 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Mappings for Continuous Bilateral Teleoperation
Dec 11, 2020
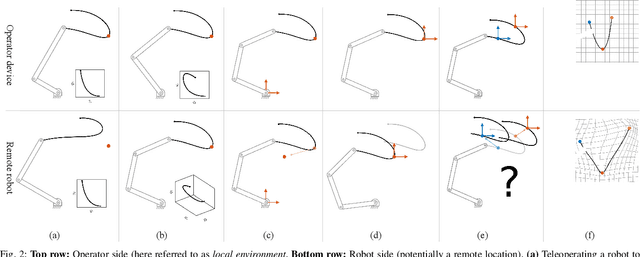


Mapping operator motions to a robot is a key problem in teleoperation. Due to differences between workspaces, such as object locations, it is particularly challenging to derive smooth motion mappings that fulfill different goals (e.g. picking objects with different poses on the two sides or passing through key points). Indeed, most state-of-the-art methods rely on mode switches, leading to a discontinuous, low-transparency experience. In this paper, we propose a unified formulation for position, orientation and velocity mappings based on the poses of objects of interest in the operator and robot workspaces. We apply it in the context of bilateral teleoperation. Two possible implementations to achieve the proposed mappings are studied: an iterative approach based on locally-weighted translations and rotations, and a neural network approach. Evaluations are conducted both in simulation and using two torque-controlled Franka Emika Panda robots. Our results show that, despite longer training times, the neural network approach provides faster mapping evaluations and lower interaction forces for the operator, which are crucial for continuous, real-time teleoperation.
Generative Adversarial Network to Learn Valid Distributions of Robot Configurations for Inverse Kinematics and Constrained Motion Planning
Nov 11, 2020
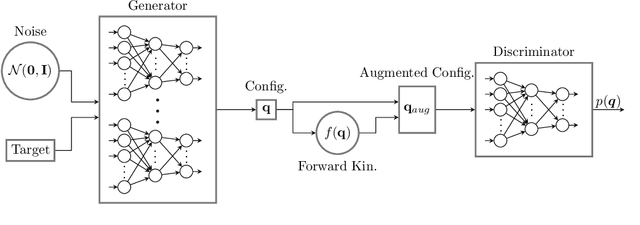
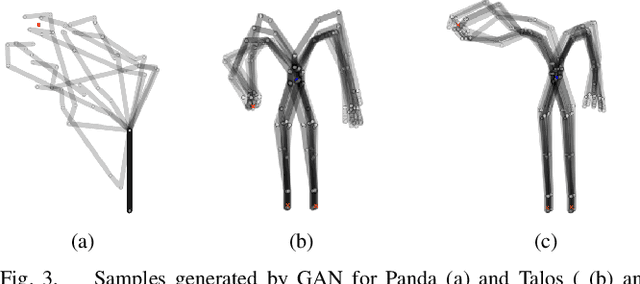

In high dimensional robotic system, the manifold of the valid configuration space often has complex shape, especially under constraints such as end-effector orientation, static stability, and obstacles. We propose a generative adversarial network approach to learn the distribution of valid robot configurations. It can generate configurations that are close to the constraint manifold. We present two applications of this method. First, by learning the conditional distribution with respect to the desired end-effector position, we can do fast inverse kinematics even for very high degrees-of-freedom (DoF) systems. Then, it can be used to generate samples in sampling based constrained motion planning algorithms to reduce the necessary projection steps, speeding up computation. We validate the approach in simulation using the 7-DoF Panda manipulator and the 28-DoF humanoid robot Talos.
