 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning for Non-Autoregressive Neural Machine Translation
Jul 18, 2019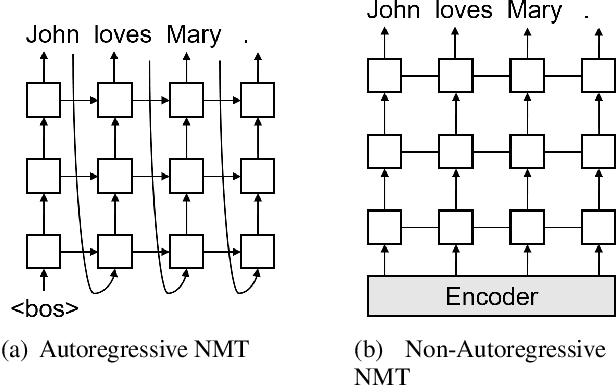


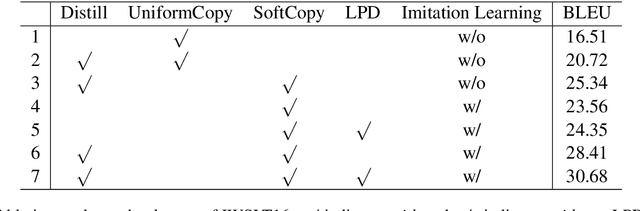
Non-autoregressive translation models (NAT) have achieved impressive inference speedup. A potential issue of the existing NAT algorithms, however, is that the decoding is conducted in parallel, without directly considering previous context. In this paper, we propose an imitation learning framework for non-autoregressive machine translation, which still enjoys the fast translation speed but gives comparable translation performance compared to its auto-regressive counterpart. We conduct experiments on the IWSLT16, WMT14 and WMT16 datasets. Our proposed model achieves a significant speedup over the autoregressive models, while keeping the translation quality comparable to the autoregressive models. By sampling sentence length in parallel at inference time, we achieve the performance of 31.85 BLEU on WMT16 Ro$\rightarrow$En and 30.68 BLEU on IWSLT16 En$\rightarrow$De.
Future-Prediction-Based Model for Neural Machine Translation
Sep 02, 2018



We propose a novel model for Neural Machine Translation (NMT). Different from the conventional method, our model can predict the future text length and words at each decoding time step so that the generation can be helped with the information from the future prediction. With such information, the model does not stop generation without having translated enough content. Experimental results demonstrate that our model can significantly outperform the baseline models. Besides, our analysis reflects that our model is effective in the prediction of the length and words of the untranslated content.
Regularizing Output Distribution of Abstractive Chinese Social Media Text Summarization for Improved Semantic Consistency
May 10, 2018

