 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Convolutional Vision Transformers for Yield Prediction
Feb 08, 2024While a variety of methods offer good yield prediction on histogrammed remote sensing data, vision Transformers are only sparsely represented in the literature. The Convolution vision Transformer (CvT) is being tested to evaluate vision Transformers that are currently achieving state-of-the-art results in many other vision tasks. CvT combines some of the advantages of convolution with the advantages of dynamic attention and global context fusion of Transformers. It performs worse than widely tested methods such as XGBoost and CNNs, but shows that Transformers have potential to improve yield prediction.
Grouping Shapley Value Feature Importances of Random Forests for explainable Yield Prediction
Apr 14, 2023Explainability in yield prediction helps us fully explore the potential of machine learning models that are already able to achieve high accuracy for a variety of yield prediction scenarios. The data included for the prediction of yields are intricate and the models are often difficult to understand. However, understanding the models can be simplified by using natural groupings of the input features. Grouping can be achieved, for example, by the time the features are captured or by the sensor used to do so. The state-of-the-art for interpreting machine learning models is currently defined by the game-theoretic approach of Shapley values. To handle groups of features, the calculated Shapley values are typically added together, ignoring the theoretical limitations of this approach. We explain the concept of Shapley values directly computed for predefined groups of features and introduce an algorithm to compute them efficiently on tree structures. We provide a blueprint for designing swarm plots that combine many local explanations for global understanding. Extensive evaluation of two different yield prediction problems shows the worth of our approach and demonstrates how we can enable a better understanding of yield prediction models in the future, ultimately leading to mutual enrichment of research and application.
SOCRATES: A Stereo Camera Trap for Monitoring of Biodiversity
Sep 19, 2022