Generative adversarial training of product of policies for robust and adaptive movement primitives
Nov 06, 2020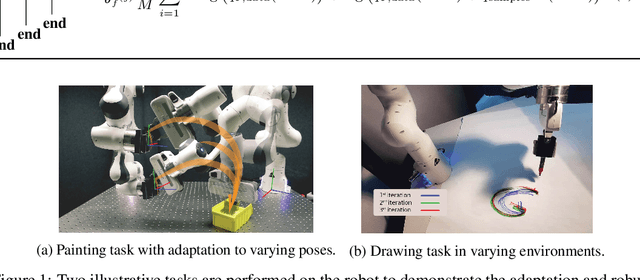
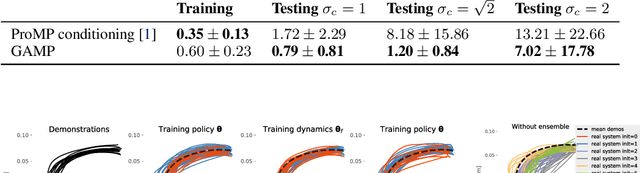
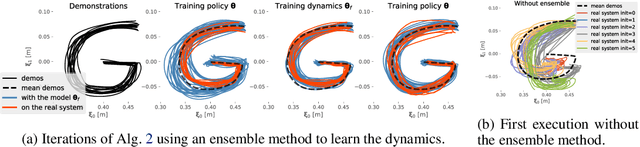

In learning from demonstrations, many generative models of trajectories make simplifying assumptions of independence. Correctness is sacrificed in the name of tractability and speed of the learning phase. The ignored dependencies, which often are the kinematic and dynamic constraints of the system, are then only restored when synthesizing the motion, which introduces possibly heavy distortions. In this work, we propose to use those approximate trajectory distributions as close-to-optimal discriminators in the popular generative adversarial framework to stabilize and accelerate the learning procedure. The two problems of adaptability and robustness are addressed with our method. In order to adapt the motions to varying contexts, we propose to use a product of Gaussian policies defined in several parametrized task spaces. Robustness to perturbations and varying dynamics is ensured with the use of stochastic gradient descent and ensemble methods to learn the stochastic dynamics. Two experiments are performed on a 7-DoF manipulator to validate the approach.
Learning from demonstration using products of experts: applications to manipulation and task prioritization
Oct 07, 2020

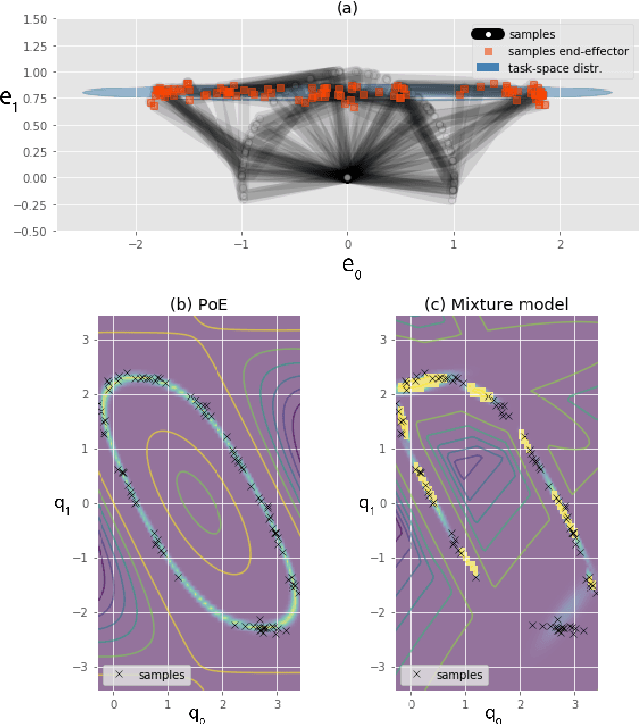

Probability distributions are key components of many learning from demonstration (LfD) approaches. While the configuration of a manipulator is defined by its joint angles, poses are often best explained within several task spaces. In many approaches, distributions within relevant task spaces are learned independently and only combined at the control level. This simplification implies several problems that are addressed in this work. We show that the fusion of models in different task spaces can be expressed as a product of experts (PoE), where the probabilities of the models are multiplied and renormalized so that it becomes a proper distribution of joint angles. Multiple experiments are presented to show that learning the different models jointly in the PoE framework significantly improves the quality of the model. The proposed approach particularly stands out when the robot has to learn competitive or hierarchical objectives. Training the model jointly usually relies on contrastive divergence, which requires costly approximations that can affect performance. We propose an alternative strategy using variational inference and mixture model approximations. In particular, we show that the proposed approach can be extended to PoE with a nullspace structure (PoENS), where the model is able to recover tasks that are masked by the resolution of higher-level objectives.
