 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Differentiable Causal Discovery
Nov 17, 2023Inferring causal relationships as directed acyclic graphs (DAGs) is an important but challenging problem. Differentiable Causal Discovery (DCD) is a promising approach to this problem, framing the search as a continuous optimization. But existing DCD methods are numerically unstable, with poor performance beyond tens of variables. In this paper, we propose Stable Differentiable Causal Discovery (SDCD), a new method that improves previous DCD methods in two ways: (1) It employs an alternative constraint for acyclicity; this constraint is more stable, both theoretically and empirically, and fast to compute. (2) It uses a training procedure tailored for sparse causal graphs, which are common in real-world scenarios. We first derive SDCD and prove its stability and correctness. We then evaluate it with both observational and interventional data and on both small-scale and large-scale settings. We find that SDCD outperforms existing methods in both convergence speed and accuracy and can scale to thousands of variables.
The CausalBench challenge: A machine learning contest for gene network inference from single-cell perturbation data
Aug 29, 2023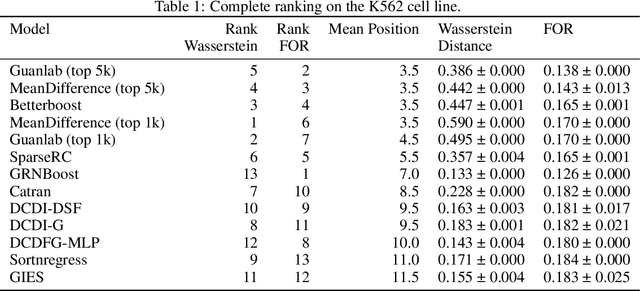
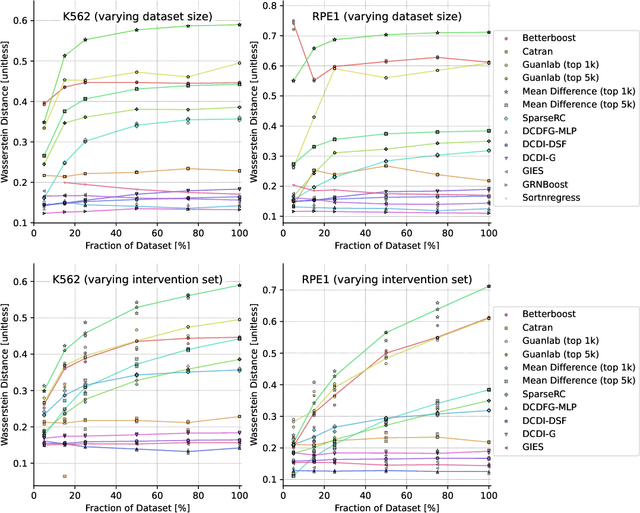
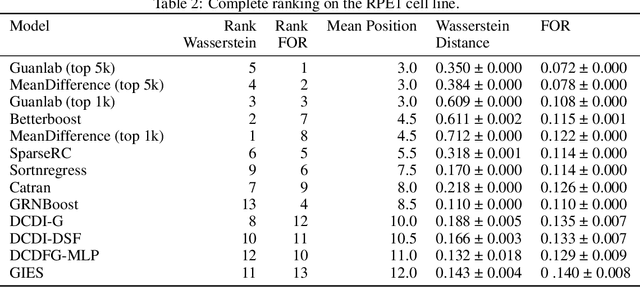
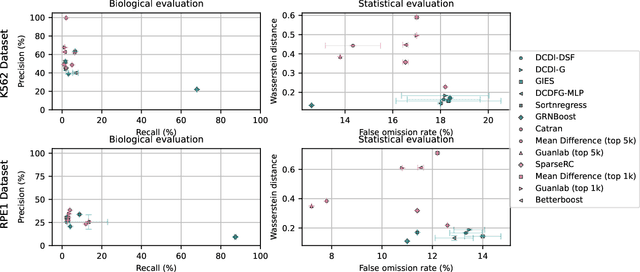
In drug discovery, mapping interactions between genes within cellular systems is a crucial early step. This helps formulate hypotheses regarding molecular mechanisms that could potentially be targeted by future medicines. The CausalBench Challenge was an initiative to invite the machine learning community to advance the state of the art in constructing gene-gene interaction networks. These networks, derived from large-scale, real-world datasets of single cells under various perturbations, are crucial for understanding the causal mechanisms underlying disease biology. Using the framework provided by the CausalBench benchmark, participants were tasked with enhancing the capacity of the state of the art methods to leverage large-scale genetic perturbation data. This report provides an analysis and summary of the methods submitted during the challenge to give a partial image of the state of the art at the time of the challenge. The winning solutions significantly improved performance compared to previous baselines, establishing a new state of the art for this critical task in biology and medicine.
