 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Evaluating Knowledge or Phrasing? Mitigating MCQA Sensitivity with ParaEval
Jun 09, 2026Multiple-choice (MCQA) benchmarks are the standard for evaluating pretrained large language models, but their reliance on log-likelihood scoring makes them unreliable. Specifically, standard scores are highly sensitive to the exact phrasing (surface form) of the answers, conflating a model's familiarity with a specific phrase with its actual capability. We demonstrate this flaw using a controlled testbed of 1B-8B models trained on the same knowledge. Despite having identical knowledge, standard metrics falsely report a performance gap of over 2 points. To solve this, we propose ParaEval, an evaluation framework that queries models using multiple paraphrases per answer option. By scoring each model based on its most favorable phrasing, ParaEval successfully reduces the false performance gap to below 1 point. We confirm that these evaluation artifacts, and the improvements from ParaEval, persist in frontier 70B and 120B open-source models. Ultimately, ParaEval provides a robust and efficient way to evaluate true underlying capability rather than surface-form familiarity.
Omnilingual SONAR: Cross-Lingual and Cross-Modal Sentence Embeddings Bridging Massively Multilingual Text and Speech
Mar 17, 2026Cross-lingual sentence encoders typically cover only a few hundred languages and often trade downstream quality for stronger alignment, limiting their adoption. We introduce OmniSONAR, a new family of omnilingual, cross-lingual and cross-modal sentence embedding models that natively embed text, speech, code, and mathematical expressions in a single semantic space, while delivering state-of-the-art downstream performance at the scale of thousands of languages, from high-resource to extremely low-resource varieties. To reach this scale without representation collapse, we use progressive training. We first learn a strong foundational space for 200 languages with an LLM-initialized encoder-decoder, combining token-level decoding with a novel split-softmax contrastive loss and synthetic hard negatives. Building on this foundation, we expand to several thousands language varieties via a two-stage teacher-student encoder distillation framework. Finally, we demonstrate the cross-modal extensibility of this space by seamlessly mapping 177 spoken languages into it. OmniSONAR halves cross-lingual similarity search error on the 200-language FLORES dataset and reduces error