 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Really Learn to Translate a Low-Resource Language from One Grammar Book?
Sep 27, 2024Extremely low-resource (XLR) languages lack substantial corpora for training NLP models, motivating the use of all available resources such as dictionaries and grammar books. Machine Translation from One Book (Tanzer et al., 2024) suggests prompting long-context LLMs with one grammar book enables English-Kalamang translation, an unseen XLR language - a noteworthy case of linguistic knowledge helping an NLP task. We investigate whether the book's grammatical explanations or its parallel examples are most effective for learning XLR translation, finding almost all improvement stems from the parallel examples. Further, we find similar results for Nepali, a seen low-resource language, and achieve performance comparable to an LLM with a grammar book by simply fine-tuning an encoder-decoder translation model. We then investigate where grammar books help by testing two linguistic tasks, grammaticality judgment and gloss prediction, and we explore what kind of grammatical knowledge helps by introducing a typological feature prompt that achieves leading results on these more relevant tasks. We thus emphasise the importance of task-appropriate data for XLR languages: parallel examples for translation, and grammatical data for linguistic tasks. As we find no evidence that long-context LLMs can make effective use of grammatical explanations for XLR translation, we suggest data collection for multilingual XLR tasks such as translation is best focused on parallel data over linguistic description.
Modeling Latent Sentence Structure in Neural Machine Translation
Jan 18, 2019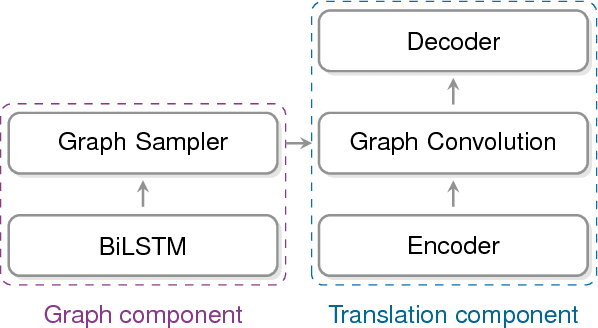
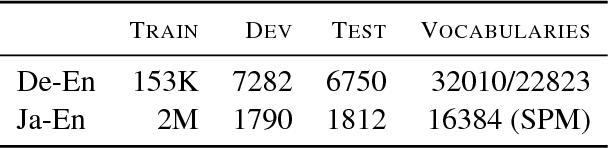
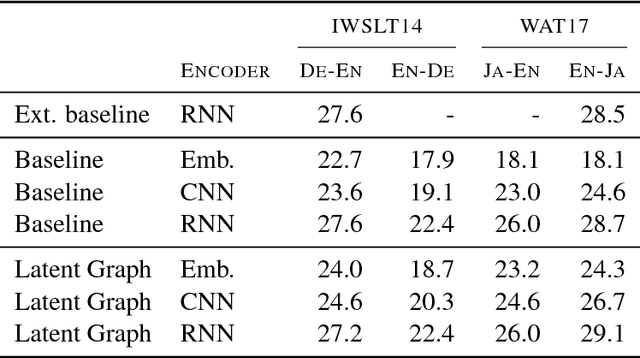
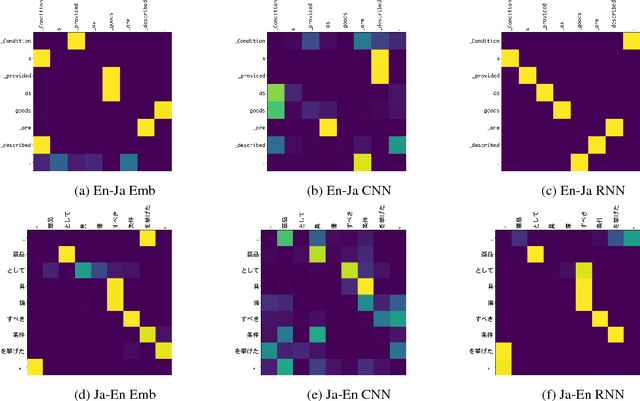
Recently it was shown that linguistic structure predicted by a supervised parser can be beneficial for neural machine translation (NMT). In this work we investigate a more challenging setup: we incorporate sentence structure as a latent variable in a standard NMT encoder-decoder and induce it in such a way as to benefit the translation task. We consider German-English and Japanese-English translation benchmarks and observe that when using RNN encoders the model makes no or very limited use of the structure induction apparatus. In contrast, CNN and word-embedding-based encoders rely on latent graphs and force them to encode useful, potentially long-distance, dependencies.
