 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Negation: Boosting Grounding Models via Grouped Opposition-Based Learning
Mar 13, 2026Current vision-language detection and grounding models predominantly focus on prompts with positive semantics and often struggle to accurately interpret and ground complex expressions containing negative semantics. A key reason for this limitation is the lack of high-quality training data that explicitly captures discriminative negative samples and negation-aware language descriptions. To address this challenge, we introduce D-Negation, a new dataset that provides objects annotated with both positive and negative semantic descriptions. Building upon the observation that negation reasoning frequently appears in natural language, we further propose a grouped opposition-based learning framework that learns negation-aware representations from limited samples. Specifically, our method organizes opposing semantic descriptions from D-Negation into structured groups and formulates two complementary loss functions that encourage the model to reason about negation and semantic qualifiers. We integrate the proposed dataset and learning strategy into a state-of-the-art language-based grounding model. By fine-tuning fewer than 10 percent of the model parameters, our approach achieves improvements of up to 4.4 mAP and 5.7 mAP on positive and negative semantic evaluations, respectively. These results demonstrate that explicitly modeling negation semantics can substantially enhance the robustness and localization accuracy of vision-language grounding models.
AutoIAD: Manager-Driven Multi-Agent Collaboration for Automated Industrial Anomaly Detection
Aug 07, 2025Industrial anomaly detection (IAD) is critical for manufacturing quality control, but conventionally requires significant manual effort for various application scenarios. This paper introduces AutoIAD, a multi-agent collaboration framework, specifically designed for end-to-end automated development of industrial visual anomaly detection. AutoIAD leverages a Manager-Driven central agent to orchestrate specialized sub-agents (including Data Preparation, Data Loader, Model Designer, Trainer) and integrates a domain-specific knowledge base, which intelligently handles the entire pipeline using raw industrial image data to develop a trained anomaly detection model. We construct a comprehensive benchmark using MVTec AD datasets to evaluate AutoIAD across various LLM backends. Extensive experiments demonstrate that AutoIAD significantly outperforms existing general-purpose agentic collaboration frameworks and traditional AutoML frameworks in task completion rate and model performance (AUROC), while effectively mitigating issues like hallucination through iterative refinement. Ablation studies further confirm the crucial roles of the Manager central agent and the domain knowledge base module in producing robust and high-quality IAD solutions.
Knowing the Past to Predict the Future: Reinforcement Virtual Learning
Nov 02, 2022

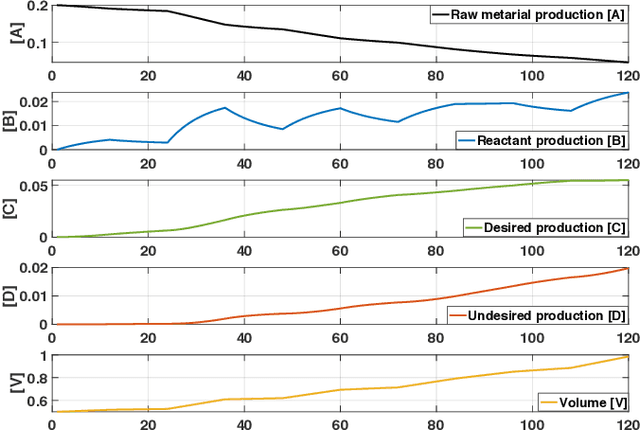

Reinforcement Learning (RL)-based control system has received considerable attention in recent decades. However, in many real-world problems, such as Batch Process Control, the environment is uncertain, which requires expensive interaction to acquire the state and reward values. In this paper, we present a cost-efficient framework, such that the RL model can evolve for itself in a Virtual Space using the predictive models with only historical data. The proposed framework enables a step-by-step RL model to predict the future state and select optimal actions for long-sight decisions. The main focuses are summarized as: 1) how to balance the long-sight and short-sight rewards with an optimal strategy; 2) how to make the virtual model interacting with real environment to converge to a final learning policy. Under the experimental settings of Fed-Batch Process, our method consistently outperforms the existing state-of-the-art methods.
Discriminative Latent Semantic Graph for Video Captioning
Aug 10, 2021

