 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoIdeator: Evolving Scientific Ideas through Checklist-Grounded Reinforcement Learning
Mar 23, 2026Scientific idea generation is a cornerstone of autonomous knowledge discovery, yet the iterative evolution required to transform initial concepts into high-quality research proposals remains a formidable challenge for Large Language Models (LLMs). Existing Reinforcement Learning (RL) paradigms often rely on rubric-based scalar rewards that provide global quality scores but lack actionable granularity. Conversely, language-based refinement methods are typically confined to inference-time prompting, targeting models that are not explicitly optimized to internalize such critiques. To bridge this gap, we propose \textbf{EvoIdeator}, a framework that facilitates the evolution of scientific ideas by aligning the RL training objective with \textbf{checklist-grounded feedback}. EvoIdeator leverages a structured judge model to generate two synergistic signals: (1) \emph{lexicographic rewards} for multi-dimensional optimization, and (2) \emph{fine-grained language feedback} that offers span-level critiques regarding grounding, feasibility, and methodological rigor. By integrating these signals into the RL loop, we condition the policy to systematically utilize precise feedback during both optimization and inference. Extensive experiments demonstrate that EvoIdeator, built on Qwen3-4B, significantly outperforms much larger frontier models across key scientific metrics. Crucially, the learned policy exhibits strong generalization to diverse external feedback sources without further fine-tuning, offering a scalable and rigorous path toward self-refining autonomous ideation.
EvoScientist: Towards Multi-Agent Evolving AI Scientists for End-to-End Scientific Discovery
Mar 09, 2026The increasing adoption of Large Language Models (LLMs) has enabled AI scientists to perform complex end-to-end scientific discovery tasks requiring coordination of specialized roles, including idea generation and experimental execution. However, most state-of-the-art AI scientist systems rely on static, hand-designed pipelines and fail to adapt based on accumulated interaction histories. As a result, these systems overlook promising research directions, repeat failed experiments, and pursue infeasible ideas. To address this, we introduce EvoScientist, an evolving multi-agent AI scientist framework that continuously improves research strategies through persistent memory and self-evolution. EvoScientist comprises three specialized agents: a Researcher Agent (RA) for scientific idea generation, an Engineer Agent (EA) for experiment implementation and execution, and an Evolution Manager Agent (EMA) that distills insights from prior interactions into reusable knowledge. EvoScientist contains two persistent memory modules: (i) an ideation memory, which summarizes feasible research directions from top-ranked ideas while recording previously unsuccessful directions; and (ii) an experimentation memory, which captures effective data processing and model training strategies derived from code search trajectories and best-performing implementations. These modules enable the RA and EA to retrieve relevant prior strategies, improving idea quality and code execution success rates over time. Experiments show that EvoScientist outperforms 7 open-source and commercial state-of-the-art systems in scientific idea generation, achieving higher novelty, feasibility, relevance, and clarity via automatic and human evaluation. EvoScientist also substantially improves code execution success rates through multi-agent evolution, demonstrating persistent memory's effectiveness for end-to-end scientific discovery.
Chasing Streams with Existential Rules
May 04, 2022
We study reasoning with existential rules to perform query answering over streams of data. On static databases, this problem has been widely studied, but its extension to rapidly changing data has not yet been considered. To bridge this gap, we extend LARS, a well-known framework for rule-based stream reasoning, to support existential rules. For that, we show how to translate LARS with existentials into a semantics-preserving set of existential rules. As query answering with such rules is undecidable in general, we describe how to leverage the temporal nature of streams and present suitable notions of acyclicity that ensure decidability.
