 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAb-Initio Solution of the Many-Electron Schrödinger Equation with Deep Neural Networks
Sep 05, 2019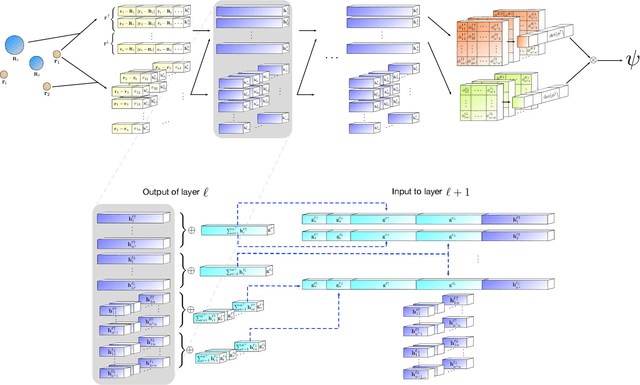
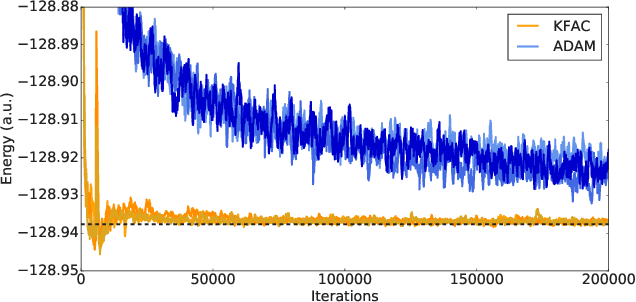
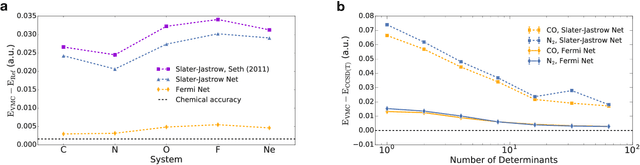
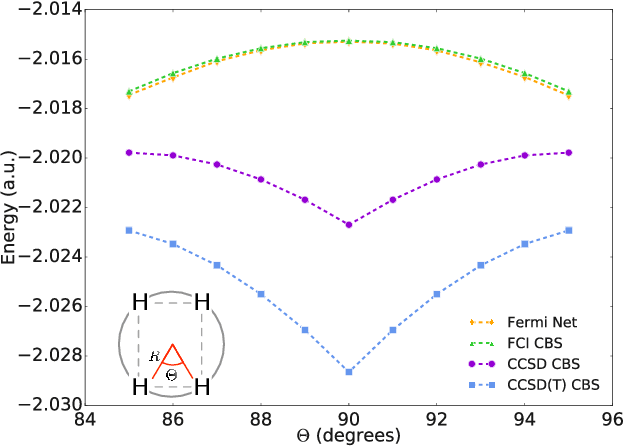
Given access to accurate solutions of the many-electron Schr\"odinger equation, nearly all chemistry could be derived from first principles. Exact wavefunctions of interesting chemical systems are out of reach because they are NP-hard to compute in general, but approximations can be found using polynomially-scaling algorithms. The key challenge for many of these algorithms is the choice of wavefunction approximation, or Ansatz, which must trade off between efficiency and accuracy. Neural networks have shown impressive power as accurate practical function approximators and promise as a compact wavefunction Ansatz for spin systems, but problems in electronic structure require wavefunctions that obey Fermi-Dirac statistics. Here we introduce a novel deep learning architecture, the Fermionic Neural Network, as a powerful wavefunction Ansatz for many-electron systems. The Fermionic Neural Network is able to achieve accuracy beyond other variational Monte Carlo Ans\"atze on a variety of atoms and small molecules. Using no data other than atomic positions and charges, we predict the dissociation curves of the nitrogen molecule and hydrogen chain, two challenging strongly-correlated systems, to significantly higher accuracy than the coupled cluster method, widely considered the gold standard for quantum chemistry. This demonstrates that deep neural networks can outperform existing ab-initio quantum chemistry methods, opening the possibility of accurate direct optimisation of wavefunctions for previously intractable molecules and solids.
