 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating medical screening questionnaires through analysis of social media data
Nov 17, 2024Screening questionnaires are used in medicine as a diagnostic aid. Creating them is a long and expensive process, which could potentially be improved through analysis of social media posts related to symptoms and behaviors prior to diagnosis. Here we show a preliminary investigation into the feasibility of generating screening questionnaires for a given medical condition from social media postings. The method first identifies a cohort of relevant users through their posts in dedicated patient groups and a control group of users who reported similar symptoms but did not report being diagnosed with the condition of interest. Posts made prior to diagnosis are used to generate decision rules to differentiate between the different groups, by clustering symptoms mentioned by these users and training a decision tree to differentiate between the two groups. We validate the generated rules by correlating them with scores given by medical doctors to matching hypothetical cases. We demonstrate the proposed method by creating questionnaires for three conditions (endometriosis, lupus, and gout) using the data of several hundreds of users from Reddit. These questionnaires were then validated by medical doctors. The average Pearson's correlation between the latter's scores and the decision rules were 0.58 (endometriosis), 0.40 (lupus) and 0.27 (gout). Our results suggest that the process of questionnaire generation can be, at least partly, automated. These questionnaires are advantageous in that they are based on real-world experience but are currently lacking in their ability to capture the context, duration, and timing of symptoms.
Inferring Unfairness and Error from Population Statistics in Binary and Multiclass Classification
Jun 07, 2022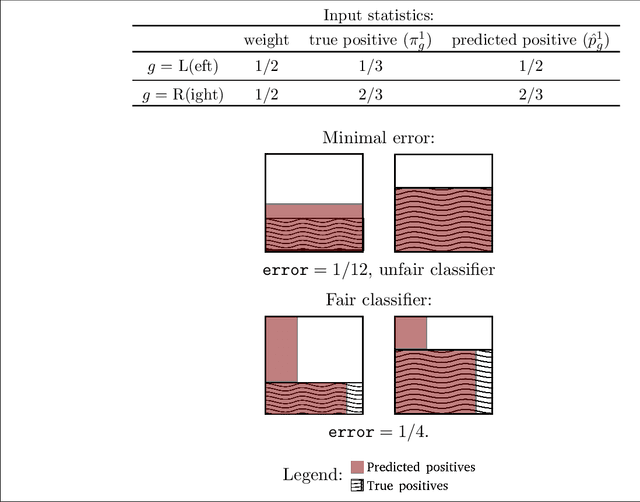
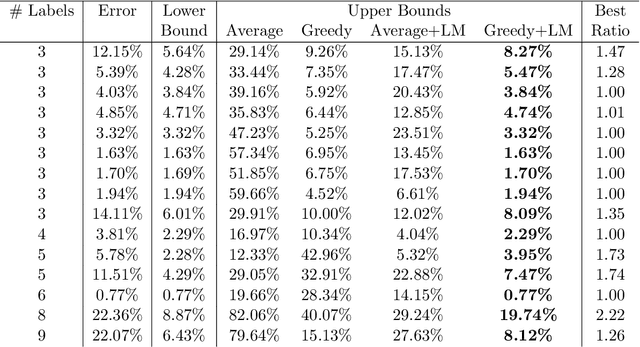
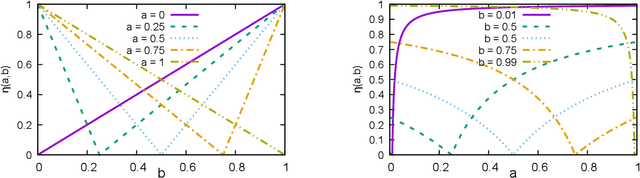
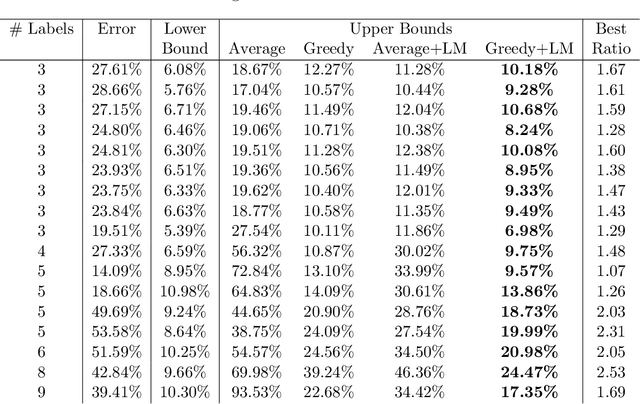
We propose methods for making inferences on the fairness and accuracy of a given classifier, using only aggregate population statistics. This is necessary when it is impossible to obtain individual classification data, for instance when there is no access to the classifier or to a representative individual-level validation set. We study fairness with respect to the equalized odds criterion, which we generalize to multiclass classification. We propose a measure of unfairness with respect to this criterion, which quantifies the fraction of the population that is treated unfairly. We then show how inferences