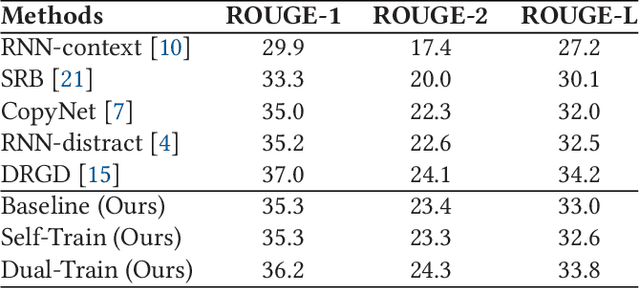
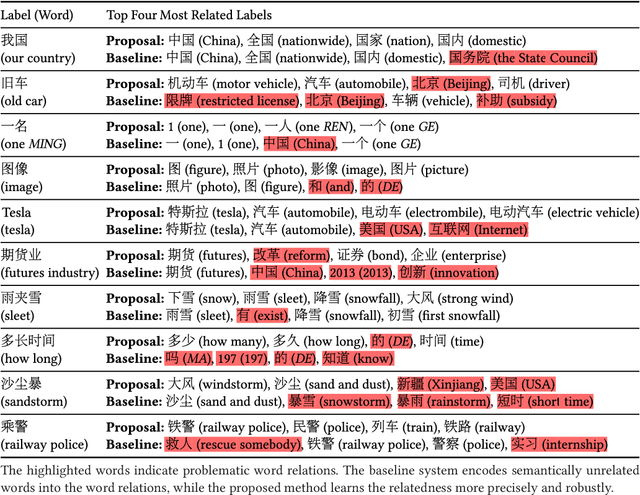
Abstractive text summarization is a highly difficult problem, and the sequence-to-sequence model has shown success in improving the performance on the task. However, the generated summaries are often inconsistent with the source content in semantics. In such cases, when generating summaries, the model selects semantically unrelated words with respect to the source content as the most probable output. The problem can be attributed to heuristically constructed training data, where summaries can be unrelated to the source content, thus containing semantically unrelated words and spurious word correspondence. In this paper, we propose a regularization approach for the sequence-to-sequence model and make use of what the model has learned to regularize the learning objective to alleviate the effect of the problem. In addition, we propose a practical human evaluation method to address the problem that the existing automatic evaluation method does not evaluate the semantic consistency with the source content properly. Experimental results demonstrate the effectiveness of the proposed approach, which outperforms almost all the existing models. Especially, the proposed approach improves the semantic consistency by 4\% in terms of human evaluation.
Building an Ellipsis-aware Chinese Dependency Treebank for Web Text
Jan 23, 2018
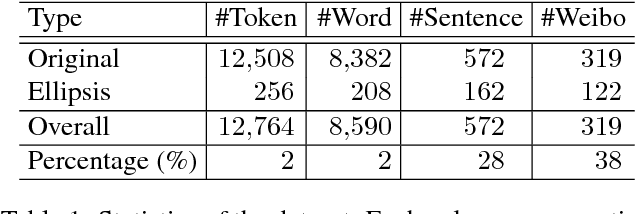
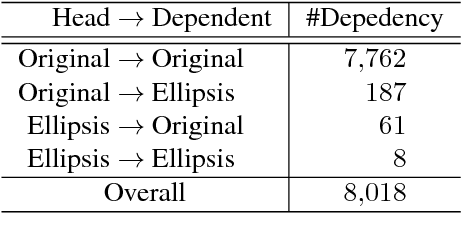
Web 2.0 has brought with it numerous user-produced data revealing one's thoughts, experiences, and knowledge, which are a great source for many tasks, such as information extraction, and knowledge base construction. However, the colloquial nature of the texts poses new challenges for current natural language processing techniques, which are more adapt to the formal form of the language. Ellipsis is a common linguistic phenomenon that some words are left out as they are understood from the context, especially in oral utterance, hindering the improvement of dependency parsing, which is of great importance for tasks relied on the meaning of the sentence. In order to promote research in this area, we are releasing a Chinese dependency treebank of 319 weibos, containing 572 sentences with omissions restored and contexts reserved.
Training Simplification and Model Simplification for Deep Learning: A Minimal Effort Back Propagation Method
Nov 17, 2017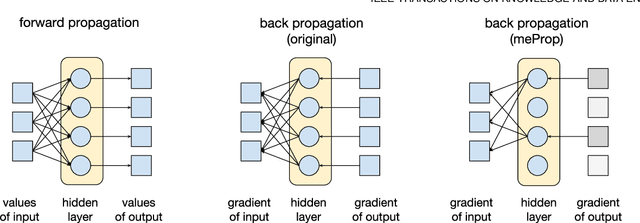

