 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Primitives for Dynamic Big Model Parallelism
Jun 18, 2014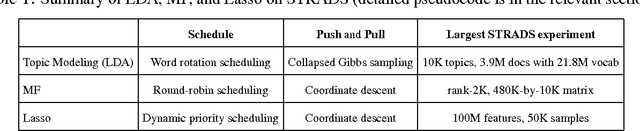
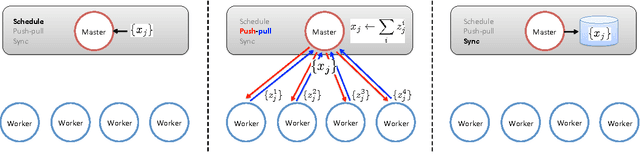

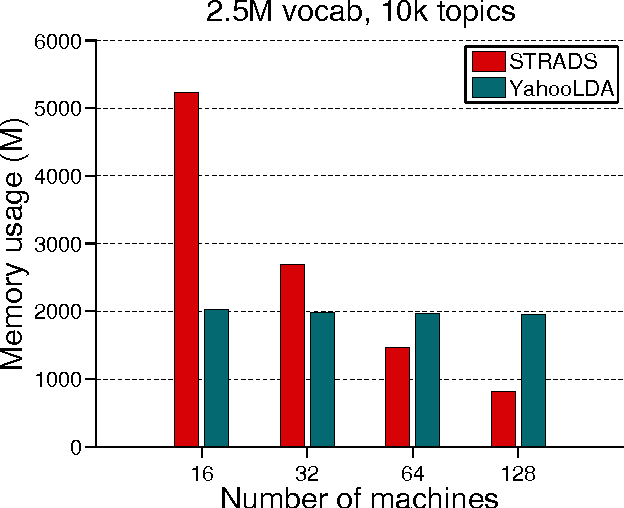
When training large machine learning models with many variables or parameters, a single machine is often inadequate since the model may be too large to fit in memory, while training can take a long time even with stochastic updates. A natural recourse is to turn to distributed cluster computing, in order to harness additional memory and processors. However, naive, unstructured parallelization of ML algorithms can make inefficient use of distributed memory, while failing to obtain proportional convergence speedups - or can even result in divergence. We develop a framework of primitives for dynamic model-parallelism, STRADS, in order to explore partitioning and update scheduling of model variables in distributed ML algorithms - thus improving their memory efficiency while presenting new opportunities to speed up convergence without compromising inference correctness. We demonstrate the efficacy of model-parallel algorithms implemented in STRADS versus popular implementations for Topic Modeling, Matrix Factorization and Lasso.
Structure-Aware Dynamic Scheduler for Parallel Machine Learning
Dec 30, 2013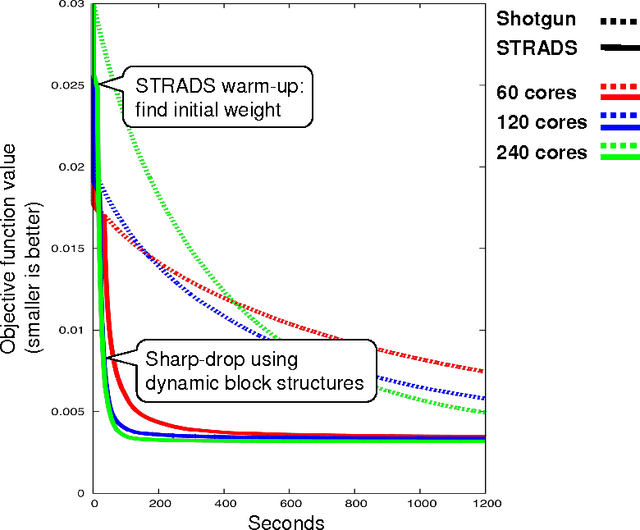
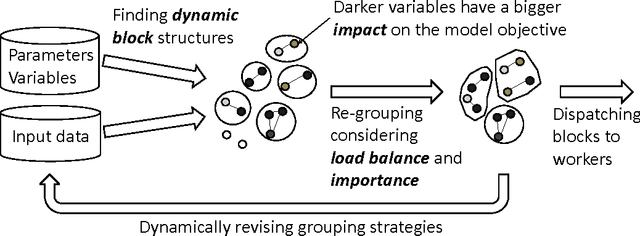
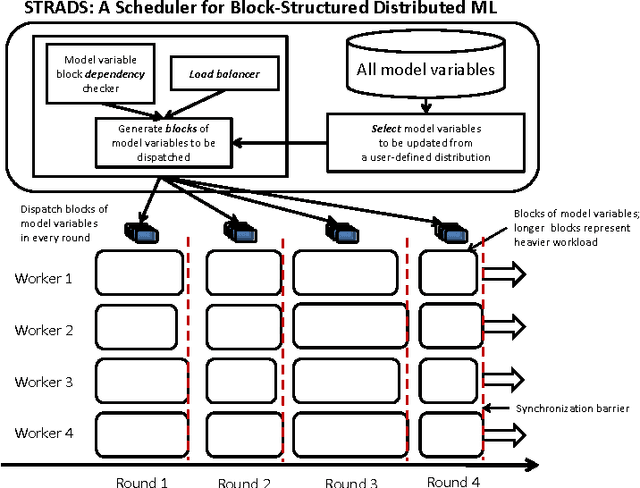
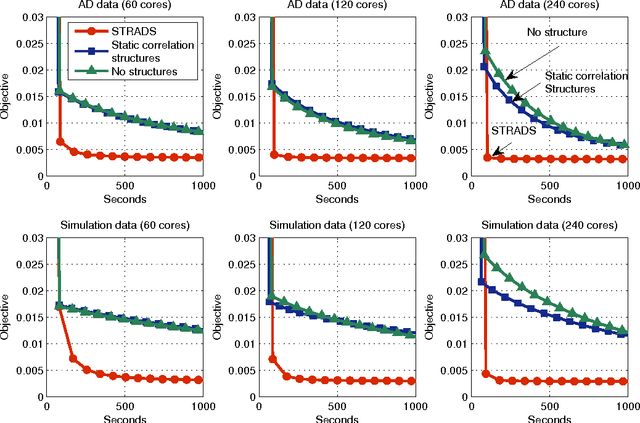
Training large machine learning (ML) models with many variables or parameters can take a long time if one employs sequential procedures even with stochastic updates. A natural solution is to turn to distributed computing on a cluster; however, naive, unstructured parallelization of ML algorithms does not usually lead to a proportional speedup and can even result in divergence, because dependencies between model elements can attenuate the computational gains from parallelization and compromise correctness of inference. Recent efforts toward this issue have benefited from exploiting the static, a priori block structures residing in ML algorithms. In this paper, we take this path further by exploring the dynamic block structures and workloads therein present during ML program execution, which offers new opportunities for improving convergence, correctness, and load balancing in distributed ML. We propose and showcase a general-purpose scheduler, STRADS, for coordinating distributed updates in ML algorithms, which harnesses the aforementioned opportunities in a systematic way. We provide theoretical guarantees for our scheduler, and demonstrate its efficacy versus static block structures on Lasso and Matrix Factorization.