 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Squid Game: Quadrupedal Locomotion for Traversing Narrow Tunnels
May 13, 2026Quadruped robots demonstrate exceptional potential for navigating complex terrain in critical applications such as search and rescue missions and infrastructure inspection However autonomous traversal of confined 3D environments including tunnels caves and collapsed structures remains a significant challenge Existing methods often struggle with rigid gait patterns limited adaptability to diverse geometries and reliance on oversimplified environmental assumptions This paper introduces a Reinforcement Learning RL framework that combines procedural environment generation with policy distillation to enable robust locomotion across various tunnel configurations Our approach leverages a teacher student training paradigm where specialized expert policies trained on procedurally generated tunnel geometries transfer their knowledge to a unified student policy This strategy eliminates the need for complex reward shaping in end-to-end RL training simplifying the process by breaking down complicated tasks into smaller more manageable components that are easier for the robot to learn By synthesizing diverse tunnel structures during training and distilling navigation strategies into a generalizable policy our method achieves consistent traversal across complex spatial constraints where conventional approaches fail We demonstrate through both simulation and real world experiments that our method enables quadruped robots to successfully traverse challenging confined tunnel environments
Hexagon-MLIR: An AI Compilation Stack For Qualcomm's Neural Processing Units (NPUs)
Feb 23, 2026In this paper, we present Hexagon-MLIR,an open-source compilation stack that targets Qualcomm Hexagon Neural Processing Unit (NPU) and provides unified support for lowering Triton kernels and PyTorch models . Built using the MLIR framework, our compiler applies a structured sequence of passes to exploit NPU architectural features to accelerate AI workloads. It enables faster deployment of new Triton kernels (hand-written or subgraphs from PyTorch 2.0), for our target by providing automated compilation from kernel to binary. By ingesting Triton kernels, we generate mega-kernels that maximize data locality in the NPU's Tightly Coupled Memory (TCM), reducing the bandwidth bottlenecks inherent in library-based approaches. This initiative complements our commercial toolchains by providing developers with an open-source MLIR-based compilation stack that gives them a path to advance AI compilation capabilities through a more flexible approach. Hexagon-MLIR is a work-in-progress, and we are continuing to add many more optimizations and capabilities in this effort.
Transferring Kinesthetic Demonstrations across Diverse Objects for Manipulation Planning
Mar 13, 2025Given a demonstration of a complex manipulation task such as pouring liquid from one container to another, we seek to generate a motion plan for a new task instance involving objects with different geometries. This is non-trivial since we need to simultaneously ensure that the implicit motion constraints are satisfied (glass held upright while moving), the motion is collision-free, and that the task is successful (e.g. liquid is poured into the target container). We solve this problem by identifying positions of critical locations and associating a reference frame (called motion transfer frames) on the manipulated object and the target, selected based on their geometries and the task at hand. By tracking and transferring the path of the motion transfer frames, we generate motion plans for arbitrary task instances with objects of different geometries and poses. We show results from simulation as well as robot experiments on physical objects to evaluate the effectiveness of our solution.
Data Augmentation for Automated Adaptive Rodent Training
Oct 23, 2024Fully optimized automation of behavioral training protocols for lab animals like rodents has long been a coveted goal for researchers. It is an otherwise labor-intensive and time-consuming process that demands close interaction between the animal and the researcher. In this work, we used a data-driven approach to optimize the way rodents are trained in labs. In pursuit of our goal, we looked at data augmentation, a technique that scales well in data-poor environments. Using data augmentation, we built several artificial rodent models, which in turn would be used to build an efficient and automatic trainer. Then we developed a novel similarity metric based on the action probability distribution to measure the behavioral resemblance of our models to that of real rodents.
Screw Geometry Meets Bandits: Incremental Acquisition of Demonstrations to Generate Manipulation Plans
Oct 23, 2024In this paper, we study the problem of methodically obtaining a sufficient set of kinesthetic demonstrations, one at a time, such that a robot can be confident of its ability to perform a complex manipulation task in a given region of its workspace. Although Learning from Demonstrations has been an active area of research, the problems of checking whether a set of demonstrations is sufficient, and systematically seeking additional demonstrations have remained open. We present a novel approach to address these open problems using (i) a screw geometric representation to generate manipulation plans from demonstrations, which makes the sufficiency of a set of demonstrations measurable; (ii) a sampling strategy based on PAC-learning from multi-armed bandit optimization to evaluate the robot's ability to generate manipulation plans in a subregion of its task space; and (iii) a heuristic to seek additional demonstration from areas of weakness. Thus, we present an approach for the robot to incrementally and actively ask for new demonstration examples until the robot can assess with high confidence that it can perform the task successfully. We present experimental results on two example manipulation tasks, namely, pouring and scooping, to illustrate our approach. A short video on the method: https://youtu.be/R-qICICdEos
GND: Global Navigation Dataset with Multi-Modal Perception and Multi-Category Traversability in Outdoor Campus Environments
Sep 21, 2024