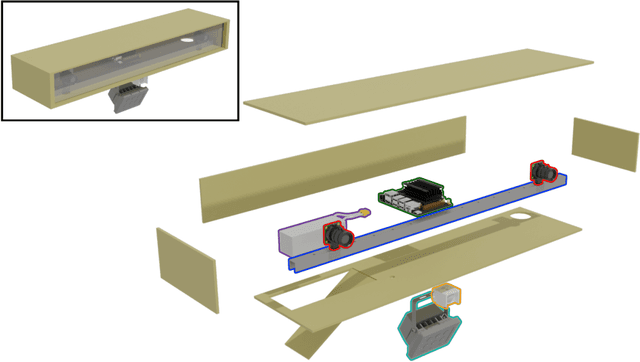

The development and application of modern technology is an essential basis for the efficient monitoring of species in natural habitats and landscapes to trace the development of ecosystems, species communities, and populations, and to analyze reasons of changes. For estimating animal abundance using methods such as camera trap distance sampling, spatial information of natural habitats in terms of 3D (three-dimensional) measurements is crucial. Additionally, 3D information improves the accuracy of animal detection using camera trapping. This study presents a novel approach to 3D camera trapping featuring highly optimized hardware and software. This approach employs stereo vision to infer 3D information of natural habitats and is designated as StereO CameRA Trap for monitoring of biodivErSity (SOCRATES). A comprehensive evaluation of SOCRATES shows not only a $3.23\%$ improvement in animal detection (bounding box $\text{mAP}_{75}$) but also its superior applicability for estimating animal abundance using camera trap distance sampling. The software and documentation of SOCRATES is provided at https://github.com/timmh/socrates
Extreme Gradient Boosting for Yield Estimation compared with Deep Learning Approaches
Aug 26, 2022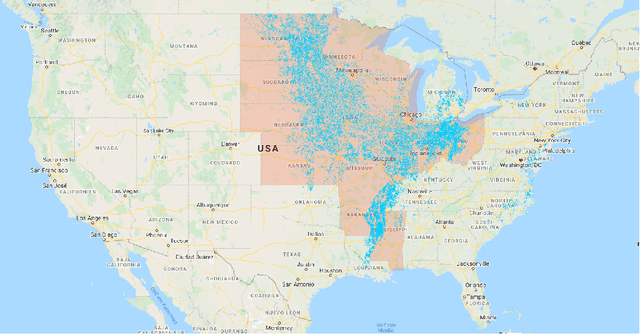
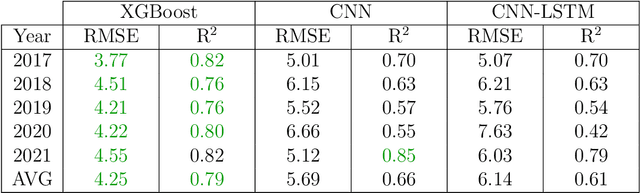
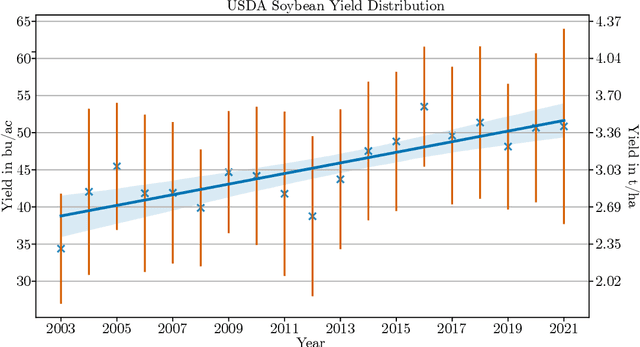
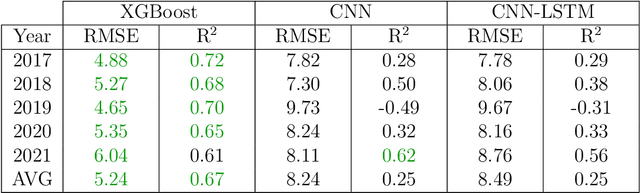
Accurate prediction of crop yield before harvest is of great importance for crop logistics, market planning, and food distribution around the world. Yield prediction requires monitoring of phenological and climatic characteristics over extended time periods to model the complex relations involved in crop development. Remote sensing satellite images provided by various satellites circumnavigating the world are a cheap and reliable way to obtain data for yield prediction. The field of yield prediction is currently dominated by Deep Learning approaches. While the accuracies reached with those approaches are promising, the needed amounts of data and the ``black-box'' nature can restrict the application of Deep Learning methods. The limitations can be overcome by proposing a pipeline to process remote sensing images into feature-based representations that allow the employment of Extreme Gradient Boosting (XGBoost) for yield prediction. A comparative evaluation of soybean yield prediction within the United States shows promising prediction accuracies compared to state-of-the-art yield prediction systems based on Deep Learning. Feature importances expose the near-infrared spectrum of light as an important feature within our models. The reported results hint at the capabilities of XGBoost for yield prediction and encourage future experiments with XGBoost for yield prediction on other crops in regions all around the world.
Distance Estimation and Animal Tracking for Wildlife Camera Trapping
Feb 09, 2022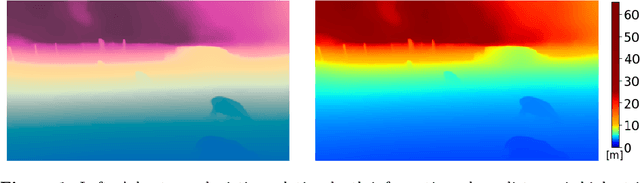


The ongoing biodiversity crysis calls for accurate estimation of animal density and abundance to identify, for example, sources of biodiversity decline and effectiveness of conservation interventions. Camera traps together with abundance estimation methods are often employed for this purpose. The necessary distances between camera and observed animal are traditionally derived in a laborious, fully manual or semi-automatic process. Both approaches require reference image material, which is both difficult to acquire and not available for existing datasets. In this study, we propose a fully automatic approach to estimate camera-to-animal distances, based on monocular depth estimation (MDE), and without the need of reference image material. We leverage state-of-the-art relative MDE and a novel alignment procedure to estimate metric distances. We evaluate the approach on a zoo scenario dataset unseen during training. We achieve a mean absolute distance estimation error of only 0.9864 meters at a precision of 90.3% and recall of 63.8%, while completely eliminating the previously required manual effort for biodiversity researchers. The code will be made available.
Overcoming the Distance Estimation Bottleneck in Camera Trap Distance Sampling
May 10, 2021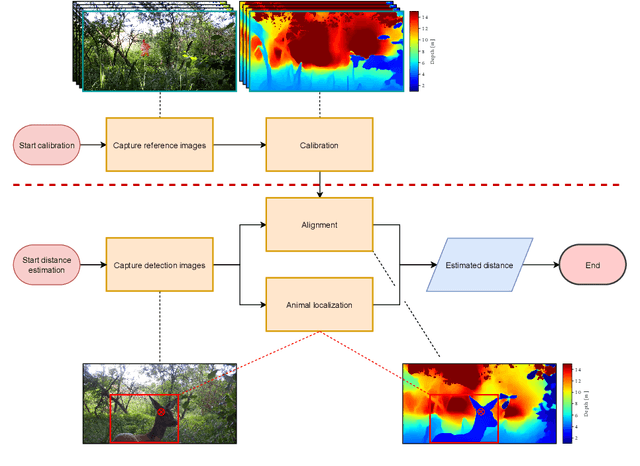

