 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassSpecGym: A benchmark for the discovery and identification of molecules
Oct 30, 2024The discovery and identification of molecules in biological and environmental samples is crucial for advancing biomedical and chemical sciences. Tandem mass spectrometry (MS/MS) is the leading technique for high-throughput elucidation of molecular structures. However, decoding a molecular structure from its mass spectrum is exceptionally challenging, even when performed by human experts. As a result, the vast majority of acquired MS/MS spectra remain uninterpreted, thereby limiting our understanding of the underlying (bio)chemical processes. Despite decades of progress in machine learning applications for predicting molecular structures from MS/MS spectra, the development of new methods is severely hindered by the lack of standard datasets and evaluation protocols. To address this problem, we propose MassSpecGym -- the first comprehensive benchmark for the discovery and identification of molecules from MS/MS data. Our benchmark comprises the largest publicly available collection of high-quality labeled MS/MS spectra and defines three MS/MS annotation challenges: \textit{de novo} molecular structure generation, molecule retrieval, and spectrum simulation. It includes new evaluation metrics and a generalization-demanding data split, therefore standardizing the MS/MS annotation tasks and rendering the problem accessible to the broad machine learning community. MassSpecGym is publicly available at \url{https://github.com/pluskal-lab/MassSpecGym}.
Asymmetries in Financial Spillovers
Oct 21, 2024This paper analyzes nonlinearities in the international transmission of financial shocks originating in the US. To do so, we develop a flexible nonlinear multi-country model. Our framework is capable of producing asymmetries in the responses to financial shocks for shock size and sign, and over time. We show that international reactions to US-based financial shocks are asymmetric along these dimensions. Particularly, we find that adverse shocks trigger stronger declines in output, inflation, and stock markets than benign shocks. Further, we investigate time variation in the estimated dynamic effects and characterize the responsiveness of three major central banks to financial shocks.
On Convolutional Vision Transformers for Yield Prediction
Feb 08, 2024While a variety of methods offer good yield prediction on histogrammed remote sensing data, vision Transformers are only sparsely represented in the literature. The Convolution vision Transformer (CvT) is being tested to evaluate vision Transformers that are currently achieving state-of-the-art results in many other vision tasks. CvT combines some of the advantages of convolution with the advantages of dynamic attention and global context fusion of Transformers. It performs worse than widely tested methods such as XGBoost and CNNs, but shows that Transformers have potential to improve yield prediction.
Bayesian Nonlinear Regression using Sums of Simple Functions
Dec 04, 2023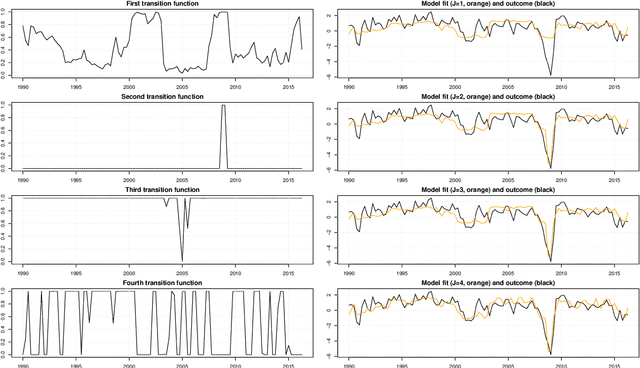
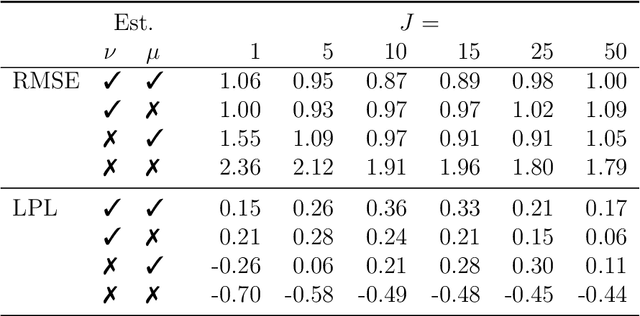
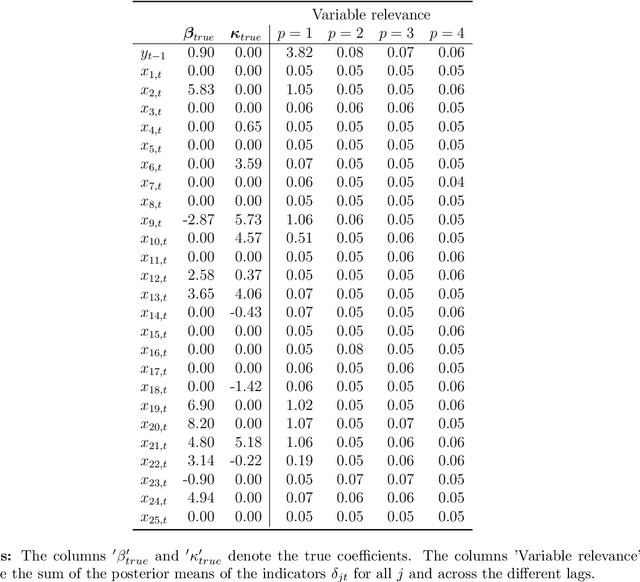
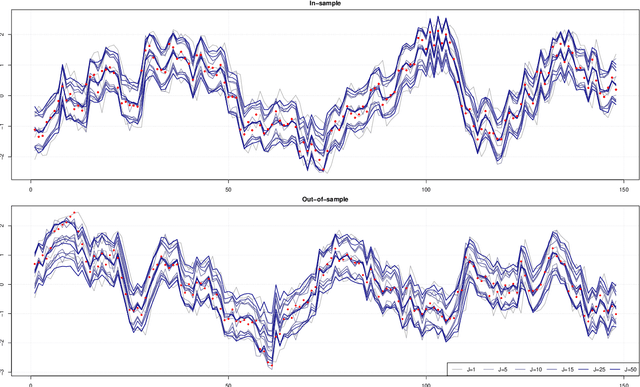
