 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure Regularized Neural Network for Entity Relation Classification for Chinese Literature Text
Mar 15, 2018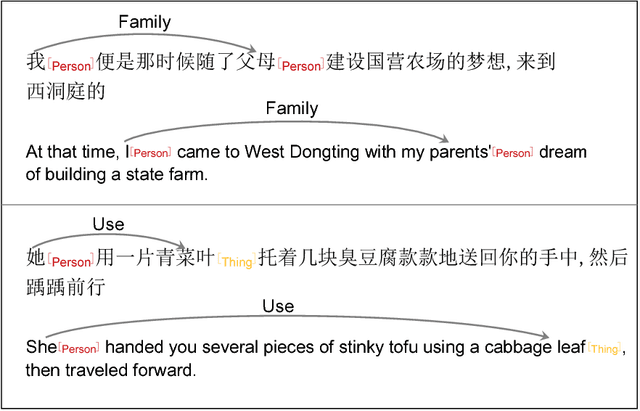

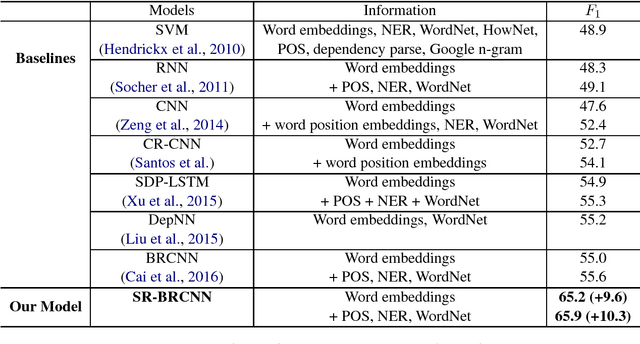
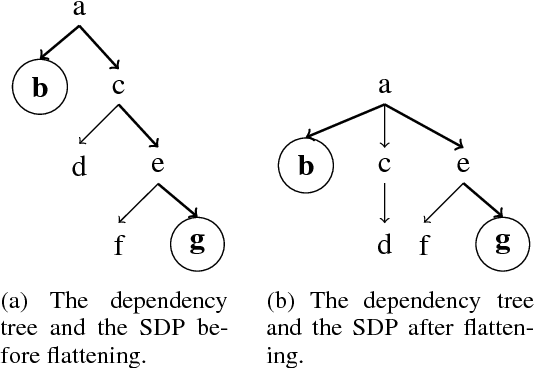
Relation classification is an important semantic processing task in the field of natural language processing. In this paper, we propose the task of relation classification for Chinese literature text. A new dataset of Chinese literature text is constructed to facilitate the study in this task. We present a novel model, named Structure Regularized Bidirectional Recurrent Convolutional Neural Network (SR-BRCNN), to identify the relation between entities. The proposed model learns relation representations along the shortest dependency path (SDP) extracted from the structure regularized dependency tree, which has the benefits of reducing the complexity of the whole model. Experimental results show that the proposed method significantly improves the F1 score by 10.3, and outperforms the state-of-the-art approaches on Chinese literature text.
Building an Ellipsis-aware Chinese Dependency Treebank for Web Text
Jan 23, 2018
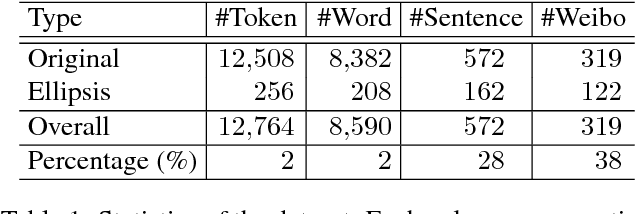
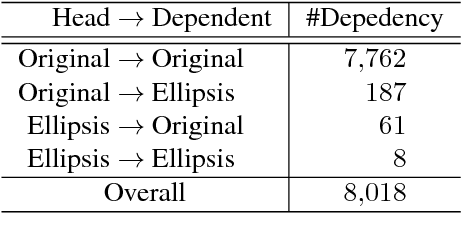
Web 2.0 has brought with it numerous user-produced data revealing one's thoughts, experiences, and knowledge, which are a great source for many tasks, such as information extraction, and knowledge base construction. However, the colloquial nature of the texts poses new challenges for current natural language processing techniques, which are more adapt to the formal form of the language. Ellipsis is a common linguistic phenomenon that some words are left out as they are understood from the context, especially in oral utterance, hindering the improvement of dependency parsing, which is of great importance for tasks relied on the meaning of the sentence. In order to promote research in this area, we are releasing a Chinese dependency treebank of 319 weibos, containing 572 sentences with omissions restored and contexts reserved.
A Discourse-Level Named Entity Recognition and Relation Extraction Dataset for Chinese Literature Text
Nov 23, 2017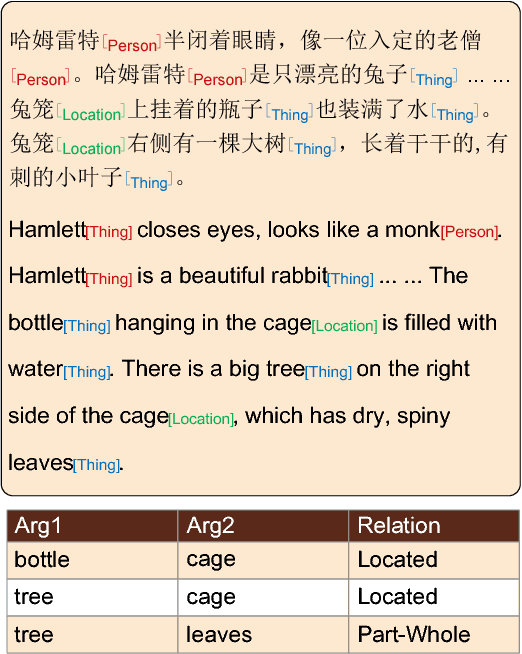

