 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom optimal score matching to optimal sampling
Sep 11, 2024
The recent, impressive advances in algorithmic generation of high-fidelity image, audio, and video are largely due to great successes in score-based diffusion models. A key implementing step is score matching, that is, the estimation of the score function of the forward diffusion process from training data. As shown in earlier literature, the total variation distance between the law of a sample generated from the trained diffusion model and the ground truth distribution can be controlled by the score matching risk. Despite the widespread use of score-based diffusion models, basic theoretical questions concerning exact optimal statistical rates for score estimation and its application to density estimation remain open. We establish the sharp minimax rate of score estimation for smooth, compactly supported densities. Formally, given \(n\) i.i.d. samples from an unknown \(\alpha\)-H\"{o}lder density \(f\) supported on \([-1, 1]\), we prove the minimax rate of estimating the score function of the diffused distribution \(f * \mathcal{N}(0, t)\) with respect to the score matching loss is \(\frac{1}{nt^2} \wedge \frac{1}{nt^{3/2}} \wedge (t^{\alpha-1} + n^{-2(\alpha-1)/(2\alpha+1)})\) for all \(\alpha > 0\) and \(t \ge 0\). As a consequence, it is shown the law \(\hat{f}\) of a sample generated from the diffusion model achieves the sharp minimax rate \(\bE(\dTV(\hat{f}, f)^2) \lesssim n^{-2\alpha/(2\alpha+1)}\) for all \(\alpha > 0\) without any extraneous logarithmic terms which are prevalent in the literature, and without the need for early stopping which has been required for all existing procedures to the best of our knowledge.
Implicit Regularization of Gradient Flow on One-Layer Softmax Attention
Mar 13, 2024We study gradient flow on the exponential loss for a classification problem with a one-layer softmax attention model, where the key and query weight matrices are trained separately. Under a separability assumption on the data, we show that when gradient flow achieves the minimal loss value, it further implicitly minimizes the nuclear norm of the product of the key and query weight matrices. Such implicit regularization can be described by a Support Vector Machine (SVM) problem with respect to the attention weights. This finding contrasts with prior results showing that the gradient descent induces an implicit regularization on the Frobenius norm on the product weight matrix when the key and query matrices are combined into a single weight matrix for training. For diagonal key and query matrices, our analysis builds upon the reparameterization technique and exploits approximate KKT conditions of the SVM associated with the classification data. Moreover, the results are extended to general weights configurations given proper alignment of the weight matrices' singular spaces with the data features at initialization.
Leave-one-out Singular Subspace Perturbation Analysis for Spectral Clustering
May 30, 2022The singular subspaces perturbation theory is of fundamental importance in probability and statistics. It has various applications across different fields. We consider two arbitrary matrices where one is a leave-one-column-out submatrix of the other one and establish a novel perturbation upper bound for the distance between two corresponding singular subspaces. It is well-suited for mixture models and results in a sharper and finer statistical analysis than classical perturbation bounds such as Wedin's Theorem. Powered by this leave-one-out perturbation theory, we provide a deterministic entrywise analysis for the performance of the spectral clustering under mixture models. Our analysis leads to an explicit exponential error rate for the clustering of sub-Gaussian mixture models. For the mixture of isotropic Gaussians, the rate is optimal under a weaker signal-to-noise condition than that of L\"offler et al. (2021).