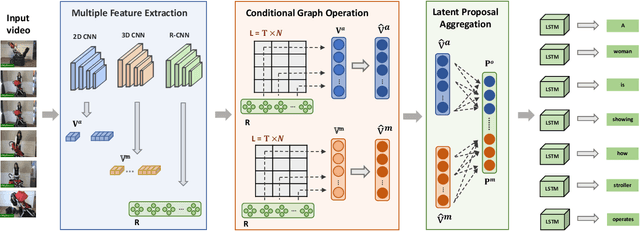
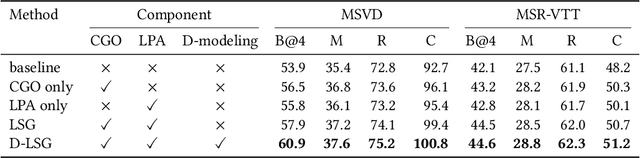
Video captioning aims to automatically generate natural language sentences that can describe the visual contents of a given video. Existing generative models like encoder-decoder frameworks cannot explicitly explore the object-level interactions and frame-level information from complex spatio-temporal data to generate semantic-rich captions. Our main contribution is to identify three key problems in a joint framework for future video summarization tasks. 1) Enhanced Object Proposal: we propose a novel Conditional Graph that can fuse spatio-temporal information into latent object proposal. 2) Visual Knowledge: Latent Proposal Aggregation is proposed to dynamically extract visual words with higher semantic levels. 3) Sentence Validation: A novel Discriminative Language Validator is proposed to verify generated captions so that key semantic concepts can be effectively preserved. Our experiments on two public datasets (MVSD and MSR-VTT) manifest significant improvements over state-of-the-art approaches on all metrics, especially for BLEU-4 and CIDEr. Our code is available at https://github.com/baiyang4/D-LSG-Video-Caption.
Query Twice: Dual Mixture Attention Meta Learning for Video Summarization
Aug 19, 2020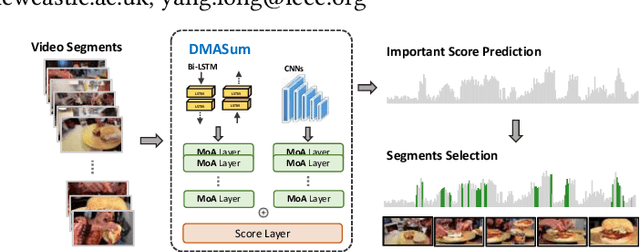
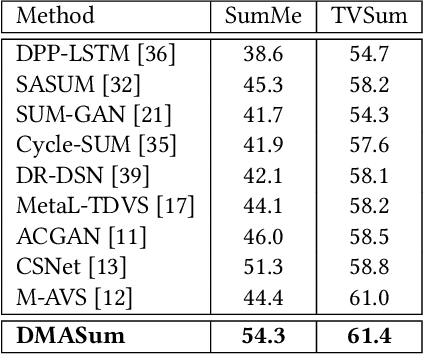
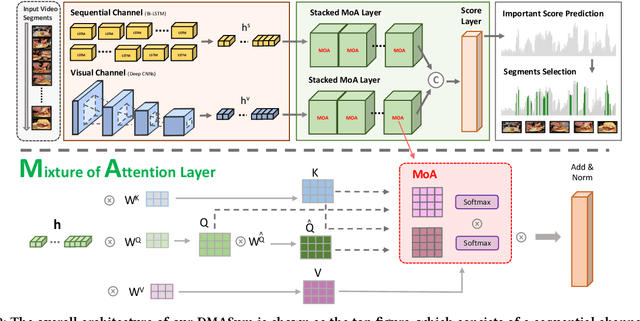
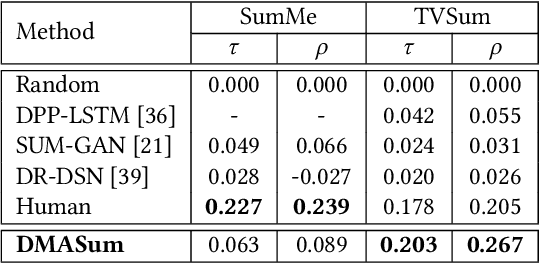
Video summarization aims to select representative frames to retain high-level information, which is usually solved by predicting the segment-wise importance score via a softmax function. However, softmax function suffers in retaining high-rank representations for complex visual or sequential information, which is known as the Softmax Bottleneck problem. In this paper, we propose a novel framework named Dual Mixture Attention (DMASum) model with Meta Learning for video summarization that tackles the softmax bottleneck problem, where the Mixture of Attention layer (MoA) effectively increases the model capacity by employing twice self-query attention that can capture the second-order changes in addition to the initial query-key attention, and a novel Single Frame Meta Learning rule is then introduced to achieve more generalization to small datasets with limited training sources. Furthermore, the DMASum significantly exploits both visual and sequential attention that connects local key-frame and global attention in an accumulative way. We adopt the new evaluation protocol on two public datasets, SumMe, and TVSum. Both qualitative and quantitative experiments manifest significant improvements over the state-of-the-art methods.
Dual-reference Age Synthesis
Aug 07, 2019