Towards ML Engineering: A Brief History Of TensorFlow Extended
Oct 07, 2020Software Engineering, as a discipline, has matured over the past 5+ decades. The modern world heavily depends on it, so the increased maturity of Software Engineering was an eventuality. Practices like testing and reliable technologies help make Software Engineering reliable enough to build industries upon. Meanwhile, Machine Learning (ML) has also grown over the past 2+ decades. ML is used more and more for research, experimentation and production workloads. ML now commonly powers widely-used products integral to our lives. But ML Engineering, as a discipline, has not widely matured as much as its Software Engineering ancestor. Can we take what we have learned and help the nascent field of applied ML evolve into ML Engineering the way Programming evolved into Software Engineering [1]? In this article we will give a whirlwind tour of Sibyl [2] and TensorFlow Extended (TFX) [3], two successive end-to-end (E2E) ML platforms at Alphabet. We will share the lessons learned from over a decade of applied ML built on these platforms, explain both their similarities and their differences, and expand on the shifts (both mental and technical) that helped us on our journey. In addition, we will highlight some of the capabilities of TFX that help realize several aspects of ML Engineering. We argue that in order to unlock the gains ML can bring, organizations should advance the maturity of their ML teams by investing in robust ML infrastructure and promoting ML Engineering education. We also recommend that before focusing on cutting-edge ML modeling techniques, product leaders should invest more time in adopting interoperable ML platforms for their organizations. In closing, we will also share a glimpse into the future of TFX.
Robust Federated Learning in a Heterogeneous Environment
Jun 16, 2019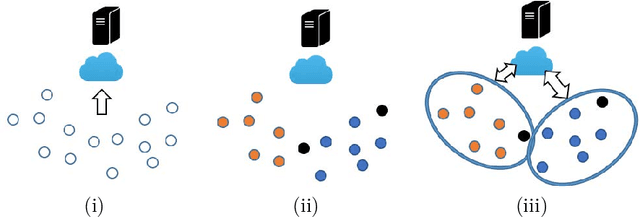
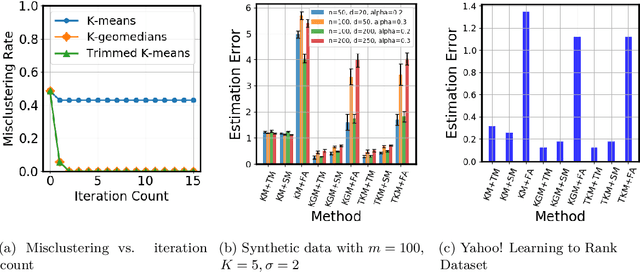
We study a recently proposed large-scale distributed learning paradigm, namely Federated Learning, where the worker machines are end users' own devices. Statistical and computational challenges arise in Federated Learning particularly in the presence of heterogeneous data distribution (i.e., data points on different devices belong to different distributions signifying different clusters) and Byzantine machines (i.e., machines that may behave abnormally, or even exhibit arbitrary and potentially adversarial behavior). To address the aforementioned challenges, first we propose a general statistical model for this problem which takes both the cluster structure of the users and the Byzantine machines into account. Then, leveraging the statistical model, we solve the robust heterogeneous Federated Learning problem \emph{optimally}; in particular our algorithm matches the lower bound on the estimation error in dimension and the number of data points. Furthermore, as a by-product, we prove statistical guarantees for an outlier-robust clustering algorithm, which can be considered as the Lloyd algorithm with robust estimation. Finally, we show via synthetic as well as real data experiments that the estimation error obtained by our proposed algorithm is significantly better than the non-Byzantine-robust algorithms; in particular, we gain at least by 53\% and 33\% for synthetic and real data experiments, respectively, in typical settings.