on the unfairness and error of a given classifier can be obtained using only aggregate label statistics such as the rate of prediction of each label in each sub-population, as well as the true rate of each label. We derive inference procedures for binary classifiers and for multiclass classifiers, for the case where confusion matrices in each sub-population are known, and for the significantly more challenging case where they are unknown. We report experiments on data sets representing diverse applications, which demonstrate the effectiveness and the wide range of possible uses of the proposed methodology.
Algorithmic Rewriting of Health-Related Ads to Improve their Performance
Nov 03, 2019
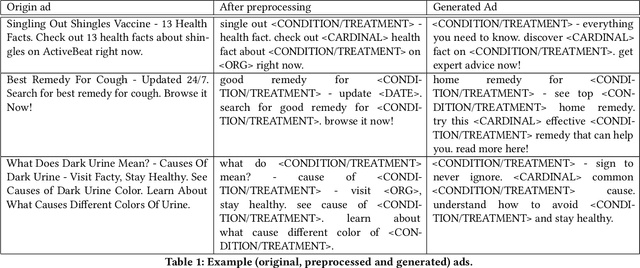

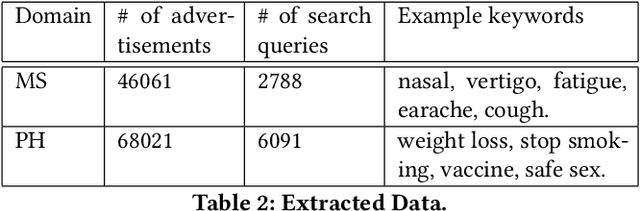
Search advertising is one of the most commonly-used methods of advertising. Past work has shown that search advertising can be employed to improve health by eliciting positive behavioral change. However, writing effective advertisements requires expertise and (possible expensive) experimentation, both of which may not be available to public health authorities wishing to elicit such behavioral changes, especially when dealing with a public health crises such as epidemic outbreaks. Here we develop an algorithm which builds on past advertising data to train a sequence-to-sequence Deep Neural Network which "translates" advertisements into optimized ads that are more likely to be clicked. The network is trained using more than 114 thousands ads shown on Microsoft Advertising. We apply this translator to two health related domains: Medical Symptoms (MS) and Preventative Healthcare (PH) and measure the improvements in click-through rates (CTR). Our experiments show that the generated ads are predicted to have higher CTR in 81% of MS ads and 76% of PH ads. To understand the differences between the generated ads and the original ones we develop estimators for the affective attributes of the ads. We show that the generated ads contain more calls-to-action and that they reflect higher valence (36% increase) and higher arousal (87%) on a sample of 1000 ads. Finally, we run an advertising campaign where 10 random ads and their rephrased versions from each of the domains are run in parallel. We show an average improvement in CTR of 68% for the generated ads compared to the original ads. Our results demonstrate the ability to automatically optimize advertisement for the health domain. We believe that our work offers health authorities an improved ability to help nudge people towards healthier behaviors while saving the time and cost needed to optimize advertising campaigns.
