 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Efficient Disambiguation
Paper and Code
Jun 03, 1999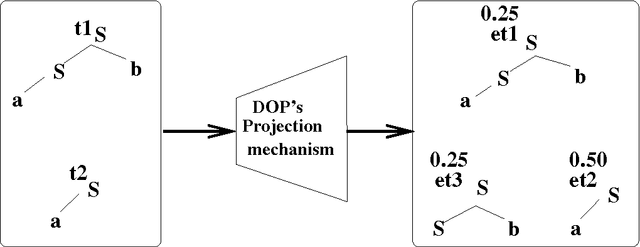
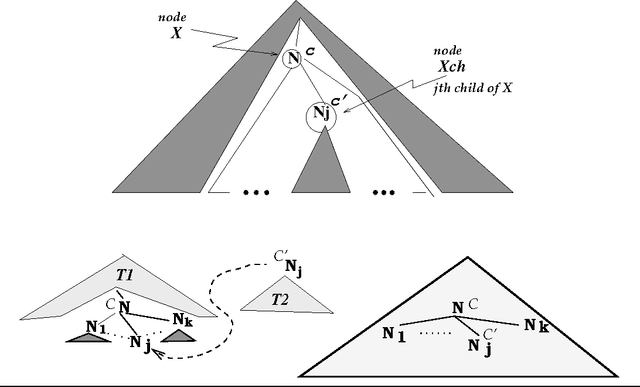

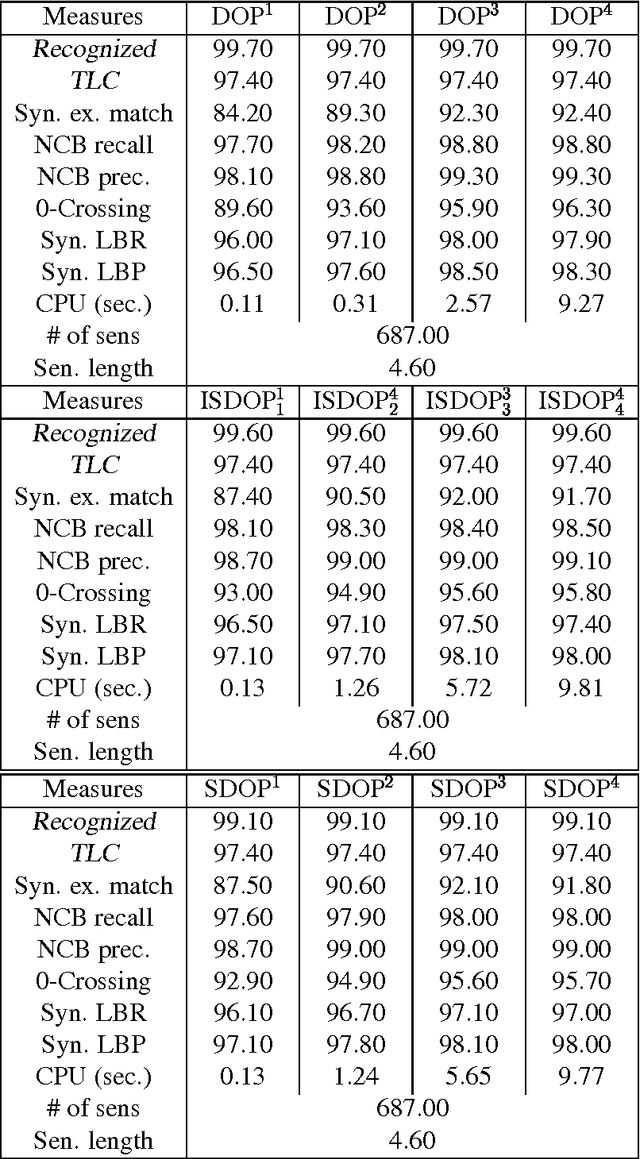
This dissertation analyses the computational properties of current performance-models of natural language parsing, in particular Data Oriented Parsing (DOP), points out some of their major shortcomings and suggests suitable solutions. It provides proofs that various problems of probabilistic disambiguation are NP-Complete under instances of these performance-models, and it argues that none of these models accounts for attractive efficiency properties of human language processing in limited domains, e.g. that frequent inputs are usually processed faster than infrequent ones. The central hypothesis of this dissertation is that these shortcomings can be eliminated by specializing the performance-models to the limited domains. The dissertation addresses "grammar and model specialization" and presents a new framework, the Ambiguity-Reduction Specialization (ARS) framework, that formulates the necessary and sufficient conditions for successful specialization. The framework is instantiated into specialization algorithms and applied to specializing DOP. Novelties of these learning algorithms are 1) they limit the hypotheses-space to include only "safe" models, 2) are expressed as constrained optimization formulae that minimize the entropy of the training tree-bank given the specialized grammar, under the constraint that the size of the specialized model does not exceed a predefined maximum, and 3) they enable integrating the specialized model with the original one in a complementary manner. The dissertation provides experiments with initial implementations and compares the resulting Specialized DOP (SDOP) models to the original DOP models with encouraging results.