Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Latent Sentence Structure in Neural Machine Translation
Paper and Code
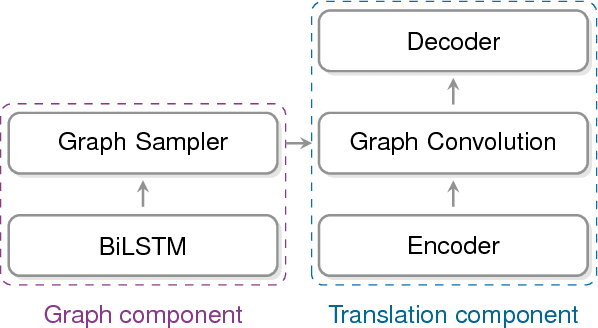
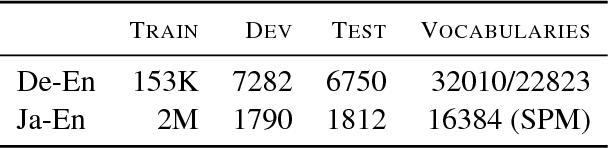
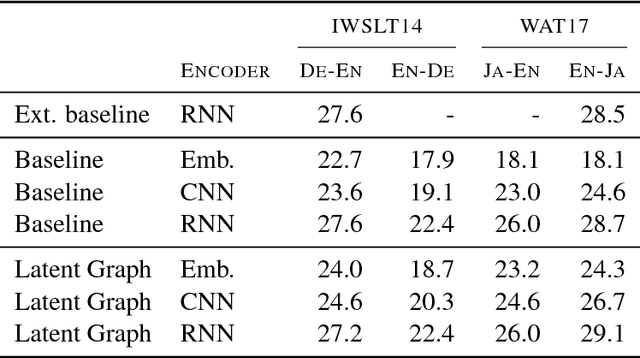
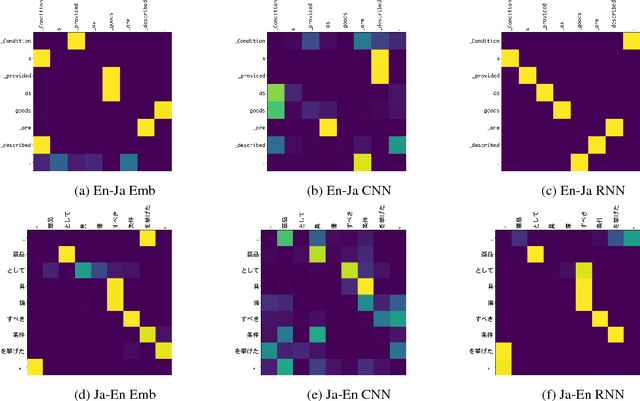
Recently it was shown that linguistic structure predicted by a supervised parser can be beneficial for neural machine translation (NMT). In this work we investigate a more challenging setup: we incorporate sentence structure as a latent variable in a standard NMT encoder-decoder and induce it in such a way as to benefit the translation task. We consider German-English and Japanese-English translation benchmarks and observe that when using RNN encoders the model makes no or very limited use of the structure induction apparatus. In contrast, CNN and word-embedding-based encoders rely on latent graphs and force them to encode useful, potentially long-distance, dependencies.
* Accepted as an extended abstract to ACL NMT workshop 2018
View paper on