 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Neural Network based Solving of Partial Differential Equations
May 27, 2022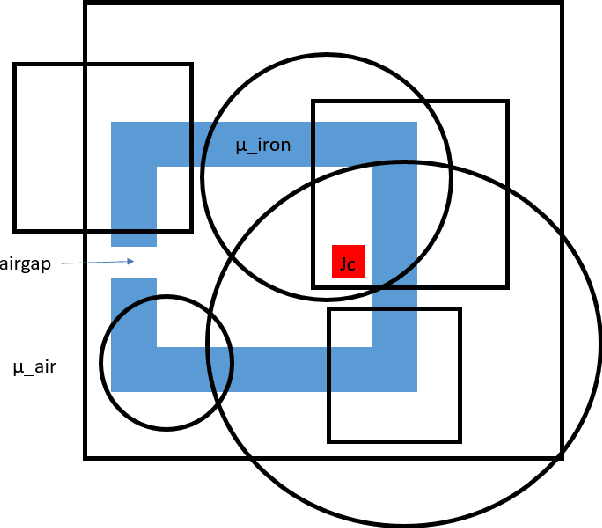

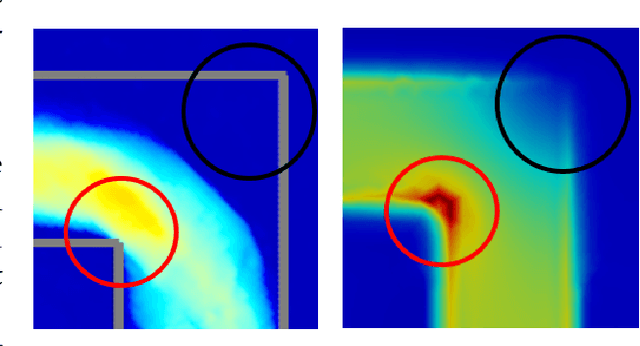
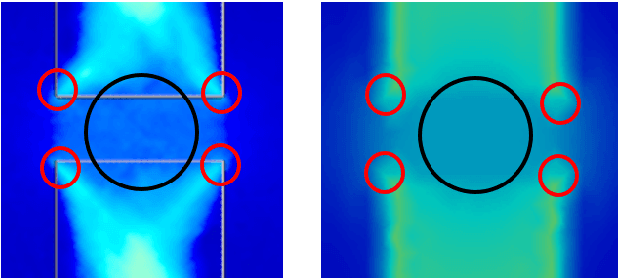
We present a novel method for using Neural Networks (NNs) for finding solutions to a class of Partial Differential Equations (PDEs). Our method builds on recent advances in Neural Radiance Field research (NeRFs) and allows for a NN to converge to a PDE solution much faster than classic Physically Informed Neural Network (PINNs) approaches.
Learned Low Precision Graph Neural Networks
Sep 19, 2020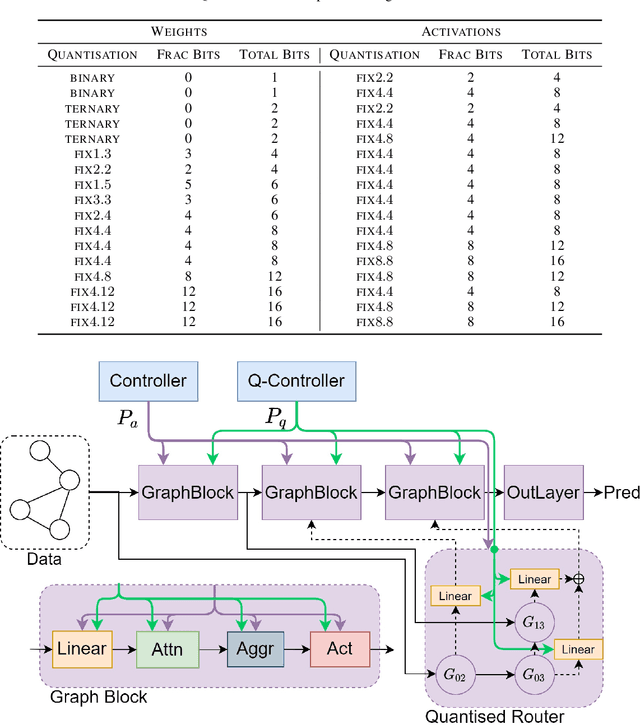


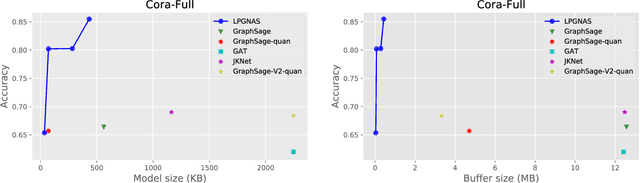
Deep Graph Neural Networks (GNNs) show promising performance on a range of graph tasks, yet at present are costly to run and lack many of the optimisations applied to DNNs. We show, for the first time, how to systematically quantise GNNs with minimal or no loss in performance using Network Architecture Search (NAS). We define the possible quantisation search space of GNNs. The proposed novel NAS mechanism, named Low Precision Graph NAS (LPGNAS), constrains both architecture and quantisation choices to be differentiable. LPGNAS learns the optimal architecture coupled with the best quantisation strategy for different components in the GNN automatically using back-propagation in a single search round. On eight different datasets, solving the task of classifying unseen nodes in a graph, LPGNAS generates quantised models with significant reductions in both model and buffer sizes but with similar accuracy to manually designed networks and other NAS results. In particular, on the Pubmed dataset, LPGNAS shows a better size-accuracy Pareto