 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINFUSER: Influence-Guided Self-Evolution Improves Reasoning
Jun 08, 2026Self-evolution offers a scalable path to stronger reasoning: a pretrained language model improves itself with only minimal external supervision. Yet existing methods either depend on extensively curated or teacher-generated training data, or, when the generator runs unsupervised, reward it by a difficulty heuristic that need not improve the solver. We introduce INFUSER, an iterative co-training framework with two co-evolving roles: a Generator that drafts questions and reference golden answers from a pool of unstructured, automatically collected documents, and a Solver that improves by training on them. The solver is trained with standard correctness rewards against the generator-provided answers, while the generator is rewarded by an optimizer-aware influence score that measures whether each proposed question would actually improve the solver on the target distribution. Because this continuous, noisy influence score is poorly served by standard GRPO, we propose DuGRPO, a dual-normalized variant of GRPO, for generator training. Together, these turn the document pool into an adaptive curriculum that favors questions useful to the current solver, not just hard ones. On Qwen3-8B-Base, INFUSER outperforms strong self-evolution baselines with over 20% relative improvement on Olympiad and SuperGPQA benchmarks, and an 8B INFUSER co-evolving generator outperforms a frozen 32B thinking generator on math and coding. Ablations confirm each design choice is necessary, and two extensions, applying INFUSER to an instruction-finetuned anchor and augmenting it with rule-verifiable RLVR data, further demonstrate the flexibility and generalizability of the framework. Code is available at https://github.com/FFishy-git/INFUSER.
Implicit Regularization of Gradient Flow on One-Layer Softmax Attention
Mar 13, 2024We study gradient flow on the exponential loss for a classification problem with a one-layer softmax attention model, where the key and query weight matrices are trained separately. Under a separability assumption on the data, we show that when gradient flow achieves the minimal loss value, it further implicitly minimizes the nuclear norm of the product of the key and query weight matrices. Such implicit regularization can be described by a Support Vector Machine (SVM) problem with respect to the attention weights. This finding contrasts with prior results showing that the gradient descent induces an implicit regularization on the Frobenius norm on the product weight matrix when the key and query matrices are combined into a single weight matrix for training. For diagonal key and query matrices, our analysis builds upon the reparameterization technique and exploits approximate KKT conditions of the SVM associated with the classification data. Moreover, the results are extended to general weights configurations given proper alignment of the weight matrices' singular spaces with the data features at initialization.
Training Dynamics of Multi-Head Softmax Attention for In-Context Learning: Emergence, Convergence, and Optimality
Feb 29, 2024We study the dynamics of gradient flow for training a multi-head softmax attention model for in-context learning of multi-task linear regression. We establish the global convergence of gradient flow under suitable choices of initialization. In addition, we prove that an interesting "task allocation" phenomenon emerges during the gradient flow dynamics, where each attention head focuses on solving a single task of the multi-task model. Specifically, we prove that the gradient flow dynamics can be split into three phases -- a warm-up phase where the loss decreases rather slowly and the attention heads gradually build up their inclination towards individual tasks, an emergence phase where each head selects a single task and the loss rapidly decreases, and a convergence phase where the attention parameters converge to a limit. Furthermore, we prove the optimality of gradient flow in the sense that the limiting model learned by gradient flow is on par with the best possible multi-head softmax attention model up to a constant factor. Our analysis also delineates a strict separation in terms of the prediction accuracy of ICL between single-head and multi-head attention models. The key technique for our convergence analysis is to map the gradient flow dynamics in the parameter space to a set of ordinary differential equations in the spectral domain, where the relative magnitudes of the semi-singular values of the attention weights determines task allocation. To our best knowledge, our work provides the first convergence result for the multi-head softmax attention model.
Tensor Kernel Recovery for Spatio-Temporal Hawkes Processes
Nov 24, 2020
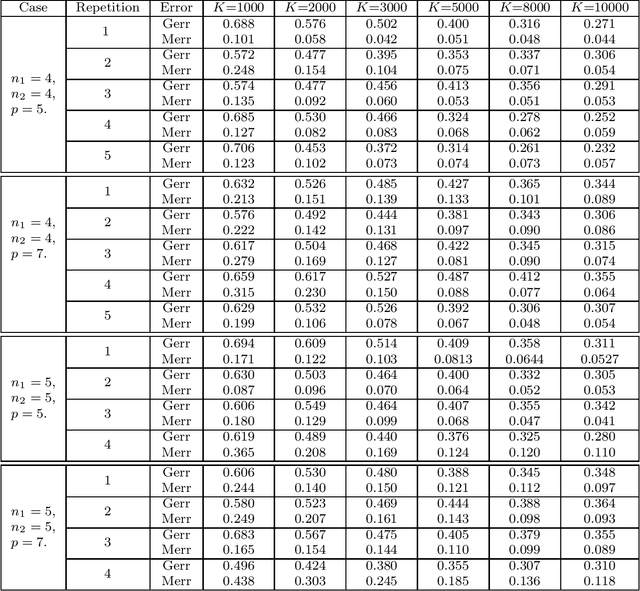
We estimate the general influence functions for spatio-temporal Hawkes processes using a tensor recovery approach by formulating the location dependent influence function that captures the influence of historical events as a tensor kernel. We assume a low-rank structure for the tensor kernel and cast the estimation problem as a convex optimization problem using the Fourier transformed nuclear norm (TNN). We provide theoretical performance guarantees for our approach and present an algorithm to solve the optimization problem. We demonstrate the efficiency of our estimation with numerical simulations.