Deep Generative Model for Joint Alignment and Word Representation
Apr 23, 2018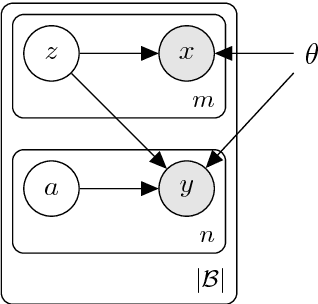



This work exploits translation data as a source of semantically relevant learning signal for models of word representation. In particular, we exploit equivalence through translation as a form of distributed context and jointly learn how to embed and align with a deep generative model. Our EmbedAlign model embeds words in their complete observed context and learns by marginalisation of latent lexical alignments. Besides, it embeds words as posterior probability densities, rather than point estimates, which allows us to compare words in context using a measure of overlap between distributions (e.g. KL divergence). We investigate our model's performance on a range of lexical semantics tasks achieving competitive results on several standard benchmarks including natural language inference, paraphrasing, and text similarity.
Multi30K: Multilingual English-German Image Descriptions
May 02, 2016


We introduce the Multi30K dataset to stimulate multilingual multimodal research. Recent advances in image description have been demonstrated on English-language datasets almost exclusively, but image description should not be limited to English. This dataset extends the Flickr30K dataset with i) German translations created by professional translators over a subset of the English descriptions, and ii) descriptions crowdsourced independently of the original English descriptions. We outline how the data can be used for multilingual image description and multimodal machine translation, but we anticipate the data will be useful for a broader range of tasks.
Tree-gram Parsing: Lexical Dependencies and Structural Relations
Nov 06, 2000



This paper explores the kinds of probabilistic relations that are important in syntactic disambiguation. It proposes that two widely used kinds of relations, lexical dependencies and structural relations, have complementary disambiguation capabilities. It presents a new model based on structural relations, the Tree-gram model, and reports experiments showing that structural relations should benefit from enrichment by lexical dependencies.
Evaluation of the NLP Components of the OVIS2 Spoken Dialogue System
Jun 14, 1999
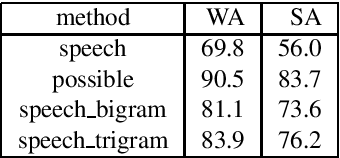
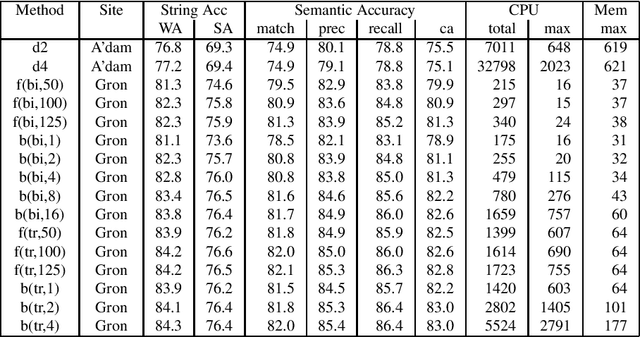
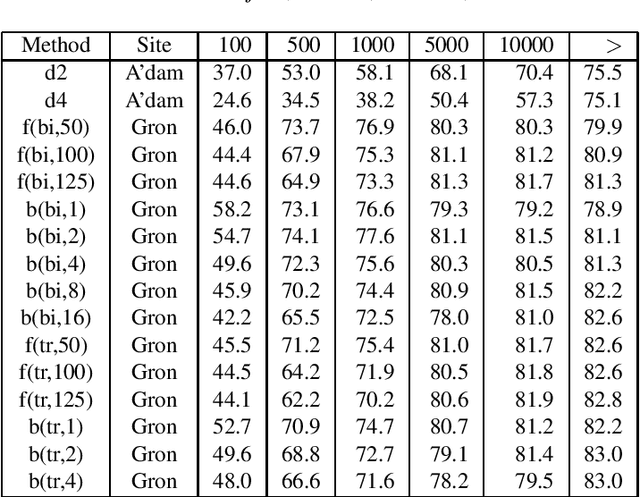
The NWO Priority Programme Language and Speech Technology is a 5-year research programme aiming at the development of spoken language information systems. In the Programme, two alternative natural language processing (NLP) modules are developed in parallel: a grammar-based (conventional, rule-based) module and a data-oriented (memory-based, stochastic, DOP) module. In order to compare the NLP modules, a formal evaluation has been carried out three years after the start of the Programme. This paper describes the evaluation procedure and the evaluation results. The grammar-based component performs much better than the data-oriented one in this comparison.