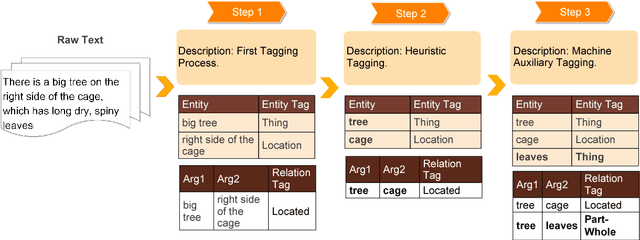
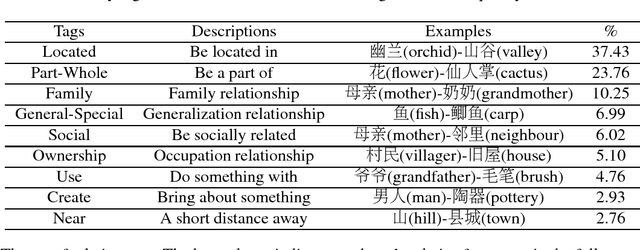
Named Entity Recognition and Relation Extraction for Chinese literature text is regarded as the highly difficult problem, partially because of the lack of tagging sets. In this paper, we build a discourse-level dataset from hundreds of Chinese literature articles for improving this task. To build a high quality dataset, we propose two tagging methods to solve the problem of data inconsistency, including a heuristic tagging method and a machine auxiliary tagging method. Based on this corpus, we also introduce several widely used models to conduct experiments. Experimental results not only show the usefulness of the proposed dataset, but also provide baselines for further research. The dataset is available at https://github.com/lancopku/Chinese-Literature-NER-RE-Dataset.
Structure Regularized Bidirectional Recurrent Convolutional Neural Network for Relation Classification
Nov 06, 2017
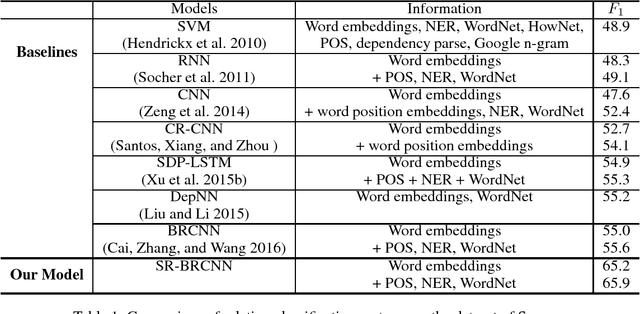

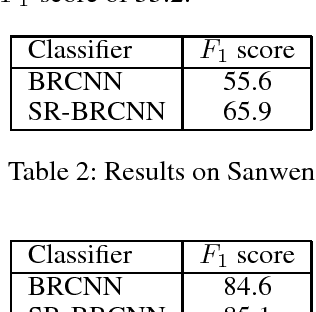
Relation classification is an important semantic processing task in the field of natural language processing (NLP). In this paper, we present a novel model, Structure Regularized Bidirectional Recurrent Convolutional Neural Network(SR-BRCNN), to classify the relation of two entities in a sentence, and the new dataset of Chinese Sanwen for named entity recognition and relation classification. Some state-of-the-art systems concentrate on modeling the shortest dependency path (SDP) between two entities leveraging convolutional or recurrent neural networks. We further explore how to make full use of the dependency relations information in the SDP and how to improve the model by the method of structure regularization. We propose a structure regularized model to learn relation representations along the SDP extracted from the forest formed by the structure regularized dependency tree, which benefits reducing the complexity of the whole model and helps improve the $F_{1}$ score by 10.3. Experimental results show that our method outperforms the state-of-the-art approaches on the Chinese Sanwen task and performs as well on the SemEval-2010 Task 8 dataset\footnote{The Chinese Sanwen corpus this paper developed and used will be released in the further.
Sentence Correction Based on Large-scale Language Modelling
Nov 02, 2017
With the further development of informatization, more and more data is stored in the form of text. There are some loss of text during their generation and transmission. The paper aims to establish a language model based on the large-scale corpus to complete the restoration of missing text. In this paper, we introduce a novel measurement to find the missing words, and a way of establishing a comprehensive candidate lexicon to insert the correct choice of words. The paper also introduces some effective optimization methods, which largely improve the efficiency of the text restoration and shorten the time of dealing with 1000 sentences into 3.6 seconds. \keywords{ language model, sentence correction, word imputation, parallel optimization