frontier compared to seven other manual and searched baselines, offering a 2.3 times reduction in model size but a 0.4% increase in accuracy when compared to the best NAS competitor. Finally, from our collected quantisation statistics on a wide range of datasets, we suggest a W4A8 (4-bit weights, 8-bit activations) quantisation strategy might be the bottleneck for naive GNN quantisations.
Sponge Examples: Energy-Latency Attacks on Neural Networks
Jun 05, 2020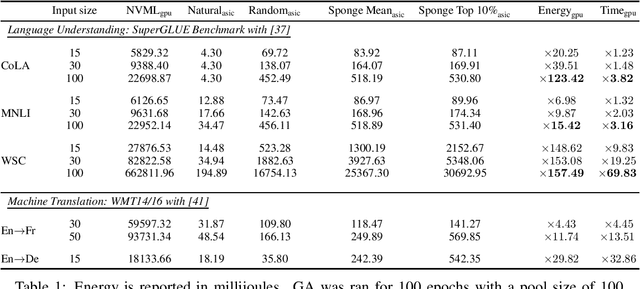
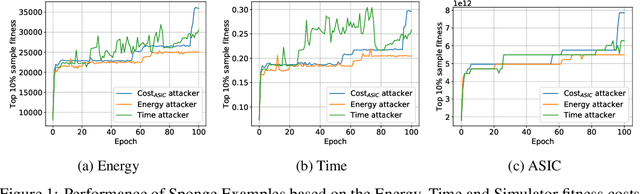
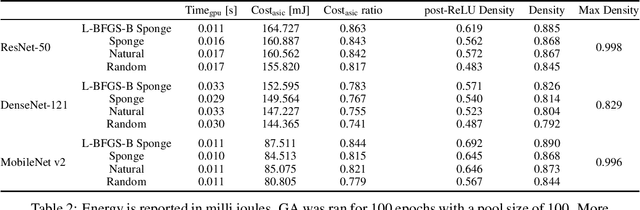
The high energy costs of neural network training and inference led to the use of acceleration hardware such as GPUs and TPUs. While this enabled us to train large-scale neural networks in datacenters and deploy them on edge devices, the focus so far is on average-case performance. In this work, we introduce a novel threat vector against neural networks whose energy consumption or decision latency are critical. We show how adversaries can exploit carefully crafted $\boldsymbol{sponge}~\boldsymbol{examples}$, which are inputs designed to maximise energy consumption and latency. We mount two variants of this attack on established vision and language models, increasing energy consumption by a factor of 10 to 200. Our attacks can also be used to delay decisions where a network has critical real-time performance, such as in perception for autonomous vehicles. We demonstrate the portability of our malicious inputs across CPUs and a variety of hardware accelerator chips including GPUs, and an ASIC simulator. We conclude by proposing a defense strategy which mitigates our attack by shifting the analysis of energy consumption in hardware from an average-case to a worst-case perspective.