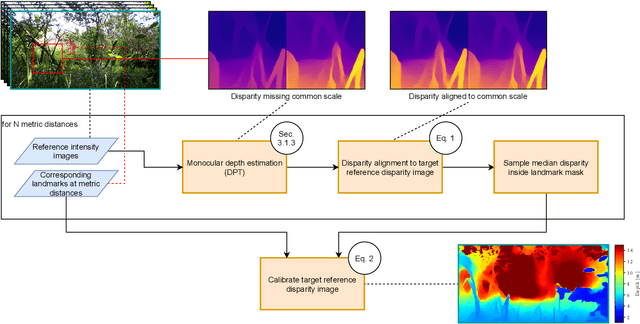
Biodiversity crisis is still accelerating. Estimating animal abundance is of critical importance to assess, for example, the consequences of land-use change and invasive species on species composition, or the effectiveness of conservation interventions. Camera trap distance sampling (CTDS) is a recently developed monitoring method providing reliable estimates of wildlife population density and abundance. However, in current applications of CTDS, the required camera-to-animal distance measurements are derived by laborious, manual and subjective estimation methods. To overcome this distance estimation bottleneck in CTDS, this study proposes a completely automatized workflow utilizing state-of-the-art methods of image processing and pattern recognition.
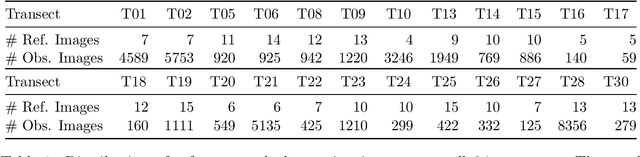
Automated Identification of Vulnerable Devices in Networks using Traffic Data and Deep Learning
Feb 16, 2021
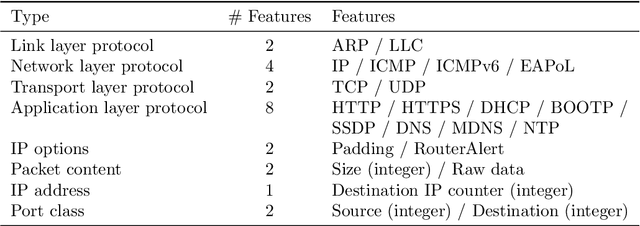
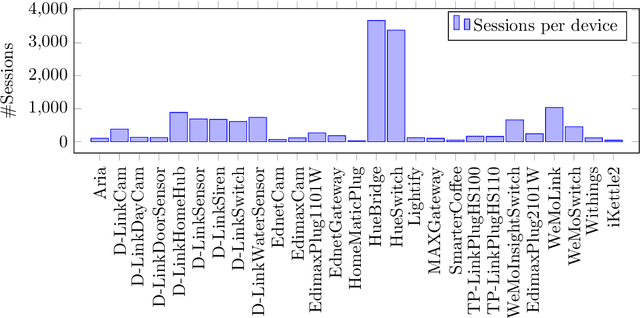
Many IoT devices are vulnerable to attacks due to flawed security designs and lacking mechanisms for firmware updates or patches to eliminate the security vulnerabilities. Device-type identification combined with data from vulnerability databases can pinpoint vulnerable IoT devices in a network and can be used to constrain the communications of vulnerable devices for preventing damage. In this contribution, we present and evaluate two deep learning approaches to the reliable IoT device-type identification, namely a recurrent and a convolutional network architecture. Both deep learning approaches show accuracies of 97% and 98%, respectively, and thereby outperform an up-to-date IoT device-type identification approach using hand-crafted fingerprint features obtaining an accuracy of 82%. The runtime performance for the IoT identification of both deep learning approaches outperforms the hand-crafted approach by three magnitudes. Finally, importance metrics explain the results of both deep learning approaches in terms of the utilization of the analyzed traffic data flow.
Exploiting Depth Information for Wildlife Monitoring
Feb 10, 2021