Optimal estimation of high-dimensional Gaussian mixtures
Feb 14, 2020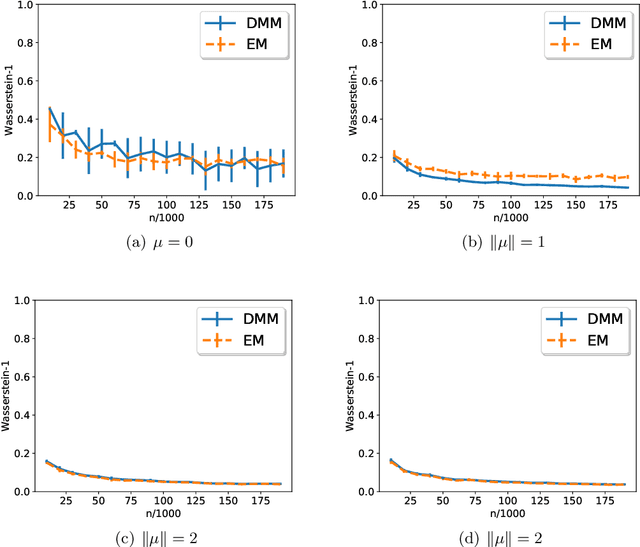
This paper studies the optimal rate of estimation in a finite Gaussian location mixture model in high dimensions without separation conditions. We assume that the number of components $k$ is bounded and that the centers lie in a ball of bounded radius, while allowing the dimension $d$ to be as large as the sample size $n$. Extending the one-dimensional result of Heinrich and Kahn \cite{HK2015}, we show that the minimax rate of estimating the mixing distribution in Wasserstein distance is $\Theta((d/n)^{1/4} + n^{-1/(4k-2)})$, achieved by an estimator computable in time $O(nd^2+n^{5/4})$. Furthermore, we show that the mixture density can be estimated at the optimal parametric rate $\Theta(\sqrt{d/n})$ in Hellinger distance; however, no computationally efficient algorithm is known to achieve the optimal rate. Both the theoretical and methodological development rely on a careful application of the method of moments. Central to our results is the observation that the information geometry of finite Gaussian mixtures is characterized by the moment tensors of the mixing distribution, whose low-rank structure can be exploited to obtain a sharp local entropy bound.
Optimality of Spectral Clustering for Gaussian Mixture Model
Nov 01, 2019Spectral clustering is one of the most popular algorithms to group high dimensional data. It is easy to implement and computationally efficient. Despite its popularity and successful applications, its theoretical properties have not been fully understood. The spectral clustering algorithm is often used as a consistent initializer for more sophisticated clustering algorithms. However, in this paper, we show that spectral clustering is actually already optimal in the Gaussian Mixture Model, when the number of clusters of is fixed and consistent clustering is possible. Contrary to that spectral gap conditions are widely assumed in literature to analyze spectral clustering, these conditions are not needed in this paper to establish its optimality.
Randomly initialized EM algorithm for two-component Gaussian mixture achieves near optimality in $O(\sqrt{n})$ iterations
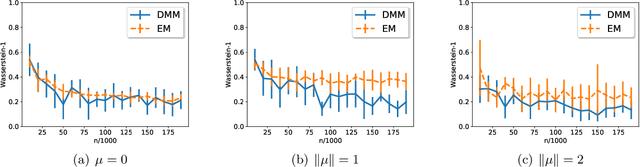
Aug 28, 2019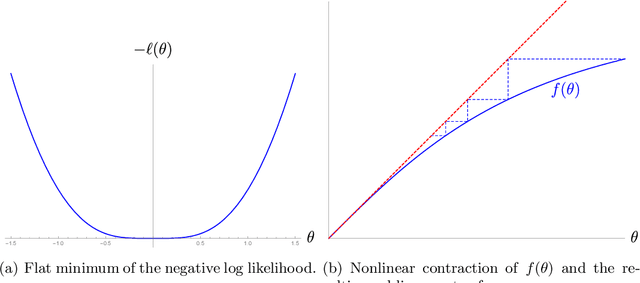
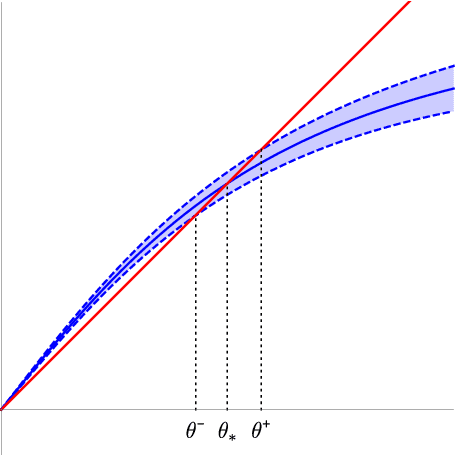
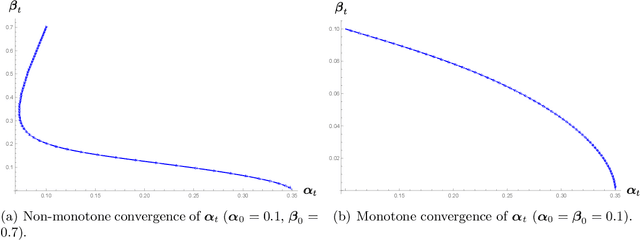
We analyze the classical EM algorithm for parameter estimation in the symmetric two-component Gaussian mixtures in $d$ dimensions. We show that, even in the absence of any separation between components, provided that the sample size satisfies $n=\Omega(d \log^3 d)$, the randomly initialized EM algorithm converges to an estimate in at most $O(\sqrt{n})$ iterations with high probability, which is at most $O((\frac{d \log^3 n}{n})^{1/4})$ in Euclidean distance from the true parameter and within logarithmic factors of the minimax rate of $(\frac{d}{n})^{1/4}$. Both the nonparametric statistical rate and the sublinear convergence rate are direct consequences of the zero Fisher information in the worst case. Refined pointwise guarantees beyond worst-case analysis and convergence to the MLE are also shown under mild conditions. This improves the previous result of Balakrishnan et al \cite{BWY17} which requires strong conditions on both the separation of the components and the quality of the initialization, and that of Daskalakis et al \cite{DTZ17} which requires sample splitting and restarting the EM iteration.