Active Improvement of Control Policies with Bayesian Gaussian Mixture Model
Aug 06, 2020
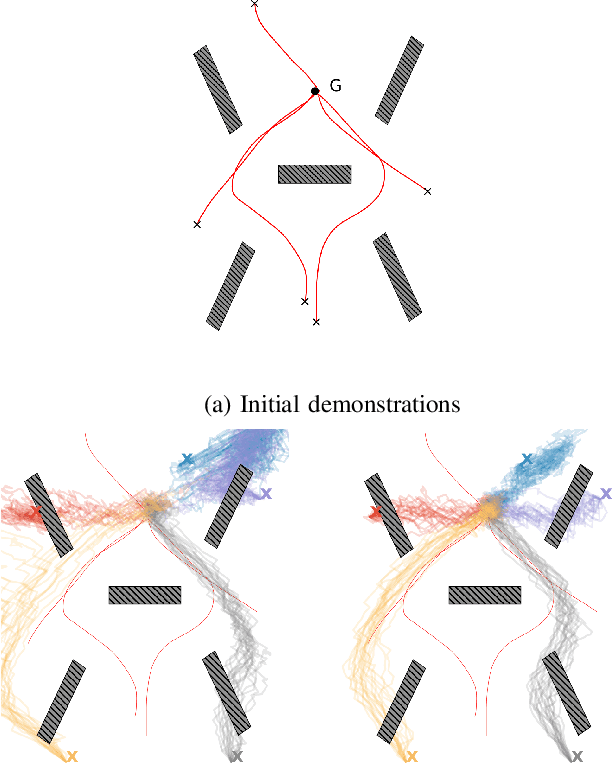

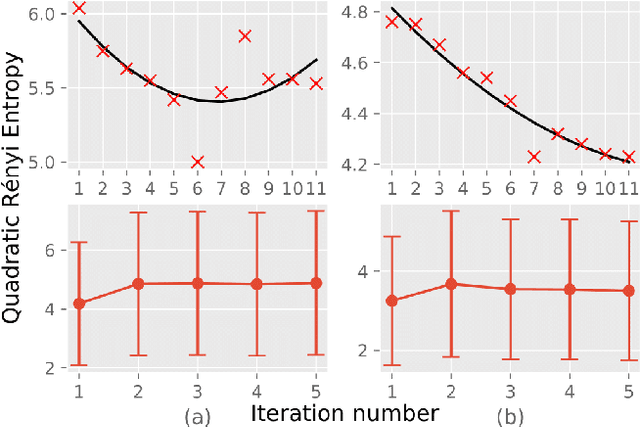
Learning from demonstration (LfD) is an intuitive framework allowing non-expert users to easily (re-)program robots. However, the quality and quantity of demonstrations have a great influence on the generalization performances of LfD approaches. In this paper, we introduce a novel active learning framework in order to improve the generalization capabilities of control policies. The proposed approach is based on the epistemic uncertainties of Bayesian Gaussian mixture models (BGMMs). We determine the new query point location by optimizing a closed-form information-density cost based on the quadratic R\'enyi entropy. Furthermore, to better represent uncertain regions and to avoid local optima problem, we propose to approximate the active learning cost with a Gaussian mixture model (GMM). We demonstrate our active learning framework in the context of a reaching task in a cluttered environment with an illustrative toy example and a real experiment with a Panda robot.