Privacy, altruism, and experience: Estimating the perceived value of Internet data for medical uses
Jun 20, 2019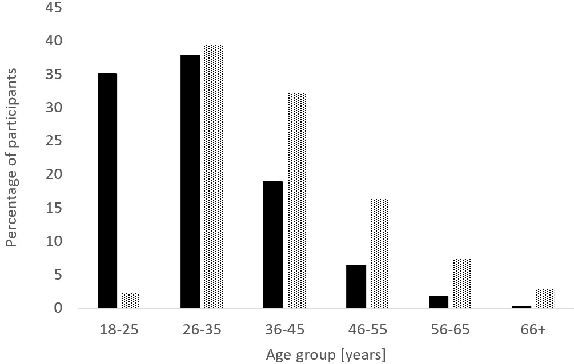

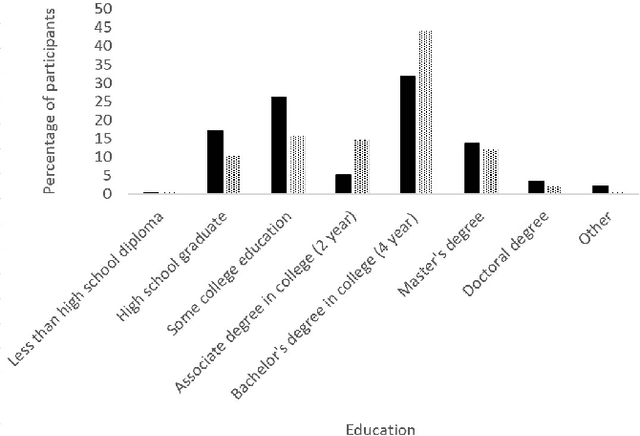
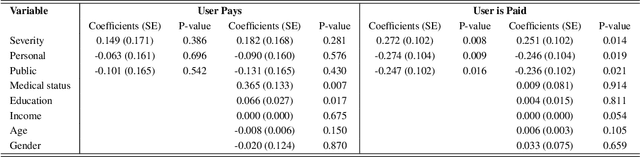
People increasingly turn to the Internet when they have a medical condition. The data they create during this process is a valuable source for medical research and for future health services. However, utilizing these data could come at a cost to user privacy. Thus, it is important to balance the perceived value that users assign to these data with the value of the services derived from them. Here we describe experiments where methods from Mechanism Design were used to elicit a truthful valuation from users for their Internet data and for services to screen people for medical conditions. In these experiments, 880 people from around the world were asked to participate in an auction to provide their data for uses differing in their contribution to the participant, to society, and in the disease they addressed. Some users were offered monetary compensation for their participation, while others were asked to pay to participate. Our findings show that 99\% of people were willing to contribute their data in exchange for monetary compensation and an analysis of their data, while 53\% were willing to pay to have their data analyzed. The average perceived value users assigned to their data was estimated at US\$49. Their value to screen them for a specific cancer was US\$22 while the value of this service offered to the general public was US\$22. Participants requested higher compensation when notified that their data would be used to analyze a more severe condition. They were willing to pay more to have their data analyzed when the condition was more severe, when they had higher education or if they had recently experienced a serious medical condition.
Discriminative Learning of Prediction Intervals
Feb 27, 2018
In this work we consider the task of constructing prediction intervals in an inductive batch setting. We present a discriminative learning framework which optimizes the expected error rate under a budget constraint on the interval sizes. Most current methods for constructing prediction intervals offer guarantees for a single new test point. Applying these methods to multiple test points can result in a high computational overhead and degraded statistical guarantees. By focusing on expected errors, our method allows for variability in the per-example conditional error rates. As we demonstrate both analytically and empirically, this flexibility can increase the overall accuracy, or alternatively, reduce the average interval size. While the problem we consider is of a regressive flavor, the loss we use is combinatorial. This allows us to provide PAC-style, finite-sample guarantees. Computationally, we show that our original objective is NP-hard, and suggest a tractable convex surrogate. We conclude with a series of experimental evaluations.
