 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Discourse-Level Named Entity Recognition and Relation Extraction Dataset for Chinese Literature Text
Paper and Code
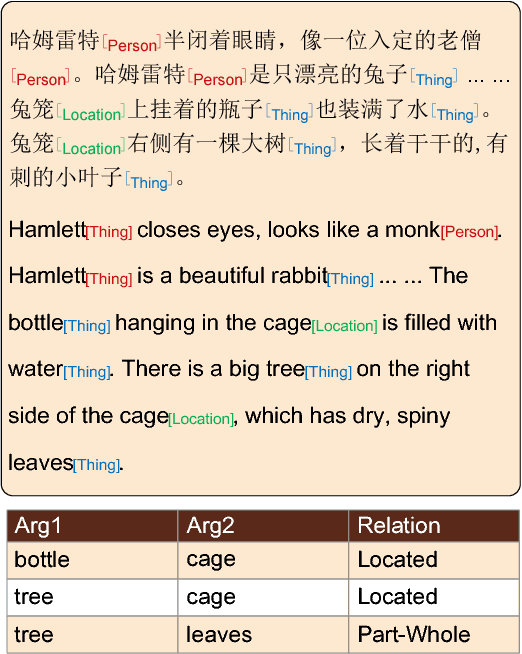

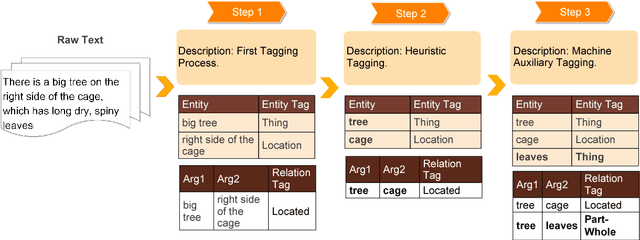
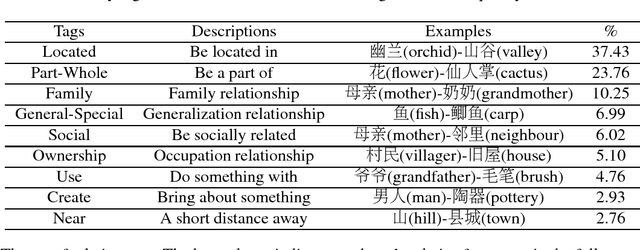
Named Entity Recognition and Relation Extraction for Chinese literature text is regarded as the highly difficult problem, partially because of the lack of tagging sets. In this paper, we build a discourse-level dataset from hundreds of Chinese literature articles for improving this task. To build a high quality dataset, we propose two tagging methods to solve the problem of data inconsistency, including a heuristic tagging method and a machine auxiliary tagging method. Based on this corpus, we also introduce several widely used models to conduct experiments. Experimental results not only show the usefulness of the proposed dataset, but also provide baselines for further research. The dataset is available at https://github.com/lancopku/Chinese-Literature-NER-RE-Dataset.