Tribrid: Stance Classification with Neural Inconsistency Detection
Sep 14, 2021
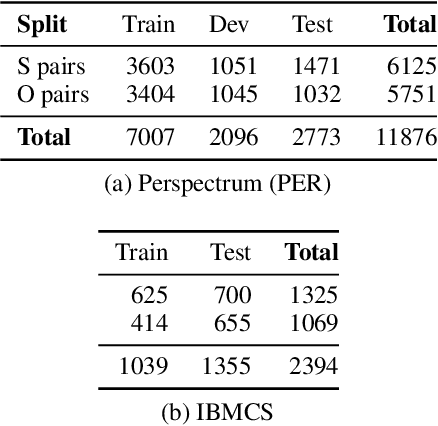

We study the problem of performing automatic stance classification on social media with neural architectures such as BERT. Although these architectures deliver impressive results, their level is not yet comparable to the one of humans and they might produce errors that have a significant impact on the downstream task (e.g., fact-checking). To improve the performance, we present a new neural architecture where the input also includes automatically generated negated perspectives over a given claim. The model is jointly learned to make simultaneously multiple predictions, which can be used either to improve the classification of the original perspective or to filter out doubtful predictions. In the first case, we propose a weakly supervised method for combining the predictions into a final one. In the second case, we show that using the confidence scores to remove doubtful predictions allows our method to achieve human-like performance over the retained information, which is still a sizable part of the original input.
Tab2Know: Building a Knowledge Base from Tables in Scientific Papers
Jul 28, 2021


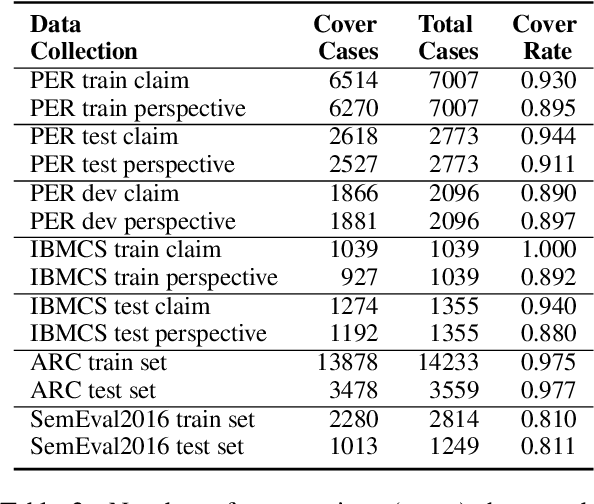
Tables in scientific papers contain a wealth of valuable knowledge for the scientific enterprise. To help the many of us who frequently consult this type of knowledge, we present Tab2Know, a new end-to-end system to build a Knowledge Base (KB) from tables in scientific papers. Tab2Know addresses the challenge of automatically interpreting the tables in papers and of disambiguating the entities that they contain. To solve these problems, we propose a pipeline that employs both statistical-based classifiers and logic-based reasoning. First, our pipeline applies weakly supervised classifiers to recognize the type of tables and columns, with the help of a data labeling system and an ontology specifically designed for our purpose. Then, logic-based reasoning is used to link equivalent entities (via sameAs links) in different tables. An empirical evaluation of our approach using a corpus of papers in the Computer Science domain has returned satisfactory performance. This suggests that ours is a promising step to create a large-scale KB of scientific knowledge.
* 17 pages, 4 figures, conference: The Semantic Web -- ISWC 2020
Materializing Knowledge Bases via Trigger Graphs
Feb 04, 2021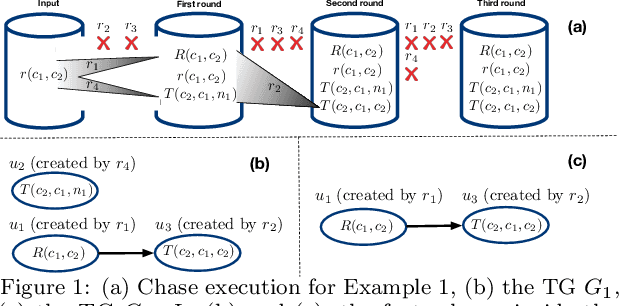
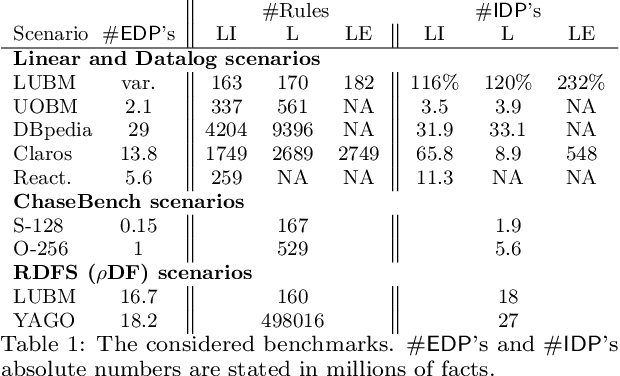
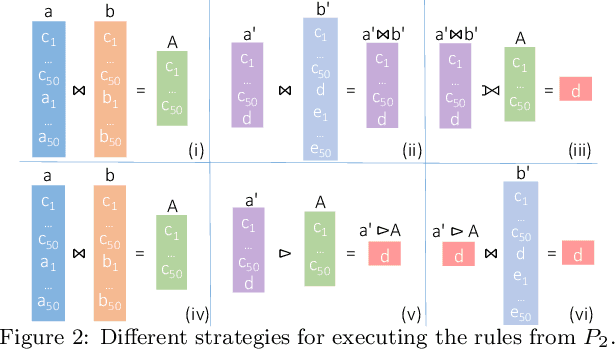
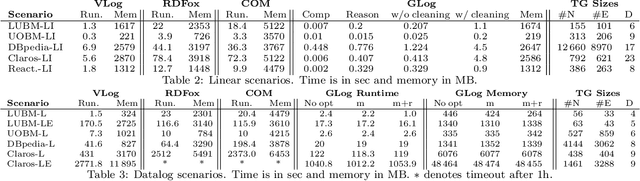
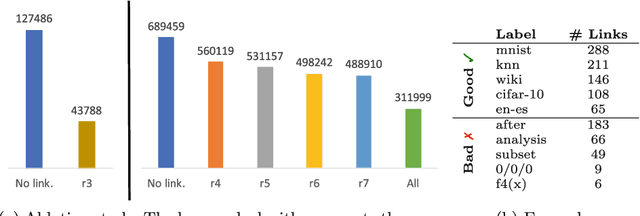