Functional Regularisation for Continual Learning using Gaussian Processes
Jan 31, 2019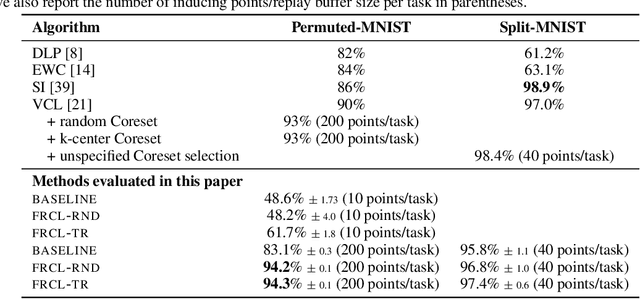
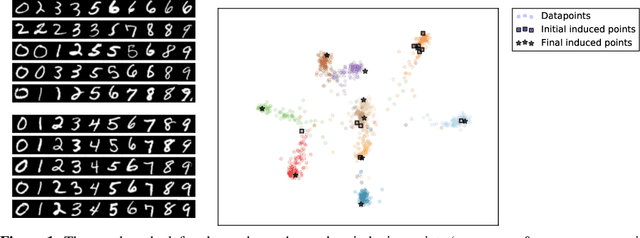
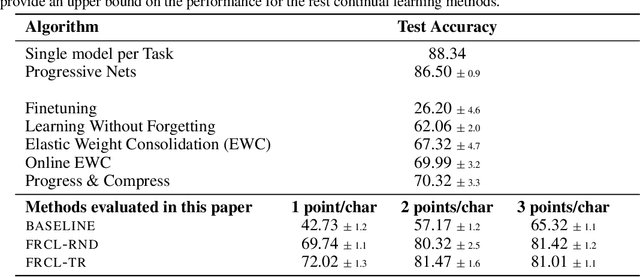
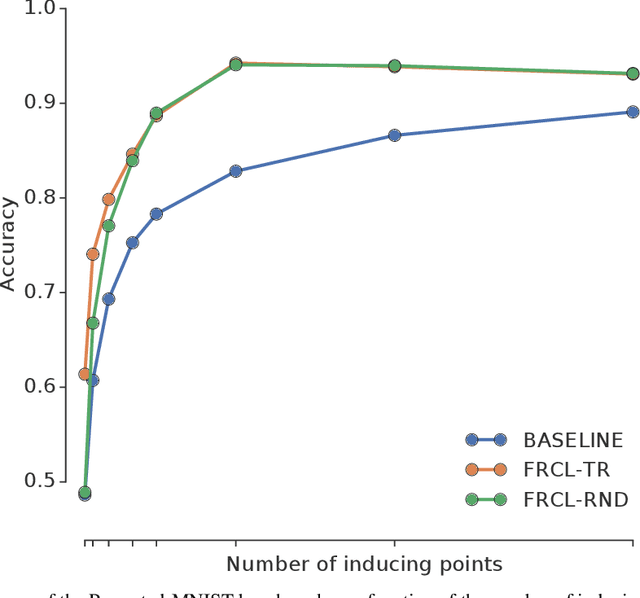
We introduce a novel approach for supervised continual learning based on approximate Bayesian inference over function space rather than the parameters of a deep neural network. We use a Gaussian process obtained by treating the weights of the last layer of a neural network as random and Gaussian distributed. Functional regularisation for continual learning naturally arises by applying the variational sparse GP inference method in a sequential fashion as new tasks are encountered. At each step of the process, a summary is constructed for the current task that consists of (i) inducing inputs and (ii) a posterior distribution over the function values at these inputs. This summary then regularises learning of future tasks, through Kullback-Leibler regularisation terms that appear in the variational lower bound, and reduces the effects of catastrophic forgetting. We fully develop the theory of the method and we demonstrate its effectiveness in classification datasets, such as Split-MNIST, Permuted-MNIST and Omniglot.