Learning Efficient Disambiguation
Jun 03, 1999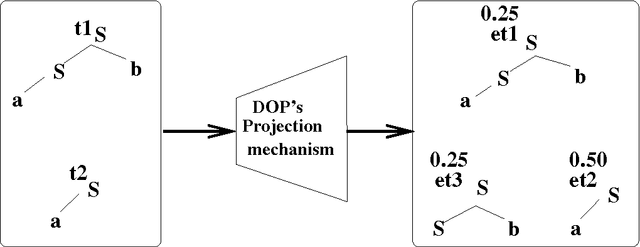
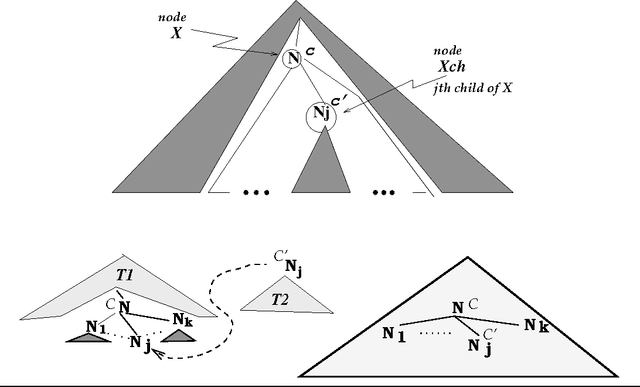

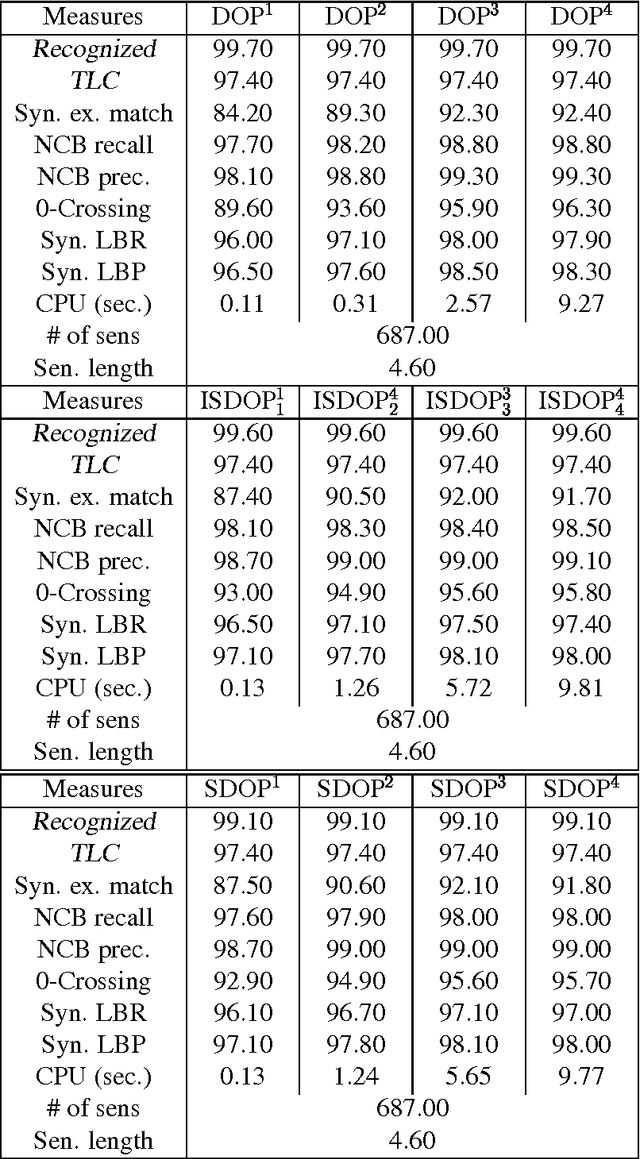
This dissertation analyses the computational properties of current performance-models of natural language parsing, in particular Data Oriented Parsing (DOP), points out some of their major shortcomings and suggests suitable solutions. It provides proofs that various problems of probabilistic disambiguation are NP-Complete under instances of these performance-models, and it argues that none of these models accounts for attractive efficiency properties of human language processing in limited domains, e.g. that frequent inputs are usually processed faster than infrequent ones. The central hypothesis of this dissertation is that these shortcomings can be eliminated by specializing the performance-models to the limited domains. The dissertation addresses "grammar and model specialization" and presents a new framework, the Ambiguity-Reduction Specialization (ARS) framework, that formulates the necessary and sufficient conditions for successful specialization. The framework is instantiated into specialization algorithms and applied to specializing DOP. Novelties of these learning algorithms are 1) they limit the hypotheses-space to include only "safe" models, 2) are expressed as constrained optimization formulae that minimize the entropy of the training tree-bank given the specialized grammar, under the constraint that the size of the specialized model does not exceed a predefined maximum, and 3) they enable integrating the specialized model with the original one in a complementary manner. The dissertation provides experiments with initial implementations and compares the resulting Specialized DOP (SDOP) models to the original DOP models with encouraging results.
explanation-based learning of data oriented parsing
Aug 20, 1997

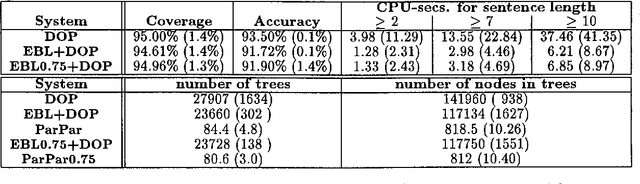