This paper proposes a new Bayesian machine learning model that can be applied to large datasets arising in macroeconomics. Our framework sums over many simple two-component location mixtures. The transition between components is determined by a logistic function that depends on a single threshold variable and two hyperparameters. Each of these individual models only accounts for a minor portion of the variation in the endogenous variables. But many of them are capable of capturing arbitrary nonlinear conditional mean relations. Conjugate priors enable fast and efficient inference. In simulations, we show that our approach produces accurate point and density forecasts. In a real-data exercise, we forecast US macroeconomic aggregates and consider the nonlinear effects of financial shocks in a large-scale nonlinear VAR.
Predictive Density Combination Using a Tree-Based Synthesis Function
Nov 21, 2023Bayesian predictive synthesis (BPS) provides a method for combining multiple predictive distributions based on agent/expert opinion analysis theory and encompasses a range of existing density forecast pooling methods. The key ingredient in BPS is a ``synthesis'' function. This is typically specified parametrically as a dynamic linear regression. In this paper, we develop a nonparametric treatment of the synthesis function using regression trees. We show the advantages of our tree-based approach in two macroeconomic forecasting applications. The first uses density forecasts for GDP growth from the euro area's Survey of Professional Forecasters. The second combines density forecasts of US inflation produced by many regression models involving different predictors. Both applications demonstrate the benefits -- in terms of improved forecast accuracy and interpretability -- of modeling the synthesis function nonparametrically.
Grouping Shapley Value Feature Importances of Random Forests for explainable Yield Prediction
Apr 14, 2023Explainability in yield prediction helps us fully explore the potential of machine learning models that are already able to achieve high accuracy for a variety of yield prediction scenarios. The data included for the prediction of yields are intricate and the models are often difficult to understand. However, understanding the models can be simplified by using natural groupings of the input features. Grouping can be achieved, for example, by the time the features are captured or by the sensor used to do so. The state-of-the-art for interpreting machine learning models is currently defined by the game-theoretic approach of Shapley values. To handle groups of features, the calculated Shapley values are typically added together, ignoring the theoretical limitations of this approach. We explain the concept of Shapley values directly computed for predefined groups of features and introduce an algorithm to compute them efficiently on tree structures. We provide a blueprint for designing swarm plots that combine many local explanations for global understanding. Extensive evaluation of two different yield prediction problems shows the worth of our approach and demonstrates how we can enable a better understanding of yield prediction models in the future, ultimately leading to mutual enrichment of research and application.
