 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning for Non-Autoregressive Neural Machine Translation
Paper and Code
Jul 18, 2019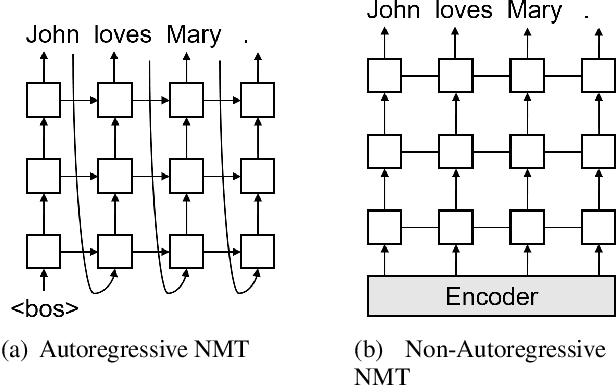


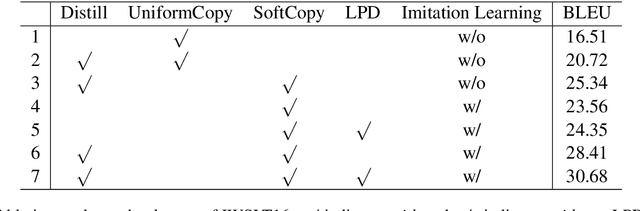
Non-autoregressive translation models (NAT) have achieved impressive inference speedup. A potential issue of the existing NAT algorithms, however, is that the decoding is conducted in parallel, without directly considering previous context. In this paper, we propose an imitation learning framework for non-autoregressive machine translation, which still enjoys the fast translation speed but gives comparable translation performance compared to its auto-regressive counterpart. We conduct experiments on the IWSLT16, WMT14 and WMT16 datasets. Our proposed model achieves a significant speedup over the autoregressive models, while keeping the translation quality comparable to the autoregressive models. By sampling sentence length in parallel at inference time, we achieve the performance of 31.85 BLEU on WMT16 Ro$\rightarrow$En and 30.68 BLEU on IWSLT16 En$\rightarrow$De.