Optimal Estimation and Completion of Matrices with Biclustering Structures
Oct 22, 2018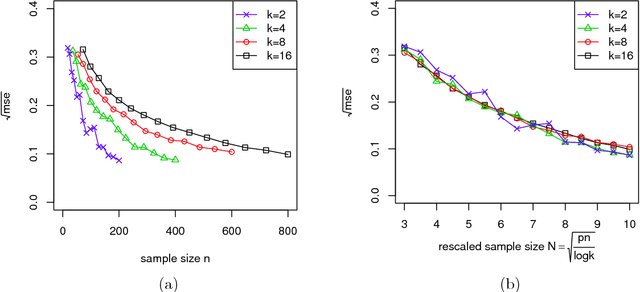
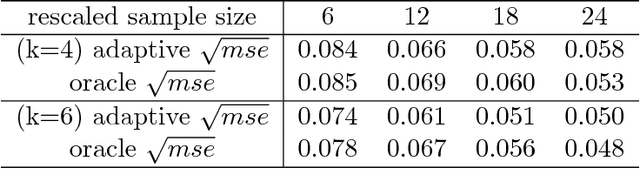
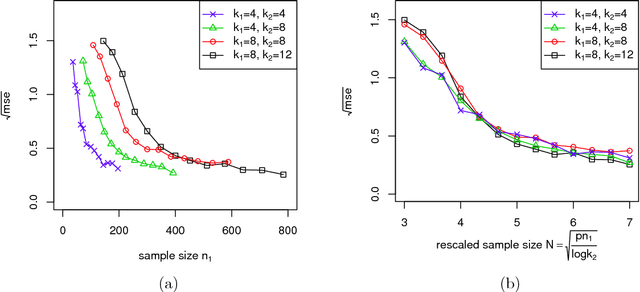
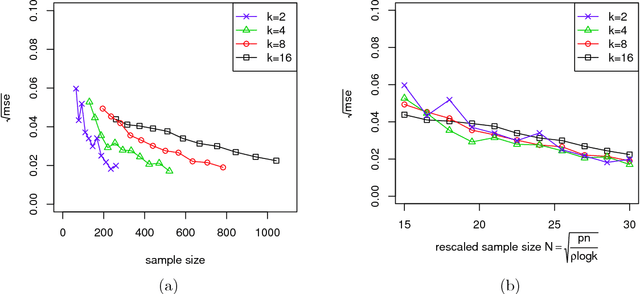
Biclustering structures in data matrices were first formalized in a seminal paper by John Hartigan (1972) where one seeks to cluster cases and variables simultaneously. Such structures are also prevalent in block modeling of networks. In this paper, we develop a unified theory for the estimation and completion of matrices with biclustering structures, where the data is a partially observed and noise contaminated data matrix with a certain biclustering structure. In particular, we show that a constrained least squares estimator achieves minimax rate-optimal performance in several of the most important scenarios. To this end, we derive unified high probability upper bounds for all sub-Gaussian data and also provide matching minimax lower bounds in both Gaussian and binary cases. Due to the close connection of graphon to stochastic block models, an immediate consequence of our general results is a minimax rate-optimal estimator for sparse graphons.
