 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Research on Fitness Function of Tow Evolution Algorithms Using for Neutron Spectrum Unfolding
Jul 30, 2020

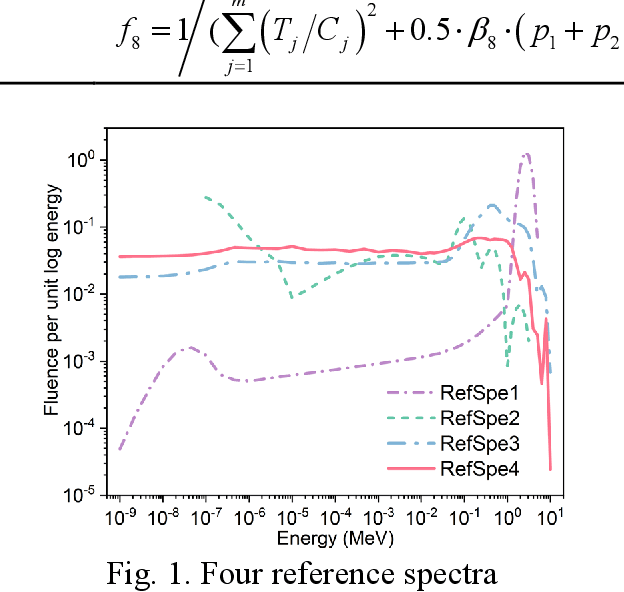

Using evolution algorithms to unfold the neutron energy spectrum, fitness function design is an important fundamental work for evaluating the quality of solution, but it has not attracted much attention. In this work, we investigated the performance of 8 fitness functions attached to genetic algorithm (GA) and differential evolution algorithm (DEA) used for unfolding four neutron spectra of IAEA 403 report. Experiments show that the fitness functions with a maximum in GA can limit the ability of population to percept the fitness change but the ability can be made up in DEA, and the fitness function with a feature penalty item help to improve the performance of solutions, and the fitness function using the standard deviation and the Chi-Squared shows the balance between algorithm and spectra. The results also show that the DEA has good potential for neutron energy spectrum unfolding. The purpose of this work is to provide evidence for structuring and modifying the fitness functions, and some genetic operations that should be paid attention were suggested for using the fitness function to unfold neutron spectra.
Diabetic Retinopathy Detection via Deep Convolutional Networks for Discriminative Localization and Visual Explanation
Apr 03, 2017



We proposed a deep learning method for interpretable diabetic retinopathy (DR) detection. The visual-interpretable feature of the proposed method is achieved by adding the regression activation map (RAM) after the global averaging pooling layer of the convolutional networks (CNN). With RAM, the proposed model can localize the discriminative regions of an retina image to show the specific region of interest in terms of its severity level. We believe this advantage of the proposed deep learning model is highly desired for DR detection because in practice, users are not only interested with high prediction performance, but also keen to understand the insights of DR detection and why the adopted learning model works. In the experiments conducted on a large scale of retina image dataset, we show that the proposed CNN model can achieve high performance on DR detection compared with the state-of-the-art while achieving the merits of providing the RAM to highlight the salient regions of the input image.
Classification and Reconstruction of High-Dimensional Signals from Low-Dimensional Features in the Presence of Side Information
Mar 17, 2016



This paper offers a characterization of fundamental limits on the classification and reconstruction of high-dimensional signals from low-dimensional features, in the presence of side information. We consider a scenario where a decoder has access both to linear features of the signal of interest and to linear features of the side information signal; while the side information may be in a compressed form, the objective is recovery or classification of the primary signal, not the side information. The signal of interest and the side information are each assumed to have (distinct) latent discrete labels; conditioned on these two labels, the signal of interest and side information are drawn from a multivariate Gaussian distribution. With joint probabilities on the latent labels, the overall signal-(side information) representation is defined by a Gaussian mixture model. We then provide sharp sufficient and/or necessary conditions for these quantities to approach zero when the covariance matrices of the Gaussians are nearly low-rank. These conditions, which are reminiscent of the well-known Slepian-Wolf and Wyner-Ziv conditions, are a function of the number of linear features extracted from the signal of interest, the number of linear features extracted from the side information signal, and the geometry of these signals and their interplay. Moreover, on assuming that the signal of interest and the side information obey such an approximately low-rank model, we derive expansions of the reconstruction error as a function of the deviation from an exactly low-rank model; such expansions also allow identification of operational regimes where the impact of side information on signal reconstruction is most relevant. Our framework, which offers a principled mechanism to integrate side information in high-dimensional data problems, is also tested in the context of imaging applications.
Low-Cost Compressive Sensing for Color Video and Depth
Feb 27, 2014