Enhanced Bayesian Neural Networks for Macroeconomics and Finance
Nov 10, 2022We develop Bayesian neural networks (BNNs) that permit to model generic nonlinearities and time variation for (possibly large sets of) macroeconomic and financial variables. From a methodological point of view, we allow for a general specification of networks that can be applied to either dense or sparse datasets, and combines various activation functions, a possibly very large number of neurons, and stochastic volatility (SV) for the error term. From a computational point of view, we develop fast and efficient estimation algorithms for the general BNNs we introduce. From an empirical point of view, we show both with simulated data and with a set of common macro and financial applications that our BNNs can be of practical use, particularly so for observations in the tails of the cross-sectional or time series distributions of the target variables.
Extreme Gradient Boosting for Yield Estimation compared with Deep Learning Approaches
Aug 26, 2022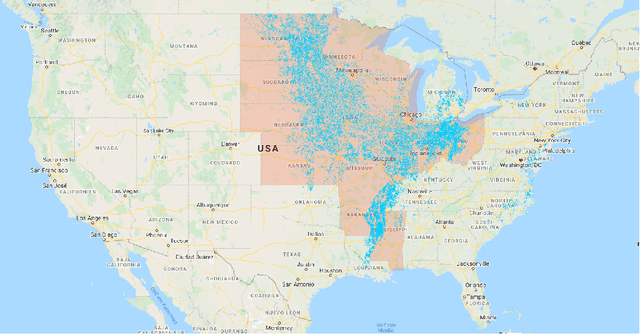
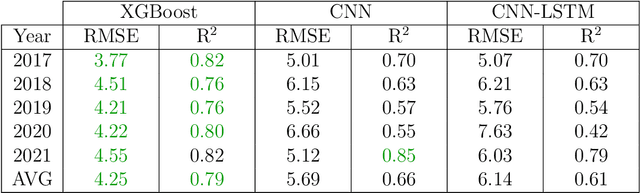
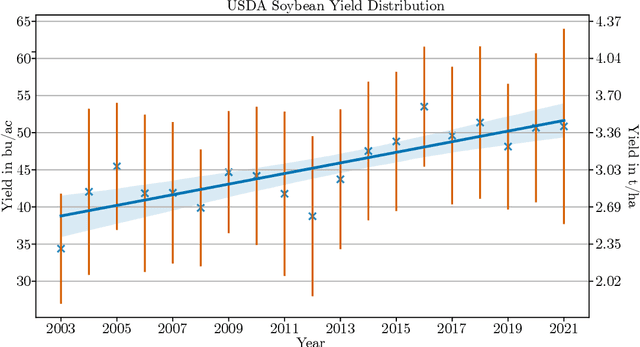
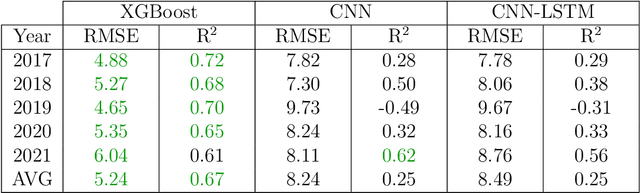
Accurate prediction of crop yield before harvest is of great importance for crop logistics, market planning, and food distribution around the world. Yield prediction requires monitoring of phenological and climatic characteristics over extended time periods to model the complex relations involved in crop development. Remote sensing satellite images provided by various satellites circumnavigating the world are a cheap and reliable way to obtain data for yield prediction. The field of yield prediction is currently dominated by Deep Learning approaches. While the accuracies reached with those approaches are promising, the needed amounts of data and the ``black-box'' nature can restrict the application of Deep Learning methods. The limitations can be overcome by proposing a pipeline to process remote sensing images into feature-based representations that allow the employment of Extreme Gradient Boosting (XGBoost) for yield prediction. A comparative evaluation of soybean yield prediction within the United States shows promising prediction accuracies compared to state-of-the-art yield prediction systems based on Deep Learning. Feature importances expose the near-infrared spectrum of light as an important feature within our models. The reported results hint at the capabilities of XGBoost for yield prediction and encourage future experiments with XGBoost for yield prediction on other crops in regions all around the world.
