 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpening the Black Box of Local Projections
May 18, 2025Local projections (LPs) are widely used in empirical macroeconomics to estimate impulse responses to policy interventions. Yet, in many ways, they are black boxes. It is often unclear what mechanism or historical episodes drive a particular estimate. We introduce a new decomposition of LP estimates into the sum of contributions of historical events, which is the product, for each time stamp, of a weight and the realization of the response variable. In the least squares case, we show that these weights admit two interpretations. First, they represent purified and standardized shocks. Second, they serve as proximity scores between the projected policy intervention and past interventions in the sample. Notably, this second interpretation extends naturally to machine learning methods, many of which yield impulse responses that, while nonlinear in predictors, still aggregate past outcomes linearly via proximity-based weights. Applying this framework to shocks in monetary and fiscal policy, global temperature, and the excess bond premium, we find that easily identifiable events-such as Nixon's interference with the Fed, stagflation, World War II, and the Mount Agung volcanic eruption-emerge as dominant drivers of often heavily concentrated impulse response estimates.
Dual Interpretation of Machine Learning Forecasts
Dec 17, 2024Machine learning predictions are typically interpreted as the sum of contributions of predictors. Yet, each out-of-sample prediction can also be expressed as a linear combination of in-sample values of the predicted variable, with weights corresponding to pairwise proximity scores between current and past economic events. While this dual route leads nowhere in some contexts (e.g., large cross-sectional datasets), it provides sparser interpretations in settings with many regressors and little training data-like macroeconomic forecasting. In this case, the sequence of contributions can be visualized as a time series, allowing analysts to explain predictions as quantifiable combinations of historical analogies. Moreover, the weights can be viewed as those of a data portfolio, inspiring new diagnostic measures such as forecast concentration, short position, and turnover. We show how weights can be retrieved seamlessly for (kernel) ridge regression, random forest, boosted trees, and neural networks. Then, we apply these tools to analyze post-pandemic forecasts of inflation, GDP growth, and recession probabilities. In all cases, the approach opens the black box from a new angle and demonstrates how machine learning models leverage history partly repeating itself.
Asymmetries in Financial Spillovers
Oct 21, 2024This paper analyzes nonlinearities in the international transmission of financial shocks originating in the US. To do so, we develop a flexible nonlinear multi-country model. Our framework is capable of producing asymmetries in the responses to financial shocks for shock size and sign, and over time. We show that international reactions to US-based financial shocks are asymmetric along these dimensions. Particularly, we find that adverse shocks trigger stronger declines in output, inflation, and stock markets than benign shocks. Further, we investigate time variation in the estimated dynamic effects and characterize the responsiveness of three major central banks to financial shocks.
Maximally Forward-Looking Core Inflation
Apr 08, 2024Timely monetary policy decision-making requires timely core inflation measures. We create a new core inflation series that is explicitly designed to succeed at that goal. Precisely, we introduce the Assemblage Regression, a generalized nonnegative ridge regression problem that optimizes the price index's subcomponent weights such that the aggregate is maximally predictive of future headline inflation. Ordering subcomponents according to their rank in each period switches the algorithm to be learning supervised trimmed inflation - or, put differently, the maximally forward-looking summary statistic of the realized price changes distribution. In an extensive out-of-sample forecasting experiment for the US and the euro area, we find substantial improvements for signaling medium-term inflation developments in both the pre- and post-Covid years. Those coming from the supervised trimmed version are particularly striking, and are attributable to a highly asymmetric trimming which contrasts with conventional indicators. We also find that this metric was indicating first upward pressures on inflation as early as mid-2020 and quickly captured the turning point in 2022. We also consider extensions, like assembling inflation from geographical regions, trimmed temporal aggregation, and building core measures specialized for either upside or downside inflation risks.
From Reactive to Proactive Volatility Modeling with Hemisphere Neural Networks
Nov 27, 2023



We reinvigorate maximum likelihood estimation (MLE) for macroeconomic density forecasting through a novel neural network architecture with dedicated mean and variance hemispheres. Our architecture features several key ingredients making MLE work in this context. First, the hemispheres share a common core at the entrance of the network which accommodates for various forms of time variation in the error variance. Second, we introduce a volatility emphasis constraint that breaks mean/variance indeterminacy in this class of overparametrized nonlinear models. Third, we conduct a blocked out-of-bag reality check to curb overfitting in both conditional moments. Fourth, the algorithm utilizes standard deep learning software and thus handles large data sets - both computationally and statistically. Ergo, our Hemisphere Neural Network (HNN) provides proactive volatility forecasts based on leading indicators when it can, and reactive volatility based on the magnitude of previous prediction errors when it must. We evaluate point and density forecasts with an extensive out-of-sample experiment and benchmark against a suite of models ranging from classics to more modern machine learning-based offerings. In all cases, HNN fares well by consistently providing accurate mean/variance forecasts for all targets and horizons. Studying the resulting volatility paths reveals its versatility, while probabilistic forecasting evaluation metrics showcase its enviable reliability. Finally, we also demonstrate how this machinery can be merged with other structured deep learning models by revisiting Goulet Coulombe (2022)'s Neural Phillips Curve.
Non-linear dimension reduction in factor-augmented vector autoregressions
Sep 09, 2023
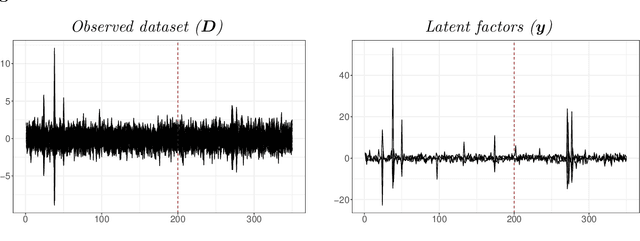


This paper introduces non-linear dimension reduction in factor-augmented vector autoregressions to analyze the effects of different economic shocks. I argue that controlling for non-linearities between a large-dimensional dataset and the latent factors is particularly useful during turbulent times of the business cycle. In simulations, I show that non-linear dimension reduction techniques yield good forecasting performance, especially when data is highly volatile. In an empirical application, I identify a monetary policy as well as an uncertainty shock excluding and including observations of the COVID-19 pandemic. Those two applications suggest that the non-linear FAVAR approaches are capable of dealing with the large outliers caused by the COVID-19 pandemic and yield reliable results in both scenarios.
Enhanced Bayesian Neural Networks for Macroeconomics and Finance
Nov 10, 2022We develop Bayesian neural networks (BNNs) that permit to model generic nonlinearities and time variation for (possibly large sets of) macroeconomic and financial variables. From a methodological point of view, we allow for a general specification of networks that can be applied to either dense or sparse datasets, and combines various activation functions, a possibly very large number of neurons, and stochastic volatility (SV) for the error term. From a computational point of view, we develop fast and efficient estimation algorithms for the general BNNs we introduce. From an empirical point of view, we show both with simulated data and with a set of common macro and financial applications that our BNNs can be of practical use, particularly so for observations in the tails of the cross-sectional or time series distributions of the target variables.