Gaussian Process Behaviour in Wide Deep Neural Networks
Aug 16, 2018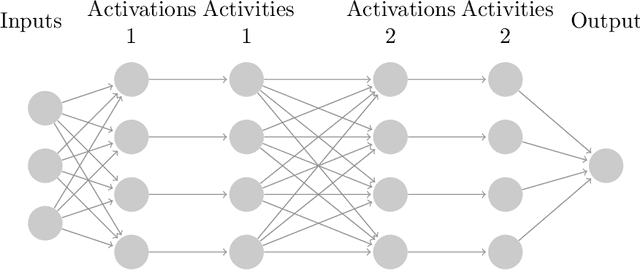
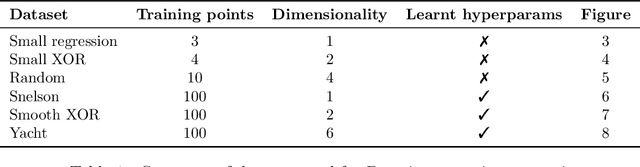
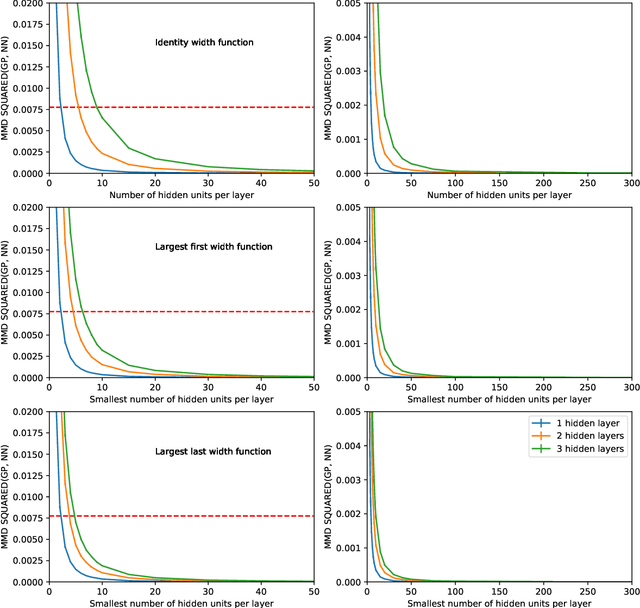
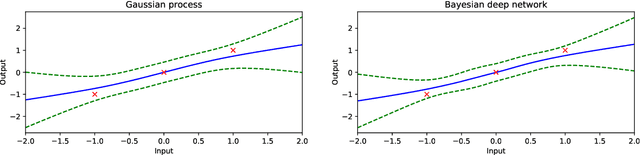
Whilst deep neural networks have shown great empirical success, there is still much work to be done to understand their theoretical properties. In this paper, we study the relationship between random, wide, fully connected, feedforward networks with more than one hidden layer and Gaussian processes with a recursive kernel definition. We show that, under broad conditions, as we make the architecture increasingly wide, the implied random function converges in distribution to a Gaussian process, formalising and extending existing results by Neal (1996) to deep networks. To evaluate convergence rates empirically, we use maximum mean discrepancy. We then compare finite Bayesian deep networks from the literature to Gaussian processes in terms of the key predictive quantities of interest, finding that in some cases the agreement can be very close. We discuss the desirability of Gaussian process behaviour and review non-Gaussian alternative models from the literature.
Variational Bayesian dropout: pitfalls and fixes
Jul 05, 2018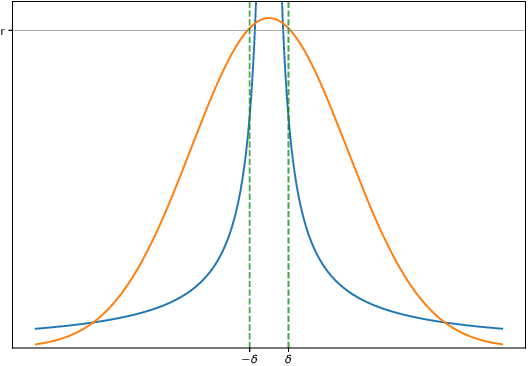
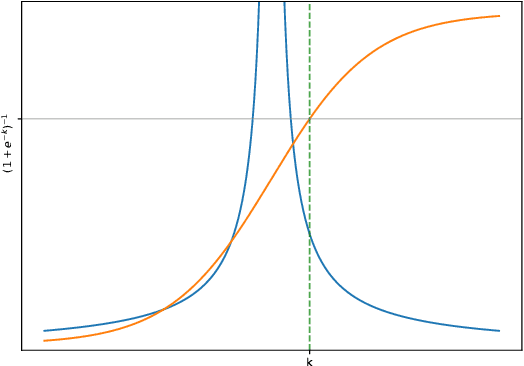
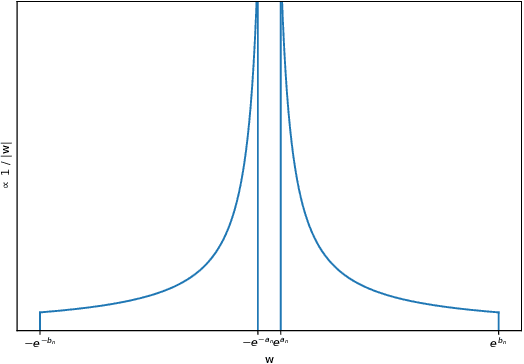
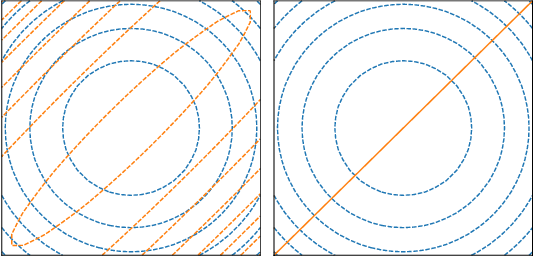
Dropout, a stochastic regularisation technique for training of neural networks, has recently been reinterpreted as a specific type of approximate inference algorithm for Bayesian neural networks. The main contribution of the reinterpretation is in providing a theoretical framework useful for analysing and extending the algorithm. We show that the proposed framework suffers from several issues; from undefined or pathological behaviour of the true posterior related to use of improper priors, to an ill-defined variational objective due to singularity of the approximating distribution relative to the true posterior. Our analysis of the improper log uniform prior used in variational Gaussian dropout suggests the pathologies are generally irredeemable, and that the algorithm still works only because the variational formulation annuls some of the pathologies. To address the singularity issue, we proffer Quasi-KL (QKL) divergence, a new approximate inference objective for approximation of high-dimensional distributions. We show that motivations for variational Bernoulli dropout based on discretisation and noise have QKL as a limit. Properties of QKL are studied both theoretically and on a simple practical example which shows that the QKL-optimal approximation of a full rank Gaussian with a degenerate one naturally leads to the Principal Component Analysis solution.