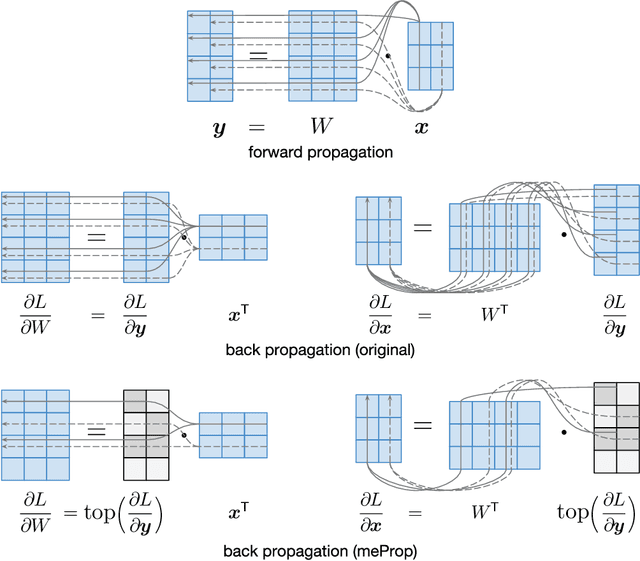

We propose a simple yet effective technique to simplify the training and the resulting model of neural networks. In back propagation, only a small subset of the full gradient is computed to update the model parameters. The gradient vectors are sparsified in such a way that only the top-$k$ elements (in terms of magnitude) are kept. As a result, only $k$ rows or columns (depending on the layout) of the weight matrix are modified, leading to a linear reduction in the computational cost. Based on the sparsified gradients, we further simplify the model by eliminating the rows or columns that are seldom updated, which will reduce the computational cost both in the training and decoding, and potentially accelerate decoding in real-world applications. Surprisingly, experimental results demonstrate that most of time we only need to update fewer than 5% of the weights at each back propagation pass. More interestingly, the accuracy of the resulting models is actually improved rather than degraded, and a detailed analysis is given. The model simplification results show that we could adaptively simplify the model which could often be reduced by around 9x, without any loss on accuracy or even with improved accuracy.
Deep Stacking Networks for Low-Resource Chinese Word Segmentation with Transfer Learning
Nov 04, 2017



In recent years, neural networks have proven to be effective in Chinese word segmentation. However, this promising performance relies on large-scale training data. Neural networks with conventional architectures cannot achieve the desired results in low-resource datasets due to the lack of labelled training data. In this paper, we propose a deep stacking framework to improve the performance on word segmentation tasks with insufficient data by integrating datasets from diverse domains. Our framework consists of two parts, domain-based models and deep stacking networks. The domain-based models are used to learn knowledge from different datasets. The deep stacking networks are designed to integrate domain-based models. To reduce model conflicts, we innovatively add communication paths among models and design various structures of deep stacking networks, including Gaussian-based Stacking Networks, Concatenate-based Stacking Networks, Sequence-based Stacking Networks and Tree-based Stacking Networks. We conduct experiments on six low-resource datasets from various domains. Our proposed framework shows significant performance improvements on all datasets compared with several strong baselines.
Label Embedding Network: Learning Label Representation for Soft Training of Deep Networks
Oct 28, 2017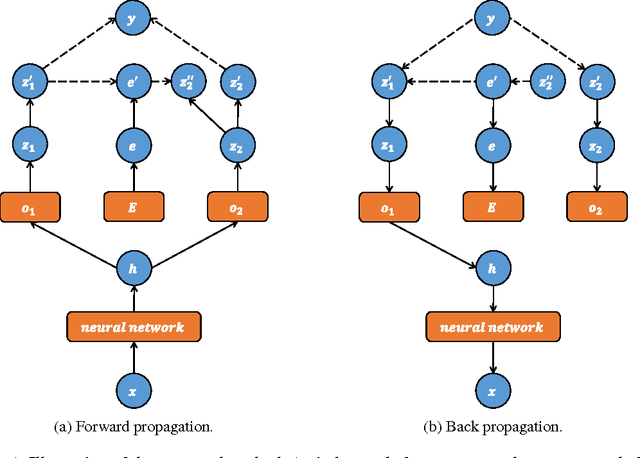



We propose a method, called Label Embedding Network, which can learn label representation (label embedding) during the training process of deep networks. With the proposed method, the label embedding is adaptively and automatically learned through back propagation. The original one-hot represented loss function is converted into a new loss function with soft distributions, such that the originally unrelated labels have continuous interactions with each other during the training process. As a result, the trained model can achieve substantially higher accuracy and with faster convergence speed. Experimental results based on competitive tasks demonstrate the effectiveness of the proposed method, and the learned label embedding is reasonable and interpretable. The proposed method achieves comparable or even better results than the state-of-the-art systems. The source code is available at \url{https://github.com/lancopku/LabelEmb}.
Minimal Effort Back Propagation for Convolutional Neural Networks
Sep 18, 2017



As traditional neural network consumes a significant amount of computing resources during back propagation, \citet{Sun2017mePropSB} propose a simple yet effective technique to alleviate this problem. In this technique, only a small subset of the full gradients are computed to update the model parameters. In this paper we extend this technique into the Convolutional Neural Network(CNN) to reduce calculation in back propagation, and the surprising results verify its validity in CNN: only 5\% of the gradients are passed back but the model still achieves the same effect as the traditional CNN, or even better. We also show that the top-$k$ selection of gradients leads to a sparse calculation in back propagation, which may bring significant computational benefits for high computational complexity of convolution operation in CNN.