by a factor of 15 on the 1,560-language BIBLE benchmark. It also enables strong translation, outperforming NLLB-3B on multilingual benchmarks and exceeding prior models (including much larger LLMs) by 15 chrF++ points on 1,560 languages into English BIBLE translation. OmniSONAR also performs strongly on MTEB and XLCoST. For speech, OmniSONAR achieves a 43% lower similarity-search error and reaches 97% of SeamlessM4T speech-to-text quality, despite being zero-shot for translation (trained only on ASR data). Finally, by training an encoder-decoder LM, Spectrum, exclusively on English text processing OmniSONAR embedding sequences, we unlock high-performance transfer to thousands of languages and speech for complex downstream tasks.
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
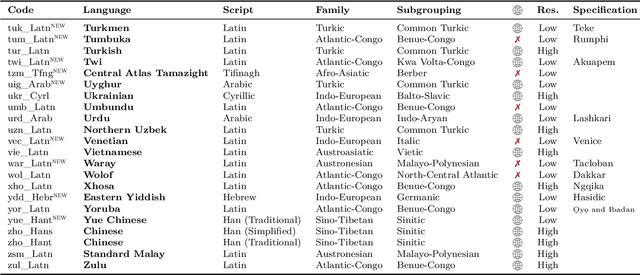
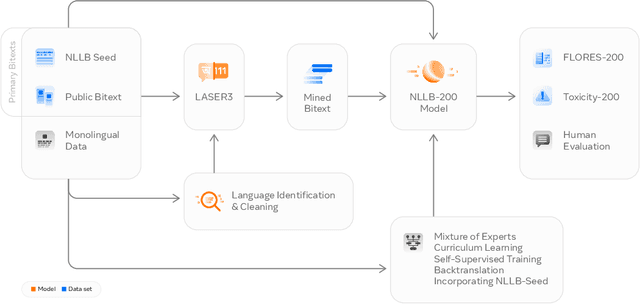
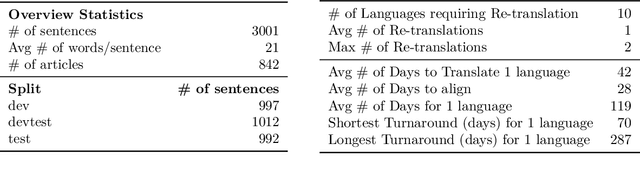
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
Bayesian Active Learning with Pretrained Language Models
Apr 16, 2021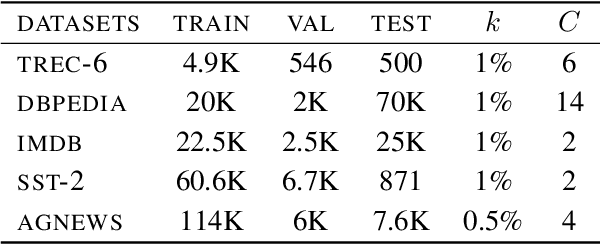
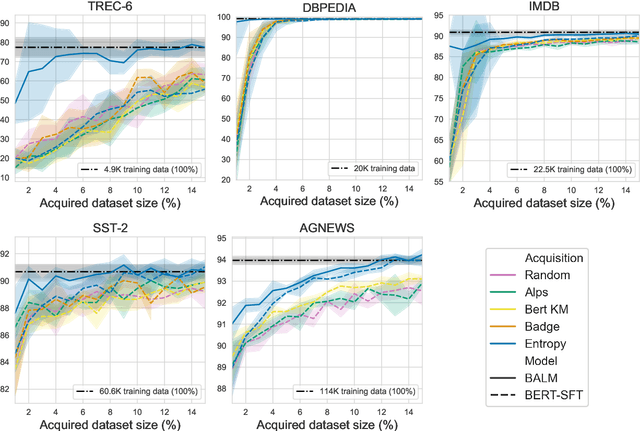
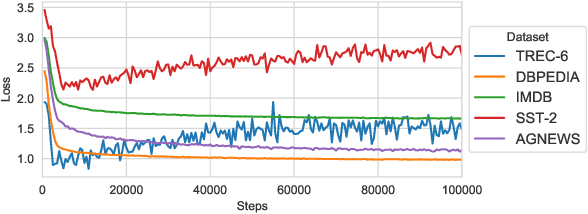
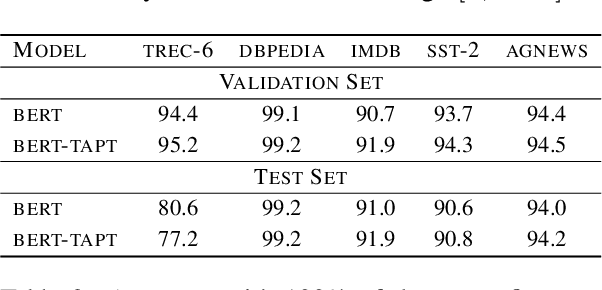
Active Learning (AL) is a method to iteratively select data for annotation from a pool of unlabeled data, aiming to achieve better model performance than random selection. Previous AL approaches in Natural Language Processing (NLP) have been limited to either task-specific models that are trained from scratch at each iteration using only the labeled data at hand or using off-the-shelf pretrained language models (LMs) that are not adapted effectively to the downstream task. In this paper, we address these limitations by introducing BALM; Bayesian Active Learning with pretrained language Models. We first propose to adapt the pretrained LM to the downstream task by continuing training with all the available unlabeled data and then use it for AL. We also suggest a simple yet effective fine-tuning method to ensure that the adapted LM is properly trained in both low and high resource scenarios during AL. We finally apply Monte Carlo dropout to the downstream model to obtain well-calibrated confidence scores for data selection with uncertainty sampling. Our experiments in five standard natural language understanding tasks demonstrate that BALM provides substantial data efficiency improvements compared to various combinations of acquisition functions, models and fine-tuning methods proposed in recent AL literature.
Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
Jul 08, 2018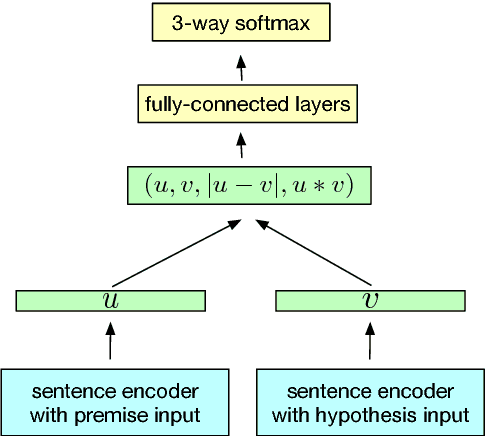

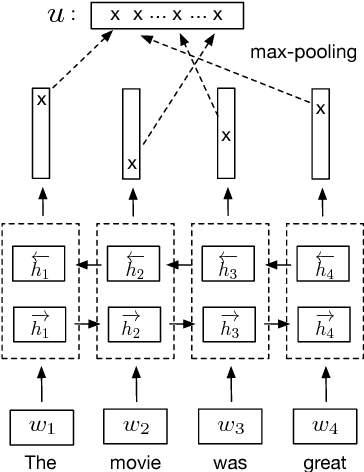

Many modern NLP systems rely on word embeddings, previously trained in an unsupervised manner on large corpora, as base features. Efforts to obtain embeddings for larger chunks of text, such as sentences, have however not been so successful. Several attempts at learning unsupervised representations of sentences have not reached satisfactory enough performance to be widely adopted. In this paper, we show how universal sentence representations trained using the supervised data of the Stanford Natural Language Inference datasets can consistently outperform unsupervised methods like SkipThought vectors on a wide range of transfer tasks. Much like how computer vision uses ImageNet to obtain features, which can then be transferred to other tasks, our work tends to indicate the suitability of natural language inference for transfer learning to other NLP tasks. Our encoder is publicly available.
Incremental Adaptation Strategies for Neural Network Language Models
Jul 07, 2015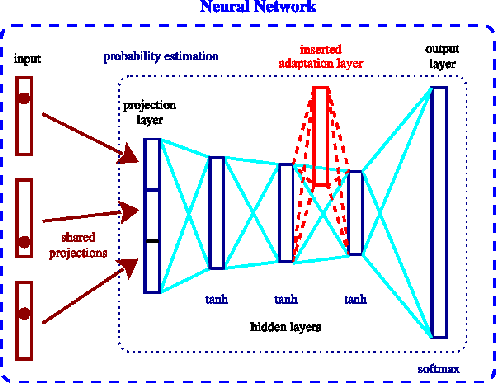


It is today acknowledged that neural network language models outperform backoff language models in applications like speech recognition or statistical machine translation. However, training these models on large amounts of data can take several days. We present efficient techniques to adapt a neural network language model to new data. Instead of training a completely new model or relying on mixture approaches, we propose two new methods: continued training on resampled data or insertion of adaptation layers. We present experimental results in an CAT environment where the post-edits of professional translators are used to improve an SMT system. Both methods are very fast and achieve significant improvements without overfitting the small adaptation data.
On Using Monolingual Corpora in Neural Machine Translation
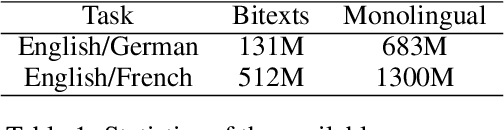
Jun 12, 2015

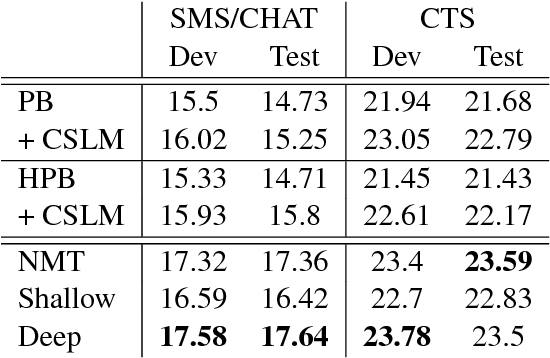
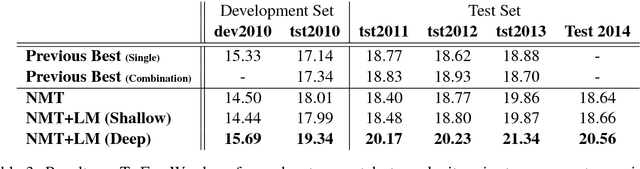
Recent work on end-to-end neural network-based architectures for machine translation has shown promising results for En-Fr and En-De translation. Arguably, one of the major factors behind this success has been the availability of high quality parallel corpora. In this work, we investigate how to leverage abundant monolingual corpora for neural machine translation. Compared to a phrase-based and hierarchical baseline, we obtain up to $1.96$ BLEU improvement on the low-resource language pair Turkish-English, and $1.59$ BLEU on the focused domain task of Chinese-English chat messages. While our method was initially targeted toward such tasks with less parallel data, we show that it also extends to high resource languages such as Cs-En and De-En where we obtain an improvement of $0.39$ and $0.47$ BLEU scores over the neural machine translation baselines, respectively.