Automatic Representation for Lifetime Value Recommender Systems
Feb 23, 2017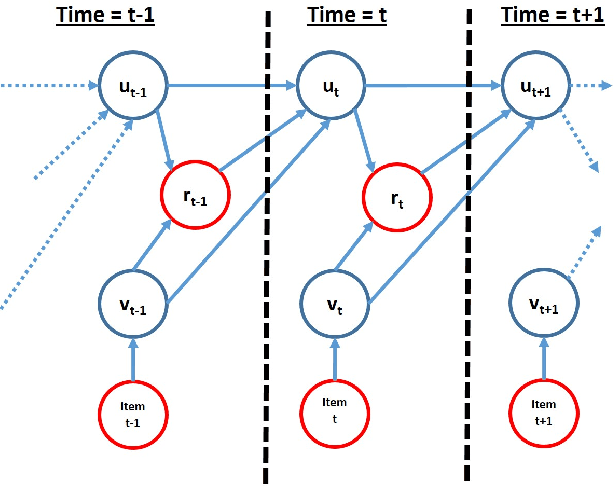

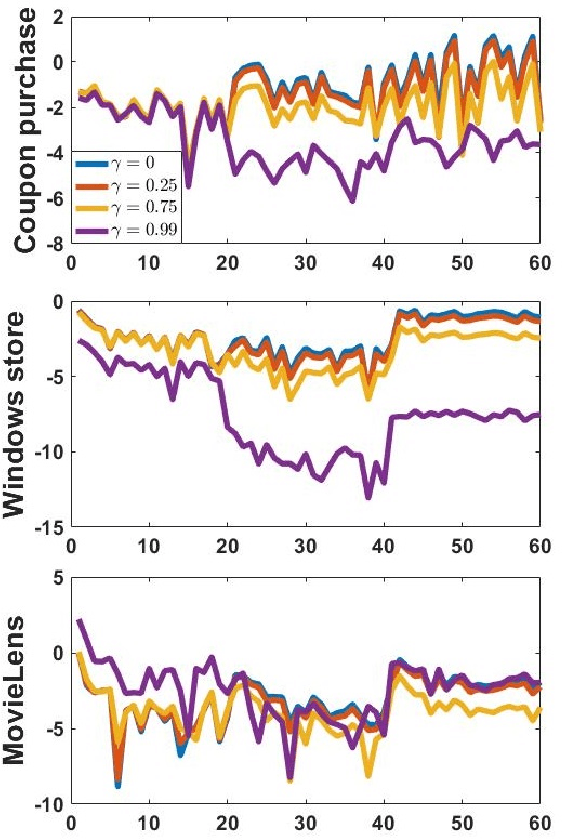
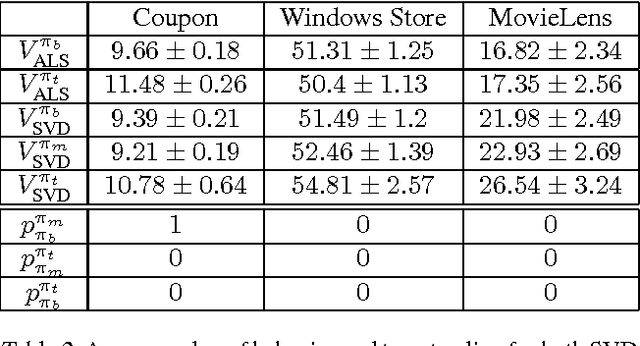
Many modern commercial sites employ recommender systems to propose relevant content to users. While most systems are focused on maximizing the immediate gain (clicks, purchases or ratings), a better notion of success would be the lifetime value (LTV) of the user-system interaction. The LTV approach considers the future implications of the item recommendation, and seeks to maximize the cumulative gain over time. The Reinforcement Learning (RL) framework is the standard formulation for optimizing cumulative successes over time. However, RL is rarely used in practice due to its associated representation, optimization and validation techniques which can be complex. In this paper we propose a new architecture for combining RL with recommendation systems which obviates the need for hand-tuned features, thus automating the state-space representation construction process. We analyze the practical difficulties in this formulation and test our solutions on batch off-line real-world recommendation data.
