 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Latent Semantic Graph for Video Captioning
Paper and Code


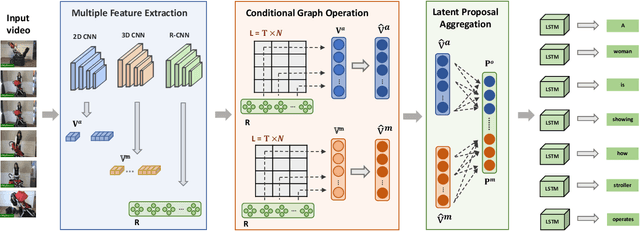
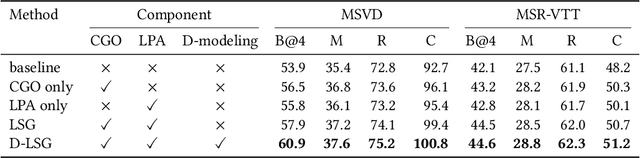
Video captioning aims to automatically generate natural language sentences that can describe the visual contents of a given video. Existing generative models like encoder-decoder frameworks cannot explicitly explore the object-level interactions and frame-level information from complex spatio-temporal data to generate semantic-rich captions. Our main contribution is to identify three key problems in a joint framework for future video summarization tasks. 1) Enhanced Object Proposal: we propose a novel Conditional Graph that can fuse spatio-temporal information into latent object proposal. 2) Visual Knowledge: Latent Proposal Aggregation is proposed to dynamically extract visual words with higher semantic levels. 3) Sentence Validation: A novel Discriminative Language Validator is proposed to verify generated captions so that key semantic concepts can be effectively preserved. Our experiments on two public datasets (MVSD and MSR-VTT) manifest significant improvements over state-of-the-art approaches on all metrics, especially for BLEU-4 and CIDEr. Our code is available at https://github.com/baiyang4/D-LSG-Video-Caption.