Interaction-limited Inverse Reinforcement Learning
Jul 01, 2020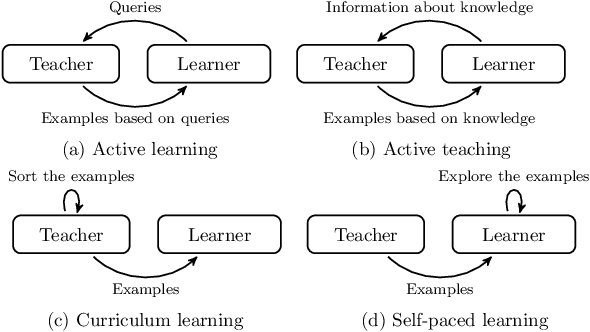
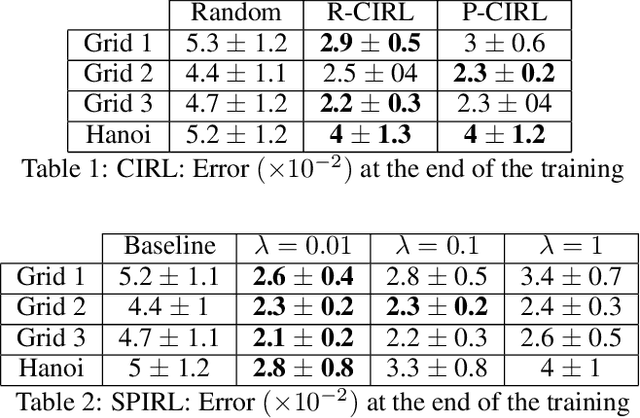
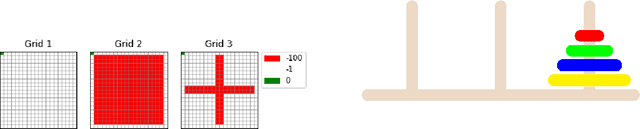
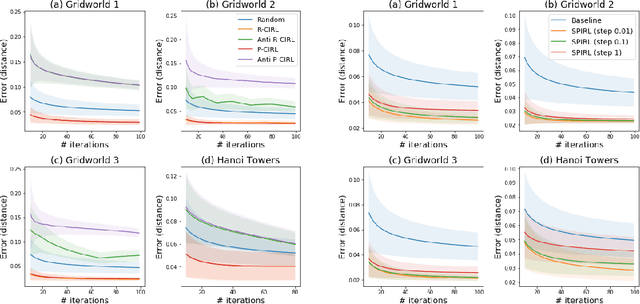
This paper proposes an inverse reinforcement learning (IRL) framework to accelerate learning when the learner-teacher \textit{interaction} is \textit{limited} during training. Our setting is motivated by the realistic scenarios where a helpful teacher is not available or when the teacher cannot access the learning dynamics of the student. We present two different training strategies: Curriculum Inverse Reinforcement Learning (CIRL) covering the teacher's perspective, and Self-Paced Inverse Reinforcement Learning (SPIRL) focusing on the learner's perspective. Using experiments in simulations and experiments with a real robot learning a task from a human demonstrator, we show that our training strategies can allow a faster training than a random teacher for CIRL and than a batch learner for SPIRL.
Memory of Motion for Warm-starting Trajectory Optimization
Jul 02, 2019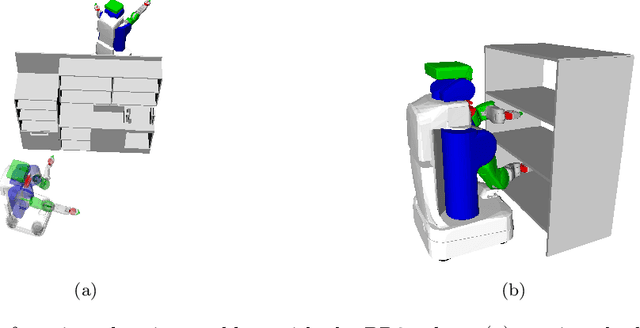

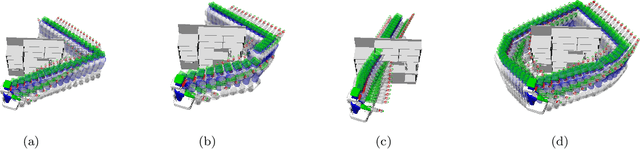
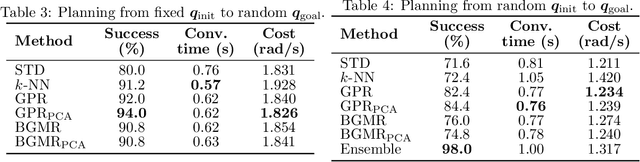
Trajectory optimization for motion planning requires a good initial guess to obtain good performance. In our proposed approach, we build a memory of motion based on a database of robot paths to provide a good initial guess online. The memory of motion relies on function approximators and dimensionality reduction techniques to learn the mapping between the task and the robot paths. Three function approximators are compared: k-Nearest Neighbor, Gaussian Process Regression, and Bayesian Gaussian Mixture Regression. In addition, we show that the usage of the memory of motion can be improved by using an ensemble method, and that the memory can also be used as a metric to choose between several possible goals. We demonstrate the proposed approach with the motion planning on a dual-arm PR2 robot.
