 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Improvement of Control Policies with Bayesian Gaussian Mixture Model
Paper and Code
Aug 06, 2020
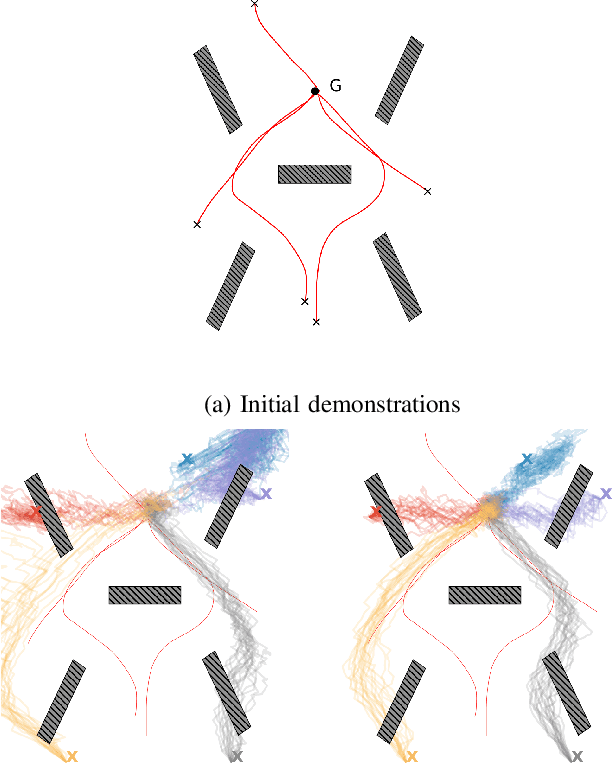

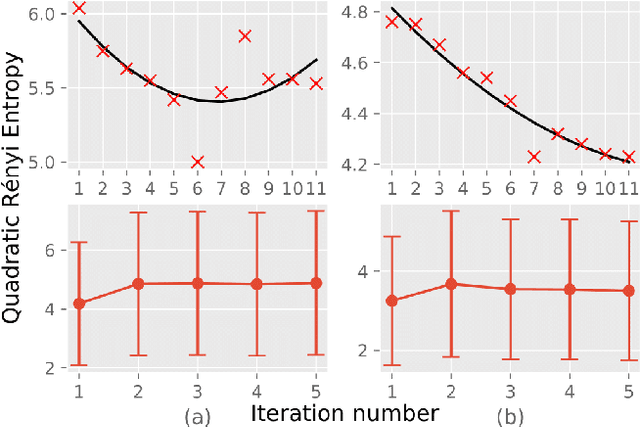
Learning from demonstration (LfD) is an intuitive framework allowing non-expert users to easily (re-)program robots. However, the quality and quantity of demonstrations have a great influence on the generalization performances of LfD approaches. In this paper, we introduce a novel active learning framework in order to improve the generalization capabilities of control policies. The proposed approach is based on the epistemic uncertainties of Bayesian Gaussian mixture models (BGMMs). We determine the new query point location by optimizing a closed-form information-density cost based on the quadratic R\'enyi entropy. Furthermore, to better represent uncertain regions and to avoid local optima problem, we propose to approximate the active learning cost with a Gaussian mixture model (GMM). We demonstrate our active learning framework in the context of a reaching task in a cluttered environment with an illustrative toy example and a real experiment with a Panda robot.