Theoretical and Computational Guarantees of Mean Field Variational Inference for Community Detection
Dec 11, 2017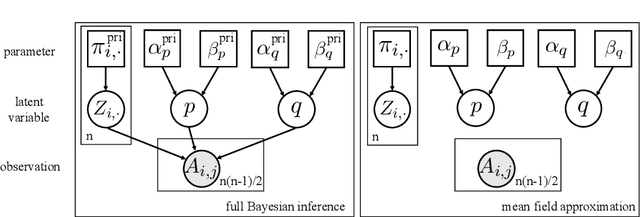
The mean field variational Bayes method is becoming increasingly popular in statistics and machine learning. Its iterative Coordinate Ascent Variational Inference algorithm has been widely applied to large scale Bayesian inference. See Blei et al. (2017) for a recent comprehensive review. Despite the popularity of the mean field method there exist remarkably little fundamental theoretical justifications. To the best of our knowledge, the iterative algorithm has never been investigated for any high dimensional and complex model. In this paper, we study the mean field method for community detection under the Stochastic Block Model. For an iterative Batch Coordinate Ascent Variational Inference algorithm, we show that it has a linear convergence rate and converges to the minimax rate within $\log n$ iterations. This complements the results of Bickel et al. (2013) which studied the global minimum of the mean field variational Bayes and obtained asymptotic normal estimation of global model parameters. In addition, we obtain similar optimality results for Gibbs sampling and an iterative procedure to calculate maximum likelihood estimation, which can be of independent interest.
Statistical and Computational Guarantees of Lloyd's Algorithm and its Variants
Dec 07, 2016


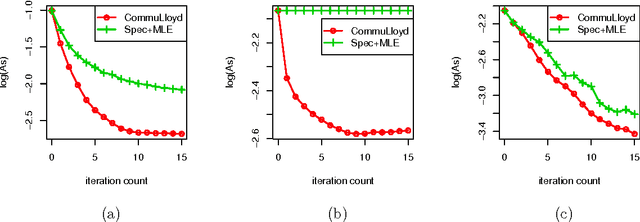
Clustering is a fundamental problem in statistics and machine learning. Lloyd's algorithm, proposed in 1957, is still possibly the most widely used clustering algorithm in practice due to its simplicity and empirical performance. However, there has been little theoretical investigation on the statistical and computational guarantees of Lloyd's algorithm. This paper is an attempt to bridge this gap between practice and theory. We investigate the performance of Lloyd's algorithm on clustering sub-Gaussian mixtures. Under an appropriate initialization for labels or centers, we show that Lloyd's algorithm converges to an exponentially small clustering error after an order of $\log n$ iterations, where $n$ is the sample size. The error rate is shown to be minimax optimal. For the two-mixture case, we only require the initializer to be slightly better than random guess. In addition, we extend the Lloyd's algorithm and its analysis to community detection and crowdsourcing, two problems that have received a lot of attention recently in statistics and machine learning. Two variants of Lloyd's algorithm are proposed respectively for community detection and crowdsourcing. On the theoretical side, we provide statistical and computational guarantees of the two algorithms, and the results improve upon some previous signal-to-noise ratio conditions in literature for both problems. Experimental results on simulated and real data sets demonstrate competitive performance of our algorithms to the state-of-the-art methods.
Community Detection in Degree-Corrected Block Models
Jul 24, 2016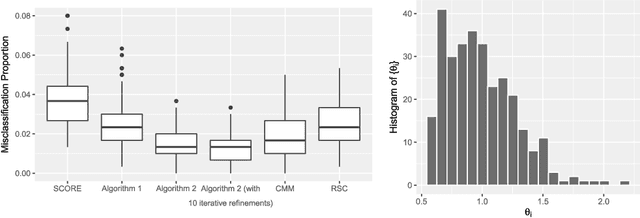

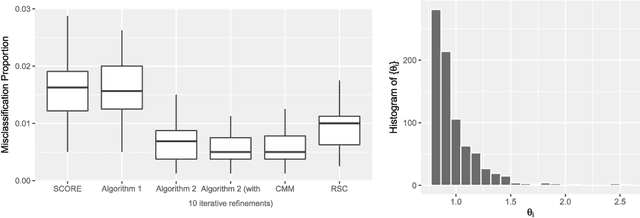
Community detection is a central problem of network data analysis. Given a network, the goal of community detection is to partition the network nodes into a small number of clusters, which could often help reveal interesting structures. The present paper studies community detection in Degree-Corrected Block Models (DCBMs). We first derive asymptotic minimax risks of the problem for a misclassification proportion loss under appropriate conditions. The minimax risks are shown to depend on degree-correction parameters, community sizes, and average within and between community connectivities in an intuitive and interpretable way. In addition, we propose a polynomial time algorithm to adaptively perform consistent and even asymptotically optimal community detection in DCBMs.