A simple and inexpensive (low-power and low-bandwidth) modification is made to a conventional off-the-shelf color video camera, from which we recover {multiple} color frames for each of the original measured frames, and each of the recovered frames can be focused at a different depth. The recovery of multiple frames for each measured frame is made possible via high-speed coding, manifested via translation of a single coded aperture; the inexpensive translation is constituted by mounting the binary code on a piezoelectric device. To simultaneously recover depth information, a {liquid} lens is modulated at high speed, via a variable voltage. Consequently, during the aforementioned coding process, the liquid lens allows the camera to sweep the focus through multiple depths. In addition to designing and implementing the camera, fast recovery is achieved by an anytime algorithm exploiting the group-sparsity of wavelet/DCT coefficients.
Adaptive Temporal Compressive Sensing for Video
Oct 15, 2013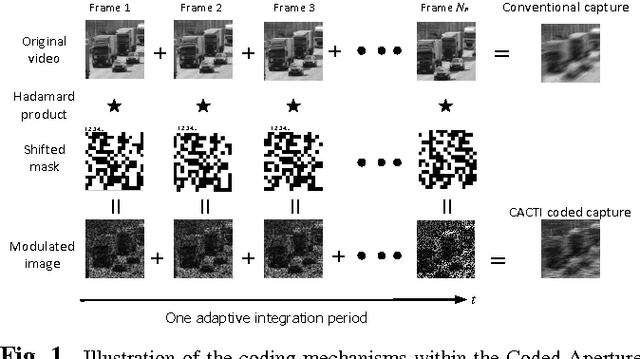
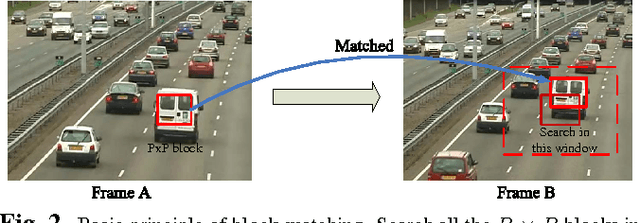


This paper introduces the concept of adaptive temporal compressive sensing (CS) for video. We propose a CS algorithm to adapt the compression ratio based on the scene's temporal complexity, computed from the compressed data, without compromising the quality of the reconstructed video. The temporal adaptivity is manifested by manipulating the integration time of the camera, opening the possibility to real-time implementation. The proposed algorithm is a generalized temporal CS approach that can be incorporated with a diverse set of existing hardware systems.
Coded aperture compressive temporal imaging
Feb 04, 2013


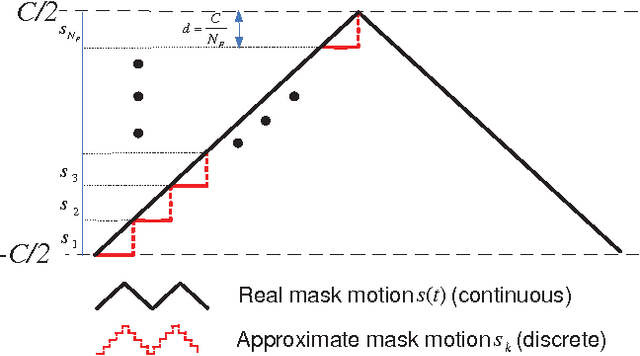
We use mechanical translation of a coded aperture for code division multiple access compression of video. We present experimental results for reconstruction at 148 frames per coded snapshot.