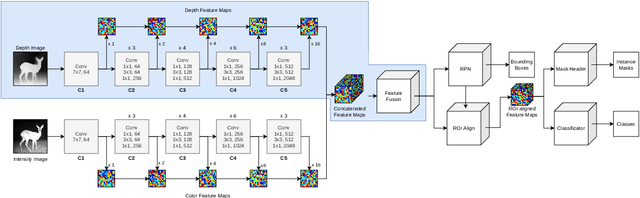

Camera traps are a proven tool in biology and specifically biodiversity research. However, camera traps including depth estimation are not widely deployed, despite providing valuable context about the scene and facilitating the automation of previously laborious manual ecological methods. In this study, we propose an automated camera trap-based approach to detect and identify animals using depth estimation. To detect and identify individual animals, we propose a novel method D-Mask R-CNN for the so-called instance segmentation which is a deep learning-based technique to detect and delineate each distinct object of interest appearing in an image or a video clip. An experimental evaluation shows the benefit of the additional depth estimation in terms of improved average precision scores of the animal detection compared to the standard approach that relies just on the image information. This novel approach was also evaluated in terms of a proof-of-concept in a zoo scenario using an RGB-D camera trap.
Image-based Automated Species Identification: Can Virtual Data Augmentation Overcome Problems of Insufficient Sampling?
Oct 18, 2020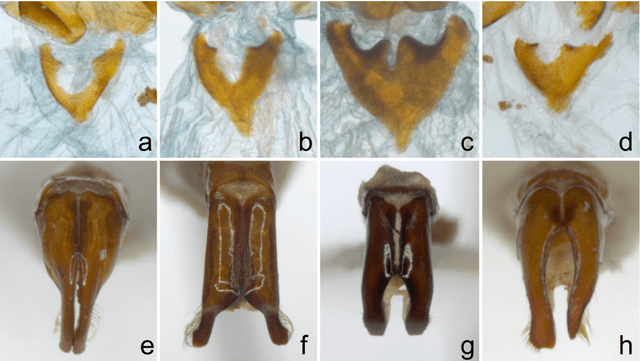