Predicting Counterfactuals from Large Historical Data and Small Randomized Trials
Oct 26, 2016
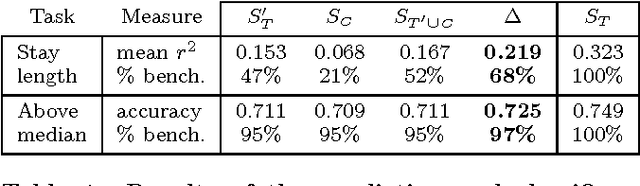
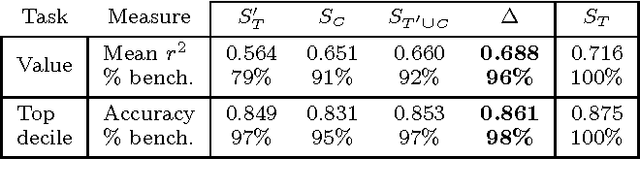

When a new treatment is considered for use, whether a pharmaceutical drug or a search engine ranking algorithm, a typical question that arises is, will its performance exceed that of the current treatment? The conventional way to answer this counterfactual question is to estimate the effect of the new treatment in comparison to that of the conventional treatment by running a controlled, randomized experiment. While this approach theoretically ensures an unbiased estimator, it suffers from several drawbacks, including the difficulty in finding representative experimental populations as well as the cost of running such trials. Moreover, such trials neglect the huge quantities of available control-condition data which are often completely ignored. In this paper we propose a discriminative framework for estimating the performance of a new treatment given a large dataset of the control condition and data from a small (and possibly unrepresentative) randomized trial comparing new and old treatments. Our objective, which requires minimal assumptions on the treatments, models the relation between the outcomes of the different conditions. This allows us to not only estimate mean effects but also to generate individual predictions for examples outside the randomized sample. We demonstrate the utility of our approach through experiments in three areas: Search engine operation, treatments to diabetes patients, and market value estimation for houses. Our results demonstrate that our approach can reduce the number and size of the currently performed randomized controlled experiments, thus saving significant time, money and effort on the part of practitioners.
A Reinforcement Learning System to Encourage Physical Activity in Diabetes Patients
May 13, 2016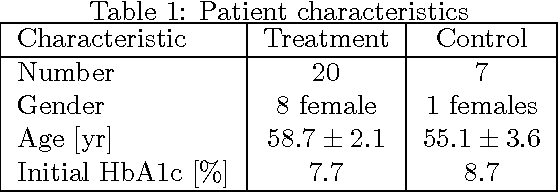
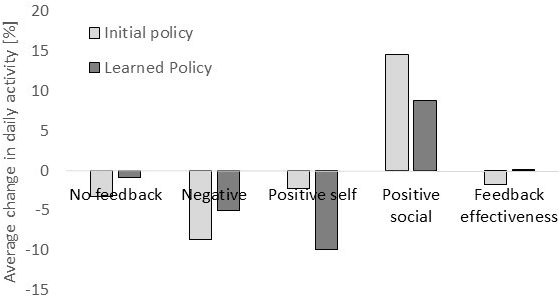

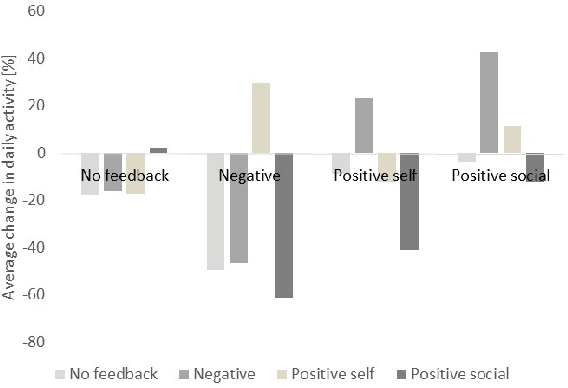
Regular physical activity is known to be beneficial to people suffering from diabetes type 2. Nevertheless, most such people are sedentary. Smartphones create new possibilities for helping people to adhere to their physical activity goals, through continuous monitoring and communication, coupled with personalized feedback. We provided 27 sedentary diabetes type 2 patients with a smartphone-based pedometer and a personal plan for physical activity. Patients were sent SMS messages to encourage physical activity between once a day and once per week. Messages were personalized through a Reinforcement Learning (RL) algorithm which optimized messages to improve each participant's compliance with the activity regimen. The RL algorithm was compared to a static policy for sending messages and to weekly reminders. Our results show that participants who received messages generated by the RL algorithm increased the amount of activity and pace of walking, while the control group patients did not. Patients assigned to the RL algorithm group experienced a superior reduction in blood glucose levels (HbA1c) compared to control policies, and longer participation caused greater reductions in blood glucose levels. The learning algorithm improved gradually in predicting which messages would lead participants to exercise. Our results suggest that a mobile phone application coupled with a learning algorithm can improve adherence to exercise in diabetic patients. As a learning algorithm is automated, and delivers personalized messages, it could be used in large populations of diabetic patients to improve health and glycemic control. Our results can be expanded to other areas where computer-led health coaching of humans may have a positive impact.