Unsupervised Features Ranking via Coalitional Game Theory for Categorical Data
May 17, 2022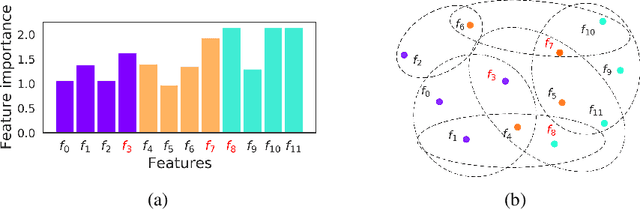
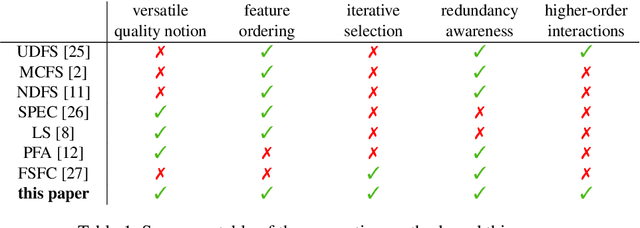
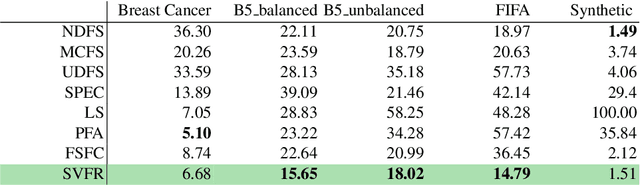
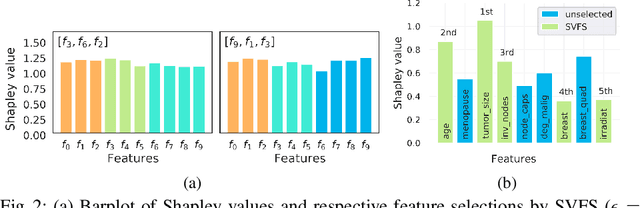
Not all real-world data are labeled, and when labels are not available, it is often costly to obtain them. Moreover, as many algorithms suffer from the curse of dimensionality, reducing the features in the data to a smaller set is often of great utility. Unsupervised feature selection aims to reduce the number of features, often using feature importance scores to quantify the relevancy of single features to the task at hand. These scores can be based only on the distribution of variables and the quantification of their interactions. The previous literature, mainly investigating anomaly detection and clusters, fails to address the redundancy-elimination issue. We propose an evaluation of correlations among features to compute feature importance scores representing the contribution of single features in explaining the dataset's structure. Based on Coalitional Game Theory, our feature importance scores include a notion of redundancy awareness making them a tool to achieve redundancy-free feature selection. We show that the deriving features' selection outperforms competing methods in lowering the redundancy rate while maximizing the information contained in the data. We also introduce an approximated version of the algorithm to reduce the complexity of Shapley values' computations.
