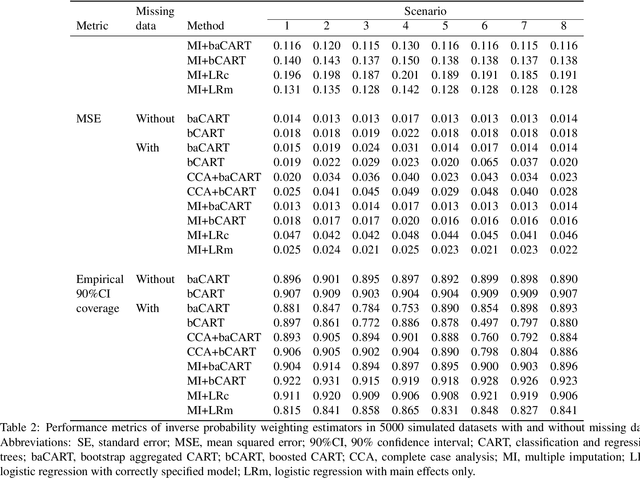
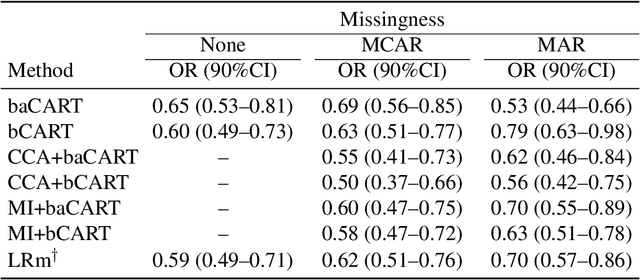
Data mining and machine learning techniques such as classification and regression trees (CART) represent a promising alternative to conventional logistic regression for propensity score estimation. Whereas incomplete data preclude the fitting of a logistic regression on all subjects, CART is appealing in part because some implementations allow for incomplete records to be incorporated in the tree fitting and provide propensity score estimates for all subjects. Based on theoretical considerations, we argue that the automatic handling of missing data by CART may however not be appropriate. Using a series of simulation experiments, we examined the performance of different approaches to handling missing covariate data; (i) applying the CART algorithm directly to the (partially) incomplete data, (ii) complete case analysis, and (iii) multiple imputation. Performance was assessed in terms of bias in estimating exposure-outcome effects \add{among the exposed}, standard error, mean squared error and coverage. Applying the CART algorithm directly to incomplete data resulted in bias, even in scenarios where data were missing completely at random. Overall, multiple imputation followed by CART resulted in the best performance. Our study showed that automatic handling of missing data in CART can cause serious bias and does not outperform multiple imputation as a means to account for missing data.