The chase is a well-established family of algorithms used to materialize Knowledge Bases (KBs), like Knowledge Graphs (KGs), to tackle important tasks like query answering under dependencies or data cleaning. A general problem of chase algorithms is that they might perform redundant computations. To counter this problem, we introduce the notion of Trigger Graphs (TGs), which guide the execution of the rules avoiding redundant computations. We present the results of an extensive theoretical and empirical study that seeks to answer when and how TGs can be computed and what are the benefits of TGs when applied over real-world KBs. Our results include introducing algorithms that compute (minimal) TGs. We implemented our approach in a new engine, and our experiments show that it can be significantly more efficient than the chase enabling us to materialize KBs with 17B facts in less than 40 min on commodity machines.
Checking Chase Termination over Ontologies of Existential Rules with Equality
Nov 25, 2019
The chase is a sound and complete algorithm for conjunctive query answering over ontologies of existential rules with equality. To enable its effective use, we can apply acyclicity notions; that is, sufficient conditions that guarantee chase termination. Unfortunately, most of these notions have only been defined for existential rule sets without equality. A proposed solution to circumvent this issue is to treat equality as an ordinary predicate with an explicit axiomatisation. We empirically show that this solution is not efficient in practice and propose an alternative approach. More precisely, we show that, if the chase terminates for any equality axiomatisation of an ontology, then it terminates for the original ontology (which may contain equality). Therefore, one can apply existing acyclicity notions to check chase termination over an axiomatisation of an ontology and then use the original ontology for reasoning. We show that, in practice, doing so results in a more efficient reasoning procedure. Furthermore, we present equality model-faithful acyclicity, a general acyclicity notion that can be directly applied to ontologies with equality.
Datalog Reasoning over Compressed RDF Knowledge Bases
Aug 29, 2019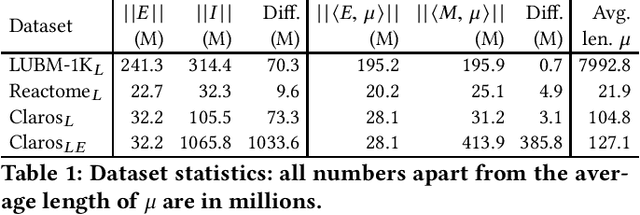
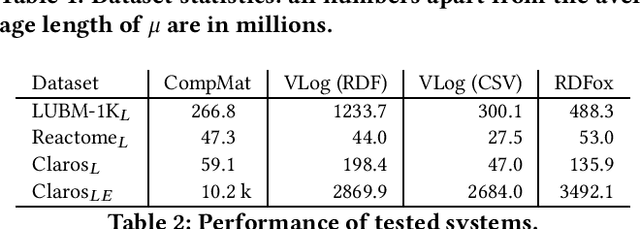


Materialisation is often used in RDF systems as a preprocessing step to derive all facts implied by given RDF triples and rules. Although widely used, materialisation considers all possible rule applications and can use a lot of memory for storing the derived facts, which can hinder performance. We present a novel materialisation technique that compresses the RDF triples so that the rules can sometimes be applied to multiple facts at once, and the derived facts can be represented using structure sharing. Our technique can thus require less space, as well as skip certain rule applications. Our experiments show that our technique can be very effective: when the rules are relatively simple, our system is both faster and requires less memory than prominent state-of-the-art RDF systems.