Variational Inference with Mixture Model Approximation: Robotic Applications
May 23, 2019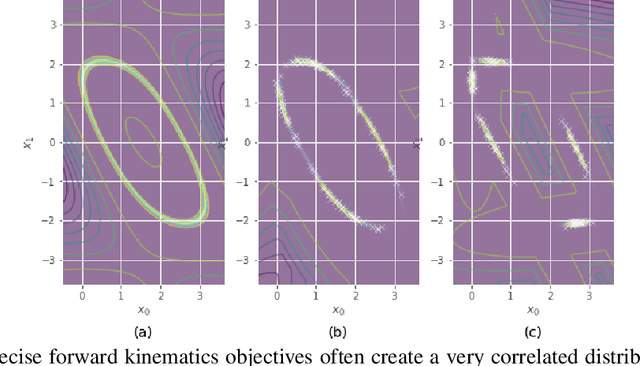
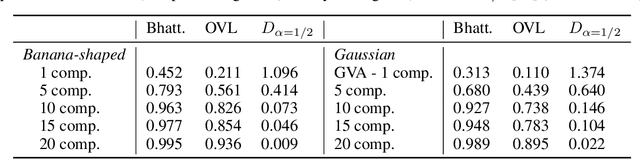

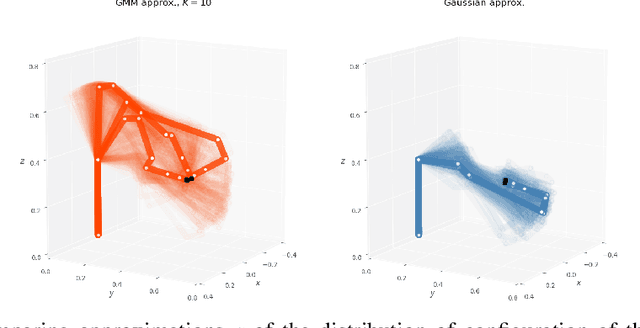
We propose a method to approximate the distribution of robot configurations satisfying multiple objectives. Our approach uses Variational Inference, a popular method in Bayesian computation, which has several advantages over sampling-based techniques. To be able to represent the complex and multimodal distribution of configurations, we propose to use a mixture model as approximate distribution, an approach that has gained popularity recently. In this work, we show the interesting properties of this approach and how it can be applied to a range of problems.
Bayesian Gaussian mixture model for robotic policy imitation
Apr 24, 2019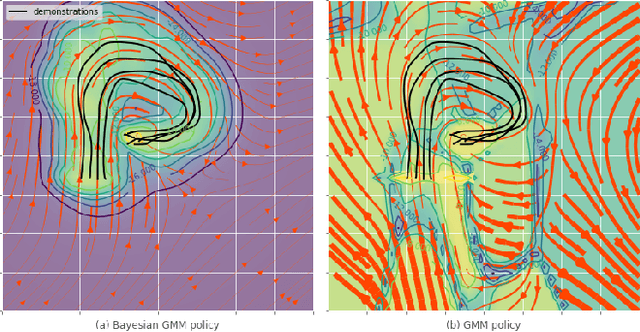
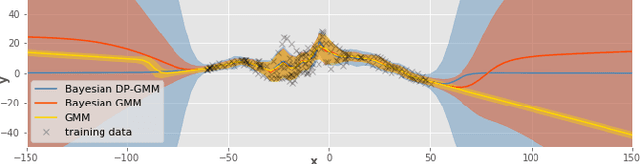
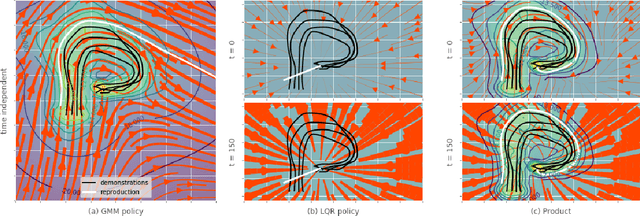
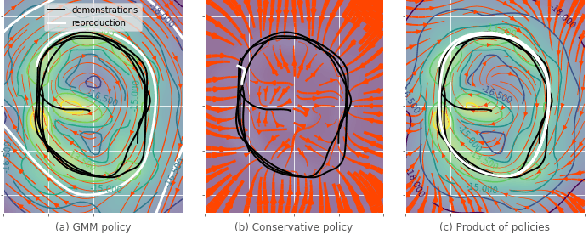
A common approach to learn robotic skills is to imitate a policy demonstrated by a supervisor. One of the existing problems is that, due to the compounding of small errors and perturbations, the robot may leave the states where demonstrations were given. If no strategy is employed to provide a guarantee on how the robot will behave when facing unknown states, catastrophic outcomes can happen. An appealing approach is to use Bayesian methods, which offer a quantification of the action uncertainty given the state. Bayesian methods are usually more computationally demanding and require more complex design choices than their non-Bayesian alternatives, which limits their application. In this work, we present a Bayesian method that is both simple to set up, computationally efficient and that can adapt to a wide range of problems. These advantages make this method very convenient for imitation of robotic manipulation tasks in the continuous domain. We exploit the provided uncertainty to fuse the imitation policy with other policies. The approach is validated on a Panda robot with three tasks using different control input/state pairs.
