 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Federated Learning in a Heterogeneous Environment
Paper and Code
Jun 16, 2019
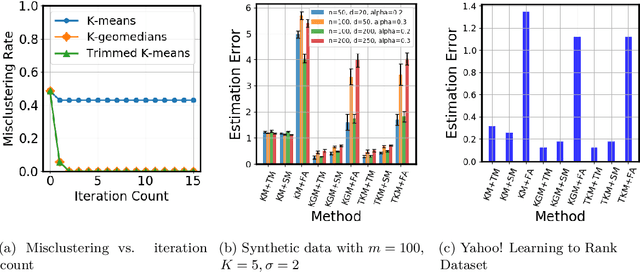
We study a recently proposed large-scale distributed learning paradigm, namely Federated Learning, where the worker machines are end users' own devices. Statistical and computational challenges arise in Federated Learning particularly in the presence of heterogeneous data distribution (i.e., data points on different devices belong to different distributions signifying different clusters) and Byzantine machines (i.e., machines that may behave abnormally, or even exhibit arbitrary and potentially adversarial behavior). To address the aforementioned challenges, first we propose a general statistical model for this problem which takes both the cluster structure of the users and the Byzantine machines into account. Then, leveraging the statistical model, we solve the robust heterogeneous Federated Learning problem \emph{optimally}; in particular our algorithm matches the lower bound on the estimation error in dimension and the number of data points. Furthermore, as a by-product, we prove statistical guarantees for an outlier-robust clustering algorithm, which can be considered as the Lloyd algorithm with robust estimation. Finally, we show via synthetic as well as real data experiments that the estimation error obtained by our proposed algorithm is significantly better than the non-Byzantine-robust algorithms; in particular, we gain at least by 53\% and 33\% for synthetic and real data experiments, respectively, in typical settings.