Navigating large-scale outdoor environments requires complex reasoning in terms of geometric structures, environmental semantics, and terrain characteristics, which are typically captured by onboard sensors such as LiDAR and cameras. While current mobile robots can navigate such environments using pre-defined, high-precision maps based on hand-crafted rules catered for the specific environment, they lack commonsense reasoning capabilities that most humans possess when navigating unknown outdoor spaces. To address this gap, we introduce the Global Navigation Dataset (GND), a large-scale dataset that integrates multi-modal sensory data, including 3D LiDAR point clouds and RGB and 360-degree images, as well as multi-category traversability maps (pedestrian walkways, vehicle roadways, stairs, off-road terrain, and obstacles) from ten university campuses. These environments encompass a variety of parks, urban settings, elevation changes, and campus layouts of different scales. The dataset covers approximately 2.7km2 and includes at least 350 buildings in total. We also present a set of novel applications of GND to showcase its utility to enable global robot navigation, such as map-based global navigation, mapless navigation, and global place recognition.
Multi-Goal Motion Memory
Jul 16, 2024Autonomous mobile robots (e.g., warehouse logistics robots) often need to traverse complex, obstacle-rich, and changing environments to reach multiple fixed goals (e.g., warehouse shelves). Traditional motion planners need to calculate the entire multi-goal path from scratch in response to changes in the environment, which result in a large consumption of computing resources. This process is not only time-consuming but also may not meet real-time requirements in application scenarios that require rapid response to environmental changes. In this paper, we provide a novel Multi-Goal Motion Memory technique that allows robots to use previous planning experiences to accelerate future multi-goal planning in changing environments. Specifically, our technique predicts collision-free and dynamically-feasible trajectories and distances between goal pairs to guide the sampling process to build a roadmap, to inform a Traveling Salesman Problem (TSP) solver to compute a tour, and to efficiently produce motion plans. Experiments conducted with a vehicle and a snake-like robot in obstacle-rich environments show that the proposed Motion Memory technique can substantially accelerate planning speed by up to 90\%. Furthermore, the solution quality is comparable to state-of-the-art algorithms and even better in some environments.
Motion Memory: Leveraging Past Experiences to Accelerate Future Motion Planning
Oct 09, 2023When facing a new motion-planning problem, most motion planners solve it from scratch, e.g., via sampling and exploration or starting optimization from a straight-line path. However, most motion planners have to experience a variety of planning problems throughout their lifetimes, which are yet to be leveraged for future planning. In this paper, we present a simple but efficient method called Motion Memory, which allows different motion planners to accelerate future planning using past experiences. Treating existing motion planners as either a closed or open box, we present a variety of ways that Motion Memory can contribute to reduce the planning time when facing a new planning problem. We provide extensive experiment results with three different motion planners on three classes of planning problems with over 30,000 problem instances and show that planning speed can be significantly reduced by up to 89% with the proposed Motion Memory technique and with increasing past planning experiences.
Action-conditioned Deep Visual Prediction with RoAM, a new Indoor Human Motion Dataset for Autonomous Robots
Jun 28, 2023



With the increasing adoption of robots across industries, it is crucial to focus on developing advanced algorithms that enable robots to anticipate, comprehend, and plan their actions effectively in collaboration with humans. We introduce the Robot Autonomous Motion (RoAM) video dataset, which is collected with a custom-made turtlebot3 Burger robot in a variety of indoor environments recording various human motions from the robot's ego-vision. The dataset also includes synchronized records of the LiDAR scan and all control actions taken by the robot as it navigates around static and moving human agents. The unique dataset provides an opportunity to develop and benchmark new visual prediction frameworks that can predict future image frames based on the action taken by the recording agent in partially observable scenarios or cases where the imaging sensor is mounted on a moving platform. We have benchmarked the dataset on our novel deep visual prediction framework called ACPNet where the approximated future image frames are also conditioned on action taken by the robot and demonstrated its potential for incorporating robot dynamics into the video prediction paradigm for mobile robotics and autonomous navigation research.
ML-driven Hardware Cost Model for MLIR
Feb 14, 2023


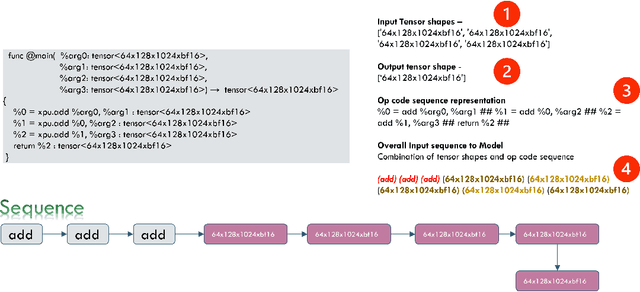
During early optimization passes, compilers must make predictions for machine-dependent characteristics such as execution unit utilization, number of register spills, latency, throughput etc. to generate better code. Often a hand-written static/analytical hardware cost model is built into the compiler. However, the need for more sophisticated and varied predictions has become more pronounced with the development of deep learning compilers which need to optimize dataflow graphs. Such compilers usually employ a much higher level MLIR form as an IR representation before lowering to traditional LLVM-IR. A static/analytical cost model in such a scenario is cumbersome and error prone as the opcodes represent very high level algebraic/arithmetic operations. Hence, we develop a machine learning-based cost model for high-level MLIR which can predict different target variables of interest such as CPU/GPU/xPU utilization, instructions executed, register usage etc. By considering the incoming MLIR as a text input a la NLP models we can apply well-known techniques from modern NLP research to help predict hardware characteristics more accurately. We expect such precise ML-driven hardware cost models to guide our deep learning compiler in graph level optimizations around operator fusion, local memory allocation, kernel scheduling etc. as well as in many kernel-level optimizations such as loop interchange, LICM and unroll. We report early work-in -progress results of developing such models on high-level MLIR representing dataflow graphs emitted by Pytorch/Tensorflow-like frameworks as well as lower-level dialects like affine. We show that these models can provide reasonably good estimates with low error bounds for various hardware characteristics of interest and can be a go-to mechanism for hardware cost modelling in the future.