Improving dual-arm assembly by master-slave compliance
Feb 19, 2019
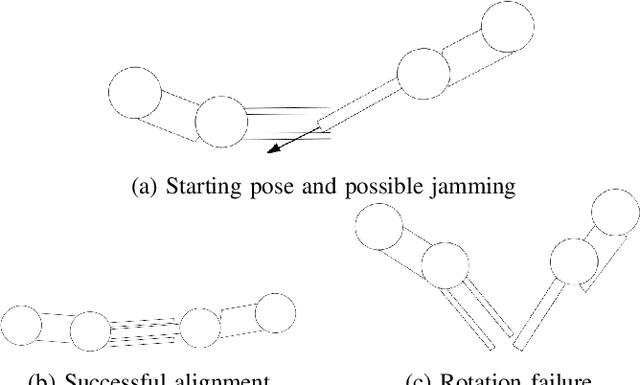
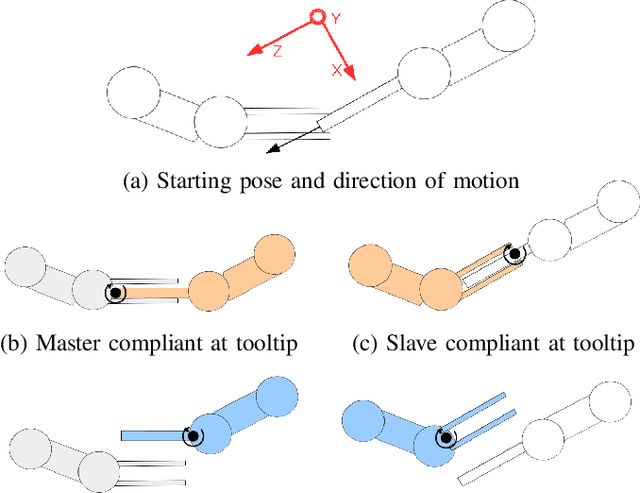
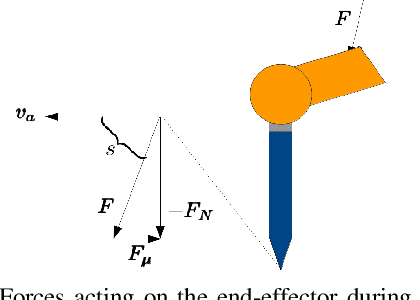
In this paper we show how different choices regarding compliance affect a dual-arm assembly task. In addition, we present how the compliance parameters can be learned from a human demonstration. Compliant motions can be used in assembly tasks to mitigate pose errors originating from, for example, inaccurate grasping. We present analytical background and accompanying experimental results on how to choose the center of compliance to enhance the convergence region of an alignment task. Then we present the possible ways of choosing the compliant axes for accomplishing alignment in a scenario where orientation error is present. We show that an earlier presented Learning from Demonstration method can be used to learn motion and compliance parameters of an impedance controller for both manipulators. The learning requires a human demonstration with a single teleoperated manipulator only, easing the execution of demonstration and enabling usage of manipulators at difficult locations as well. Finally, we experimentally verify our claim that having both manipulators compliant in both rotation and translation can accomplish the alignment task with less total joint motions and in shorter time than moving one manipulator only. In addition, we show that the learning method produces the parameters that achieve the best results in our experiments.