Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Sense Disambiguation with LSTM: Do We Really Need 100 Billion Words?
Dec 16, 2017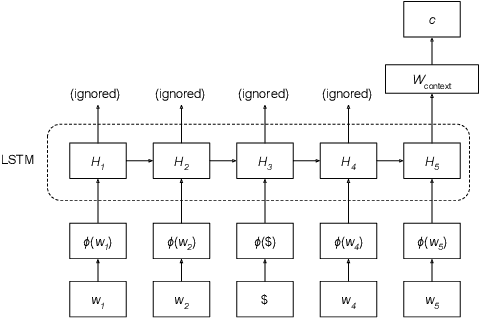


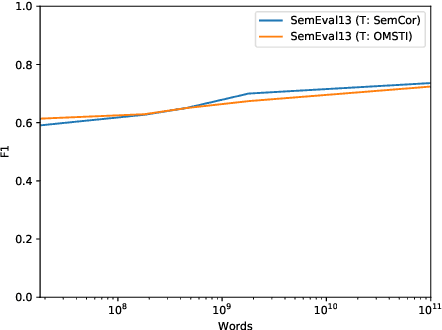
Recently, Yuan et al. (2016) have shown the effectiveness of using Long Short-Term Memory (LSTM) for performing Word Sense Disambiguation (WSD). Their proposed technique outperformed the previous state-of-the-art with several benchmarks, but neither the training data nor the source code was released. This paper presents the results of a reproduction study of this technique using only openly available datasets (GigaWord, SemCore, OMSTI) and software (TensorFlow). From them, it emerged that state-of-the-art results can be obtained with much less data than hinted by Yuan et al. All code and trained models are made freely available.
Via