Approximate Bayesian inference and forecasting in huge-dimensional multi-country VARs
Mar 08, 2021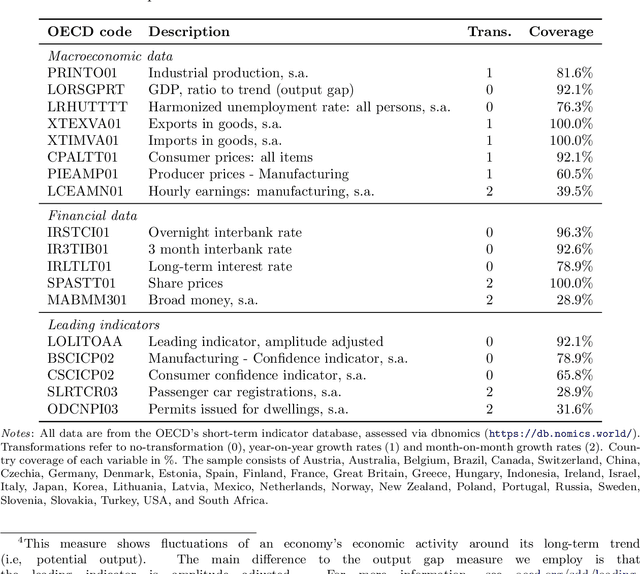
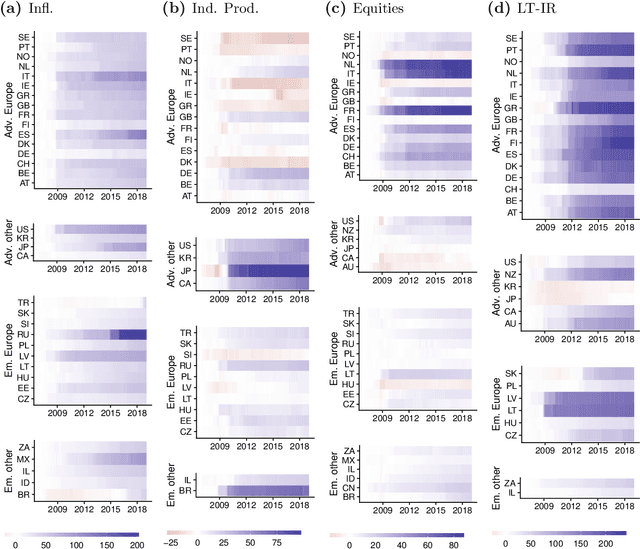

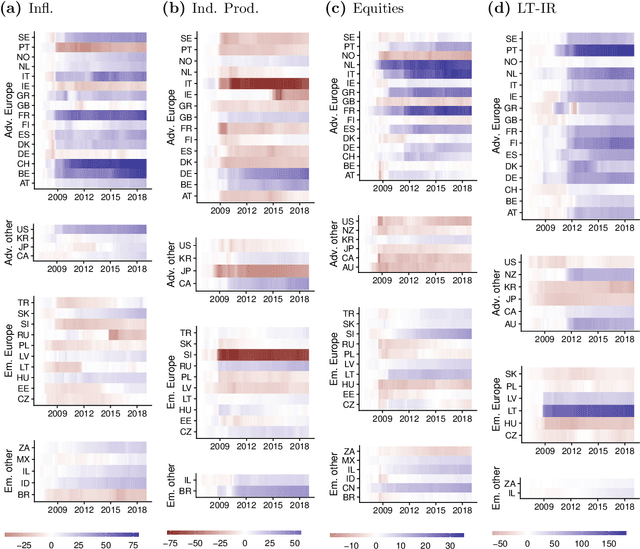
The Panel Vector Autoregressive (PVAR) model is a popular tool for macroeconomic forecasting and structural analysis in multi-country applications since it allows for spillovers between countries in a very flexible fashion. However, this flexibility means that the number of parameters to be estimated can be enormous leading to over-parameterization concerns. Bayesian global-local shrinkage priors, such as the Horseshoe prior used in this paper, can overcome these concerns, but they require the use of Markov Chain Monte Carlo (MCMC) methods rendering them computationally infeasible in high dimensions. In this paper, we develop computationally efficient Bayesian methods for estimating PVARs using an integrated rotated Gaussian approximation (IRGA). This exploits the fact that whereas own country information is often important in PVARs, information on other countries is often unimportant. Using an IRGA, we split the the posterior into two parts: one involving own country coefficients, the other involving other country coefficients. Fast methods such as approximate message passing or variational Bayes can be used on the latter and, conditional on these, the former are estimated with precision using MCMC methods. In a forecasting exercise involving PVARs with up to $18$ variables for each of $38$ countries, we demonstrate that our methods produce good forecasts quickly.