Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColumn-Oriented Datalog Materialization for Large Knowledge Graphs (Extended Technical Report)
Paper and Code
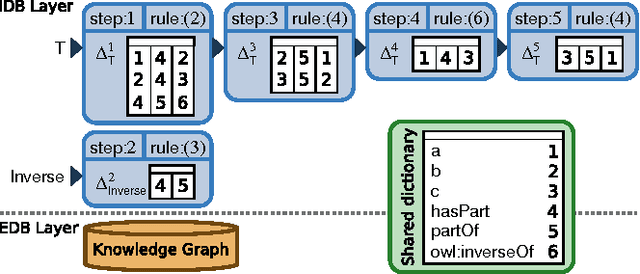



The evaluation of Datalog rules over large Knowledge Graphs (KGs) is essential for many applications. In this paper, we present a new method of materializing Datalog inferences, which combines a column-based memory layout with novel optimization methods that avoid redundant inferences at runtime. The pro-active caching of certain subqueries further increases efficiency. Our empirical evaluation shows that this approach can often match or even surpass the performance of state-of-the-art systems, especially under restricted resources.
View paper on