 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Effective Quantization for Sparse DNNs
Paper and Code
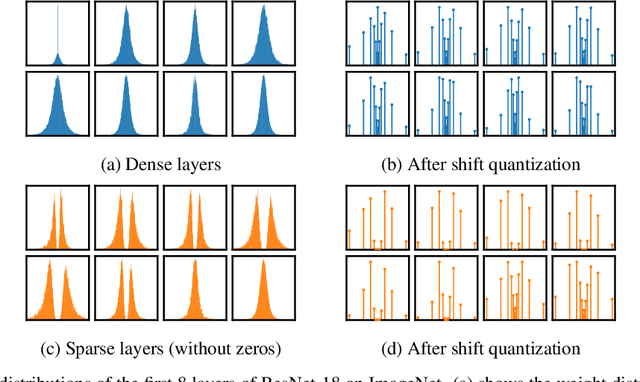
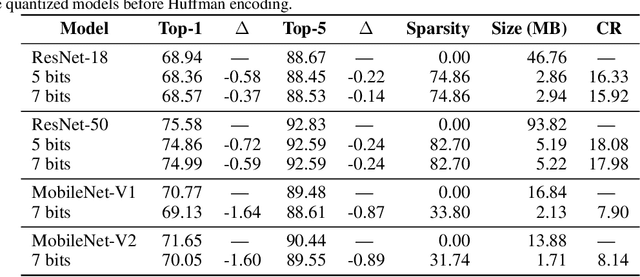
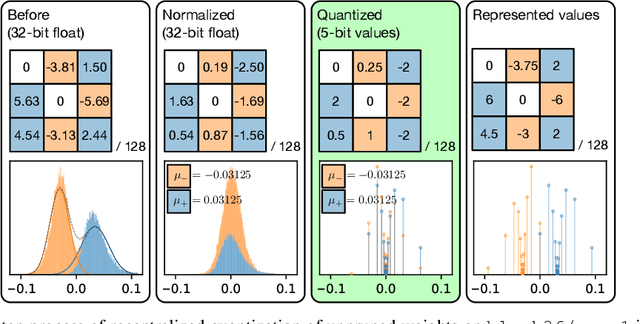
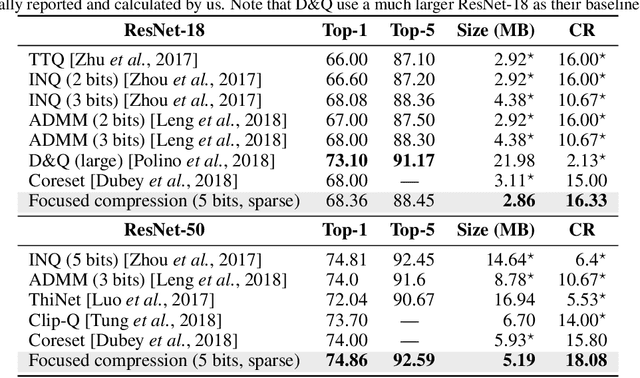
Deep convolutional neural networks (CNNs) are powerful tools for a wide range of vision tasks, but the enormous amount of memory and compute resources required by CNNs poses a challenge in deploying them on constrained devices. Existing compression techniques show promising performance in reducing the size and computation complexity of CNNs for efficient inference, but there lacks a method to integrate them effectively. In this paper, we attend to the statistical properties of sparse CNNs and present focused quantization, a novel quantization strategy based on powers-of-two values, which exploits the weight distributions after fine-grained pruning. The proposed method dynamically discovers the most effective numerical representation for weights in layers with varying sparsities, to minimize the impact of quantization on the task accuracy. Multiplications in quantized CNNs can be replaced with much cheaper bit-shift operations for efficient inference. Coupled with lossless encoding, we build a compression pipeline that provides CNNs high compression ratios (CR) and minimal loss in accuracies. In ResNet-50, we achieve a $ 18.08 \times $ CR with only $ 0.24\% $ loss in top-5 accuracy, outperforming existing compression pipelines.