 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Active Learning with Pretrained Language Models
Paper and Code
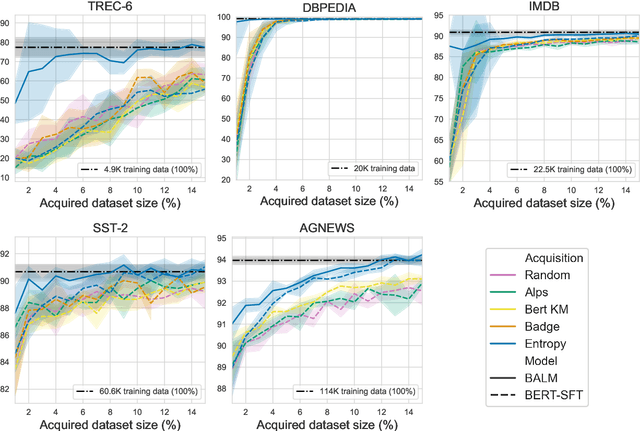
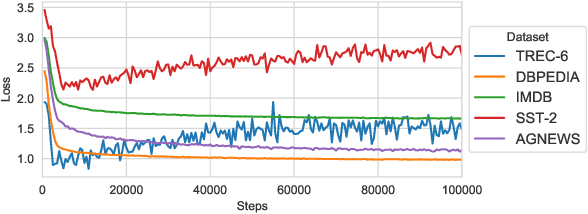
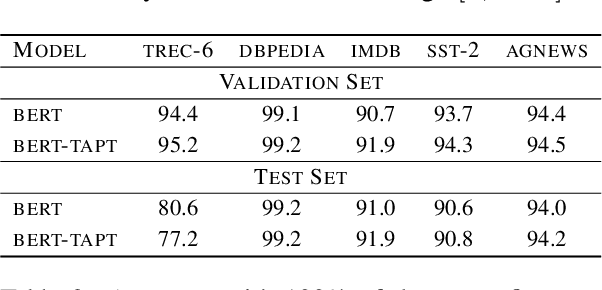
Active Learning (AL) is a method to iteratively select data for annotation from a pool of unlabeled data, aiming to achieve better model performance than random selection. Previous AL approaches in Natural Language Processing (NLP) have been limited to either task-specific models that are trained from scratch at each iteration using only the labeled data at hand or using off-the-shelf pretrained language models (LMs) that are not adapted effectively to the downstream task. In this paper, we address these limitations by introducing BALM; Bayesian Active Learning with pretrained language Models. We first propose to adapt the pretrained LM to the downstream task by continuing training with all the available unlabeled data and then use it for AL. We also suggest a simple yet effective fine-tuning method to ensure that the adapted LM is properly trained in both low and high resource scenarios during AL. We finally apply Monte Carlo dropout to the downstream model to obtain well-calibrated confidence scores for data selection with uncertainty sampling. Our experiments in five standard natural language understanding tasks demonstrate that BALM provides substantial data efficiency improvements compared to various combinations of acquisition functions, models and fine-tuning methods proposed in recent AL literature.