Word Sense Disambiguation with LSTM: Do We Really Need 100 Billion Words?
Dec 16, 2017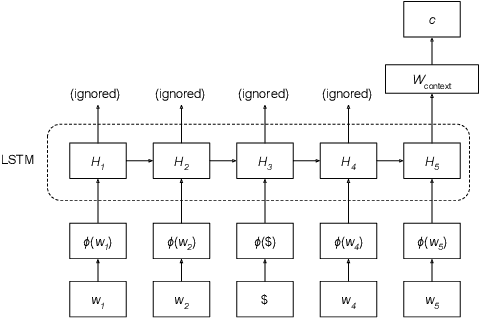


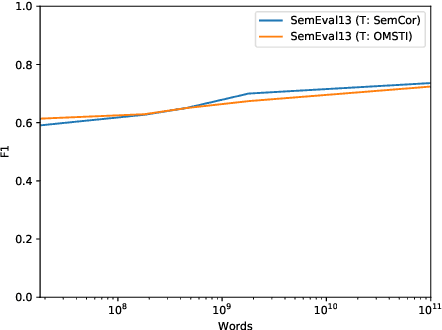
Recently, Yuan et al. (2016) have shown the effectiveness of using Long Short-Term Memory (LSTM) for performing Word Sense Disambiguation (WSD). Their proposed technique outperformed the previous state-of-the-art with several benchmarks, but neither the training data nor the source code was released. This paper presents the results of a reproduction study of this technique using only openly available datasets (GigaWord, SemCore, OMSTI) and software (TensorFlow). From them, it emerged that state-of-the-art results can be obtained with much less data than hinted by Yuan et al. All code and trained models are made freely available.
KOGNAC: Efficient Encoding of Large Knowledge Graphs
Jul 10, 2016

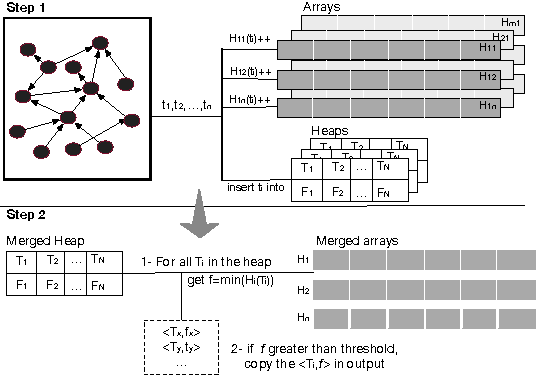
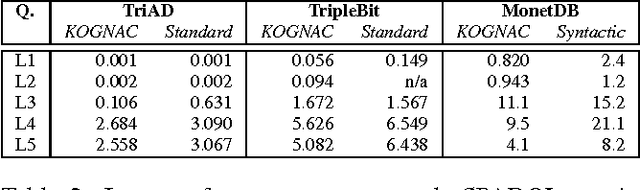
Many Web applications require efficient querying of large Knowledge Graphs (KGs). We propose KOGNAC, a dictionary-encoding algorithm designed to improve SPARQL querying with a judicious combination of statistical and semantic techniques. In KOGNAC, frequent terms are detected with a frequency approximation algorithm and encoded to maximise compression. Infrequent terms are semantically grouped into ontological classes and encoded to increase data locality. We evaluated KOGNAC in combination with state-of-the-art RDF engines, and observed that it significantly improves SPARQL querying on KGs with up to 1B edges.