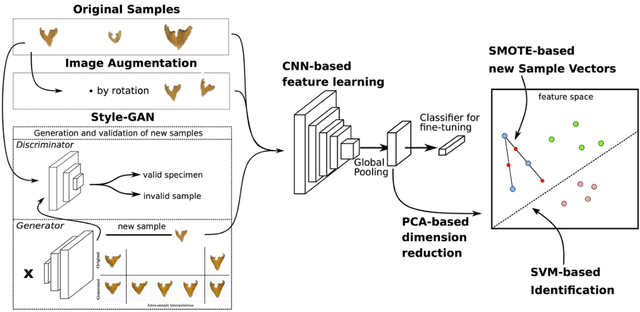

Automated species identification and delimitation is challenging, particularly in rare and thus often scarcely sampled species, which do not allow sufficient discrimination of infraspecific versus interspecific variation. Typical problems arising from either low or exaggerated interspecific morphological differentiation are best met by automated methods of machine learning that learn efficient and effective species identification from training samples. However, limited infraspecific sampling remains a key challenge also in machine learning. 1In this study, we assessed whether a two-level data augmentation approach may help to overcome the problem of scarce training data in automated visual species identification. The first level of visual data augmentation applies classic approaches of data augmentation and generation of faked images using a GAN approach. Descriptive feature vectors are derived from bottleneck features of a VGG-16 convolutional neural network (CNN) that are then stepwise reduced in dimensionality using Global Average Pooling and PCA to prevent overfitting. The second level of data augmentation employs synthetic additional sampling in feature space by an oversampling algorithm in vector space (SMOTE). Applied on two challenging datasets of scarab beetles (Coleoptera), our augmentation approach outperformed a non-augmented deep learning baseline approach as well as a traditional 2D morphometric approach (Procrustes analysis).
An Adaptive Approach for Automated Grapevine Phenotyping using VGG-based Convolutional Neural Networks
Nov 23, 2018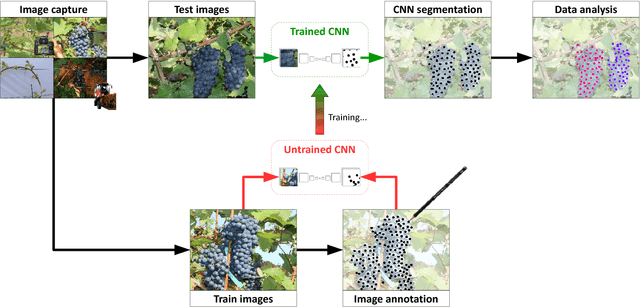
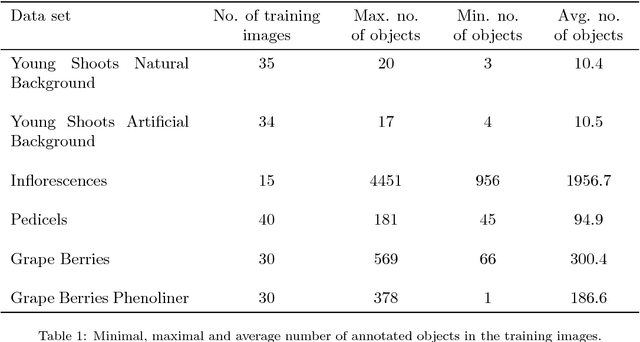

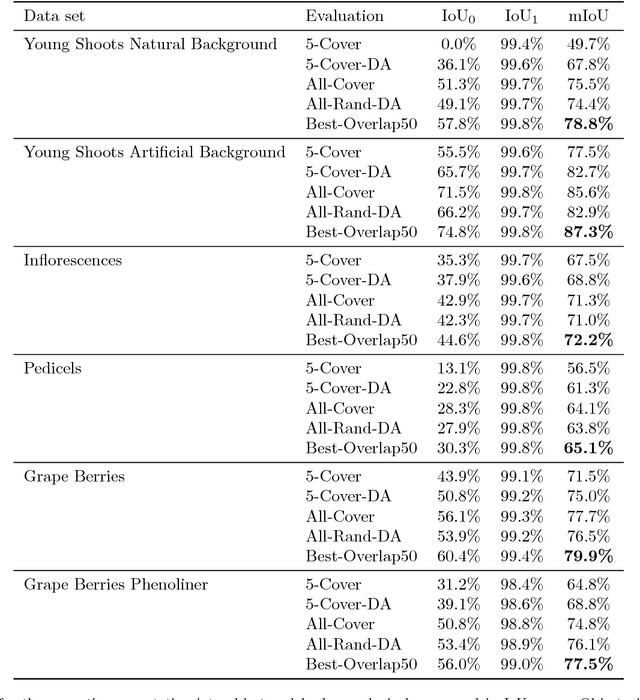
In (grapevine) breeding programs and research, periodic phenotyping and multi-year monitoring of different grapevine traits, like growth or yield, is needed especially in the field. This demand imply objective, precise and automated methods using sensors and adaptive software. This work presents a proof-of-concept analyzing RGB images of different growth stages of grapevines with the aim to detect and quantify promising plant organs which are related to yield. The input images are segmented by a Fully Convolutional Neural Network (FCN) into object and background pixels. The objects are plant organs like young shoots, pedicels, flower buds or grapes, which are principally suitable for yield estimation. In the ground truth of the training images, each object is separately annotated as a connected segment of object pixels, which enables end-to-end learning of the object features. Based on the CNN-based segmentation, the number of objects is determined by detecting and counting connected components of object pixels using region labeling. In an evaluation on six different data sets, the system achieves an IoU of up to 87.3% for the segmentation and an F1 score of up to 88.6% for the object detection. The reason for the good results is the combination of a powerful CNN architecture and very precise and accurate image annotations.