This paper presents a new view of Explanation-Based Learning (EBL) of natural language parsing. Rather than employing EBL for specializing parsers by inferring new ones, this paper suggests employing EBL for learning how to reduce ambiguity only partially. The present method consists of an EBL algorithm for learning partial-parsers, and a parsing algorithm which combines partial-parsers with existing ``full-parsers". The learned partial-parsers, implementable as Cascades of Finite State Transducers (CFSTs), recognize and combine constituents efficiently, prohibiting spurious overgeneration. The parsing algorithm combines a learned partial-parser with a given full-parser such that the role of the full-parser is limited to combining the constituents, recognized by the partial-parser, and to recognizing unrecognized portions of the input sentence. Besides the reduction of the parse-space prior to disambiguation, the present method provides a way for refining existing disambiguation models that learn stochastic grammars from tree-banks. We exhibit encouraging empirical results using a pilot implementation: parse-space is reduced substantially with minimal loss of coverage. The speedup gain for disambiguation models is exemplified by experiments with the DOP model.
Computational Complexity of Probabilistic Disambiguation by means of Tree-Grammars
Jun 17, 1996This paper studies the computational complexity of disambiguation under probabilistic tree-grammars and context-free grammars. It presents a proof that the following problems are NP-hard: computing the Most Probable Parse (MPP) from a sentence or from a word-graph, and computing the Most Probable Sentence (MPS) from a word-graph. The NP-hardness of computing the MPS from a word-graph also holds for Stochastic Context-Free Grammars. Consequently, the existence of deterministic polynomial-time algorithms for solving these disambiguation problems is a highly improbable event.