 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-based Automated Species Identification: Can Virtual Data Augmentation Overcome Problems of Insufficient Sampling?
Oct 18, 2020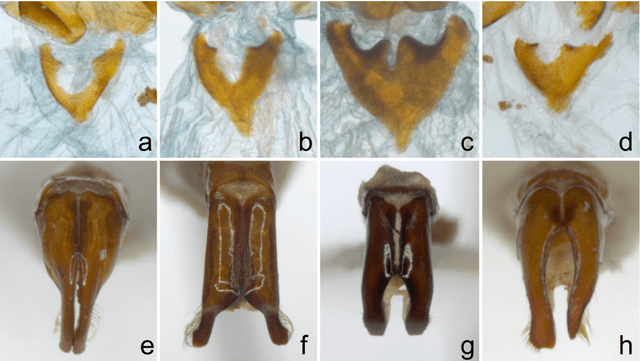

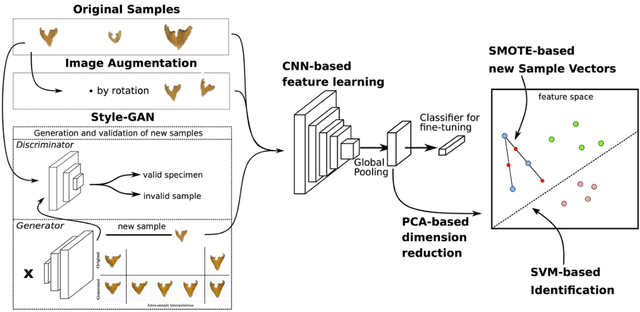

Automated species identification and delimitation is challenging, particularly in rare and thus often scarcely sampled species, which do not allow sufficient discrimination of infraspecific versus interspecific variation. Typical problems arising from either low or exaggerated interspecific morphological differentiation are best met by automated methods of machine learning that learn efficient and effective species identification from training samples. However, limited infraspecific sampling remains a key challenge also in machine learning. 1In this study, we assessed whether a two-level data augmentation approach may help to overcome the problem of scarce training data in automated visual species identification. The first level of visual data augmentation applies classic approaches of data augmentation and generation of faked images using a GAN approach. Descriptive feature vectors are derived from bottleneck features of a VGG-16 convolutional neural network (CNN) that are then stepwise reduced in dimensionality using Global Average Pooling and PCA to prevent overfitting. The second level of data augmentation employs synthetic additional sampling in feature space by an oversampling algorithm in vector space (SMOTE). Applied on two challenging datasets of scarab beetles (Coleoptera), our augmentation approach outperformed a non-augmented deep learning baseline approach as well as a traditional 2D morphometric approach (Procrustes analysis).