 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Counterfactuals from Large Historical Data and Small Randomized Trials
Paper and Code
Oct 26, 2016
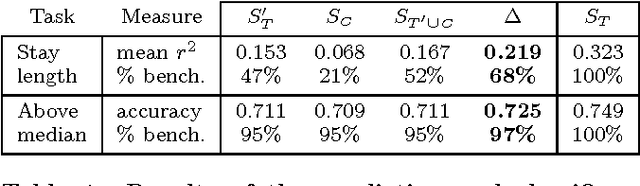
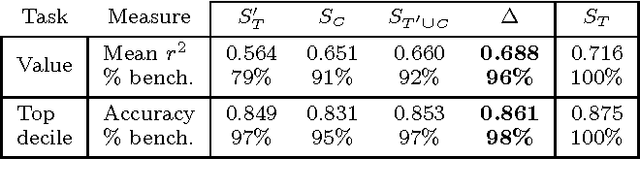

When a new treatment is considered for use, whether a pharmaceutical drug or a search engine ranking algorithm, a typical question that arises is, will its performance exceed that of the current treatment? The conventional way to answer this counterfactual question is to estimate the effect of the new treatment in comparison to that of the conventional treatment by running a controlled, randomized experiment. While this approach theoretically ensures an unbiased estimator, it suffers from several drawbacks, including the difficulty in finding representative experimental populations as well as the cost of running such trials. Moreover, such trials neglect the huge quantities of available control-condition data which are often completely ignored. In this paper we propose a discriminative framework for estimating the performance of a new treatment given a large dataset of the control condition and data from a small (and possibly unrepresentative) randomized trial comparing new and old treatments. Our objective, which requires minimal assumptions on the treatments, models the relation between the outcomes of the different conditions. This allows us to not only estimate mean effects but also to generate individual predictions for examples outside the randomized sample. We demonstrate the utility of our approach through experiments in three areas: Search engine operation, treatments to diabetes patients, and market value estimation for houses. Our results demonstrate that our approach can reduce the number and size of the currently performed randomized controlled experiments, thus saving significant time, money and effort on the part of practitioners.