A Gaussian Belief Propagation Solver for Large Scale Support Vector Machines
Oct 09, 2008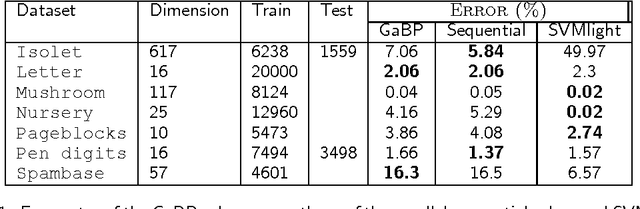
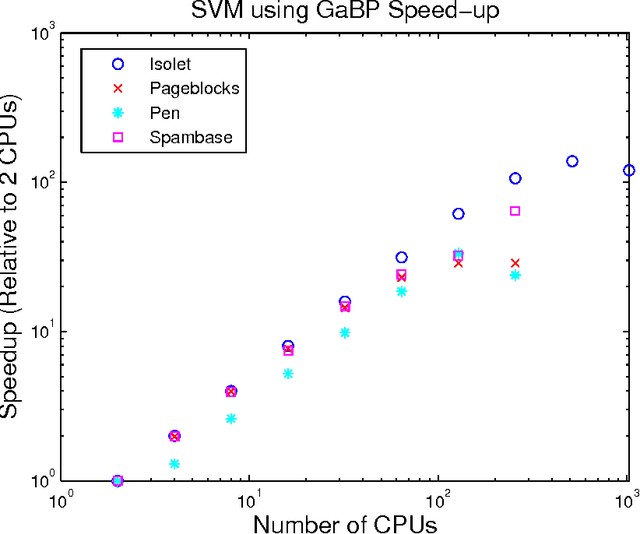
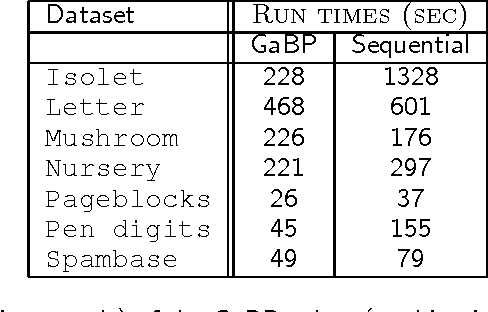

Support vector machines (SVMs) are an extremely successful type of classification and regression algorithms. Building an SVM entails solving a constrained convex quadratic programming problem, which is quadratic in the number of training samples. We introduce an efficient parallel implementation of an support vector regression solver, based on the Gaussian Belief Propagation algorithm (GaBP). In this paper, we demonstrate that methods from the complex system domain could be utilized for performing efficient distributed computation. We compare the proposed algorithm to previously proposed distributed and single-node SVM solvers. Our comparison shows that the proposed algorithm is just as accurate as these solvers, while being significantly faster, especially for large datasets. We demonstrate scalability of the proposed algorithm to up to 1,024 computing nodes and hundreds of thousands of data points using an IBM Blue Gene supercomputer. As far as we know, our work is the largest parallel implementation of belief propagation ever done, demonstrating the applicability of this algorithm for large scale distributed computing systems.
* 12 pages, 1 figure, appeared in the 5th European Complex Systems Conference, Jerusalem, Sept. 2008