Efficient and Effective Quantization for Sparse DNNs
Mar 07, 2019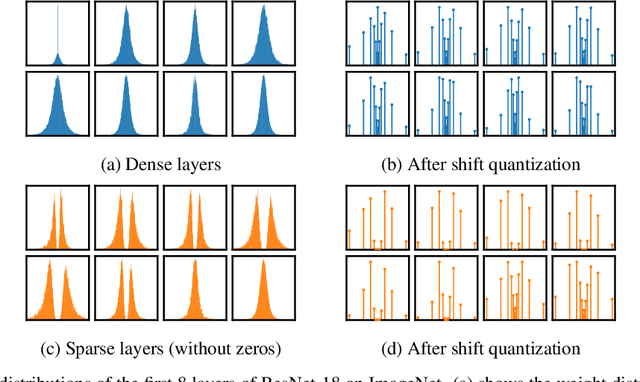
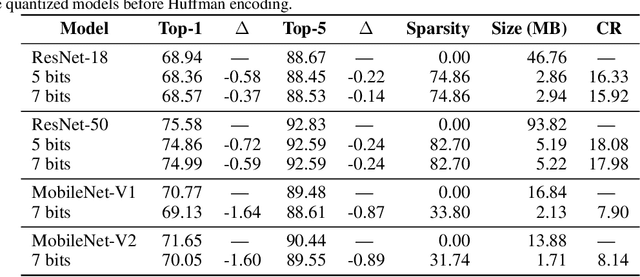
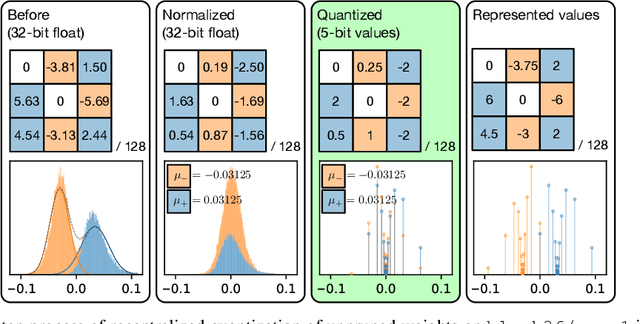
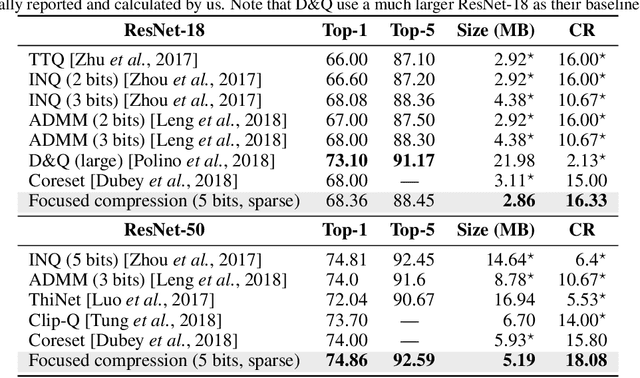
Deep convolutional neural networks (CNNs) are powerful tools for a wide range of vision tasks, but the enormous amount of memory and compute resources required by CNNs poses a challenge in deploying them on constrained devices. Existing compression techniques show promising performance in reducing the size and computation complexity of CNNs for efficient inference, but there lacks a method to integrate them effectively. In this paper, we attend to the statistical properties of sparse CNNs and present focused quantization, a novel quantization strategy based on powers-of-two values, which exploits the weight distributions after fine-grained pruning. The proposed method dynamically discovers the most effective numerical representation for weights in layers with varying sparsities, to minimize the impact of quantization on the task accuracy. Multiplications in quantized CNNs can be replaced with much cheaper bit-shift operations for efficient inference. Coupled with lossless encoding, we build a compression pipeline that provides CNNs high compression ratios (CR) and minimal loss in accuracies. In ResNet-50, we achieve a $ 18.08 \times $ CR with only $ 0.24\% $ loss in top-5 accuracy, outperforming existing compression pipelines.