Age synthesis has received much attention in recent years. State-of-the-art methods typically take an input image and utilize a numeral to control the age of the generated image. In this paper, we revisit the age synthesis and ask: is a numeral capable enough to describe the human age? We propose a new framework Dual-reference Age Synthesis (DRAS) that takes two images as inputs to generate an image which shares the same personality of the first image and has the similar age with the second image. In the proposed framework, we employ a joint manifold feature which consists of disentangled age and identity information. The final images are generated by training a generative adversarial network which competes against an age agent and an identity agent. Experimental results demonstrate the appealing performance and flexibility of the proposed framework by comparing with the state-of-the-art and ground truth.
Order Matters: Shuffling Sequence Generation for Video Prediction
Jul 20, 2019
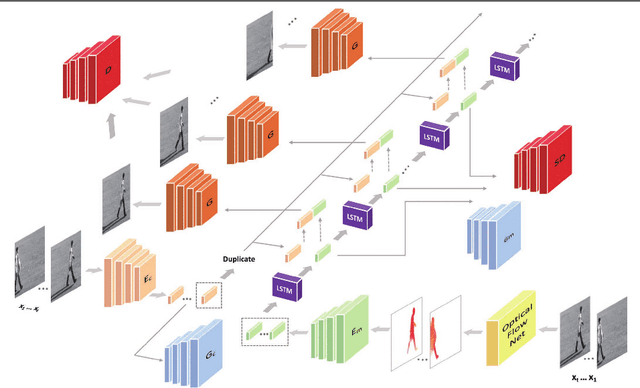
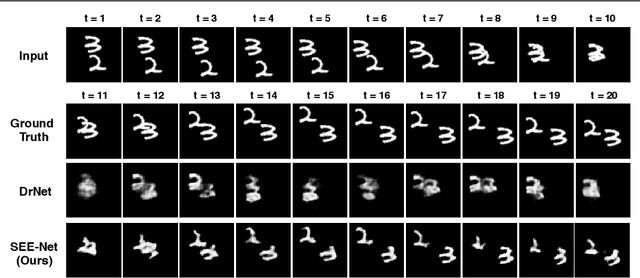

Predicting future frames in natural video sequences is a new challenge that is receiving increasing attention in the computer vision community. However, existing models suffer from severe loss of temporal information when the predicted sequence is long. Compared to previous methods focusing on generating more realistic contents, this paper extensively studies the importance of sequential order information for video generation. A novel Shuffling sEquence gEneration network (SEE-Net) is proposed that can learn to discriminate unnatural sequential orders by shuffling the video frames and comparing them to the real video sequence. Systematic experiments on three datasets with both synthetic and real-world videos manifest the effectiveness of shuffling sequence generation for video prediction in our proposed model and demonstrate state-of-the-art performance by both qualitative and quantitative evaluations. The source code is available at https://github.com/andrewjywang/SEENet.