Variational Gaussian Dropout is not Bayesian
Nov 08, 2017Gaussian multiplicative noise is commonly used as a stochastic regularisation technique in training of deterministic neural networks. A recent paper reinterpreted the technique as a specific algorithm for approximate inference in Bayesian neural networks; several extensions ensued. We show that the log-uniform prior used in all the above publications does not generally induce a proper posterior, and thus Bayesian inference in such models is ill-posed. Independent of the log-uniform prior, the correlated weight noise approximation has further issues leading to either infinite objective or high risk of overfitting. The above implies that the reported sparsity of obtained solutions cannot be explained by Bayesian or the related minimum description length arguments. We thus study the objective from a non-Bayesian perspective, provide its previously unknown analytical form which allows exact gradient evaluation, and show that the later proposed additive reparametrisation introduces minima not present in the original multiplicative parametrisation. Implications and future research directions are discussed.
Adversarial Examples, Uncertainty, and Transfer Testing Robustness in Gaussian Process Hybrid Deep Networks
Jul 08, 2017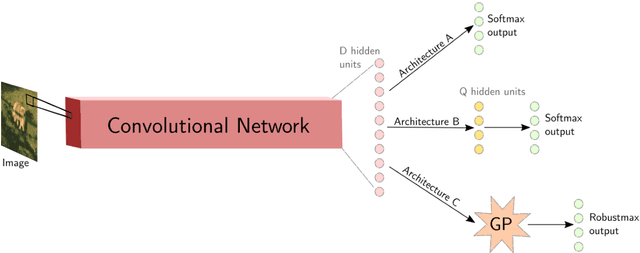
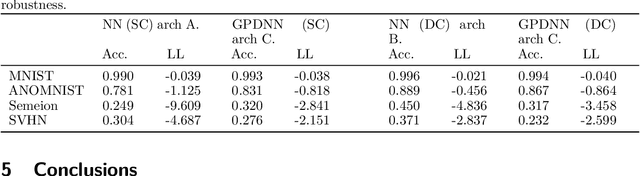
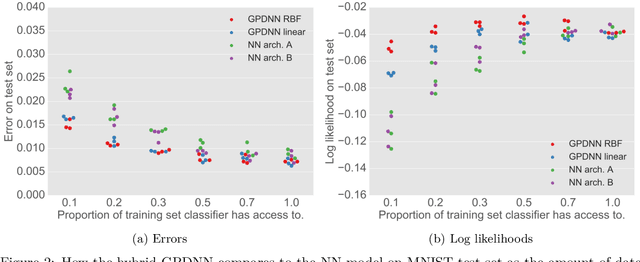
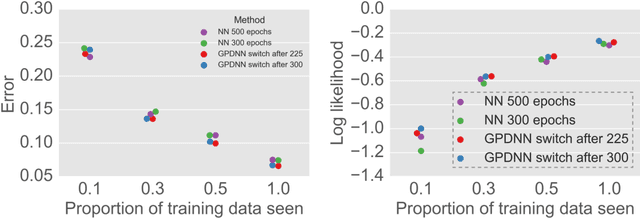
Deep neural networks (DNNs) have excellent representative power and are state of the art classifiers on many tasks. However, they often do not capture their own uncertainties well making them less robust in the real world as they overconfidently extrapolate and do not notice domain shift. Gaussian processes (GPs) with RBF kernels on the other hand have better calibrated uncertainties and do not overconfidently extrapolate far from data in their training set. However, GPs have poor representational power and do not perform as well as DNNs on complex domains. In this paper we show that GP hybrid deep networks, GPDNNs, (GPs on top of DNNs and trained end-to-end) inherit the nice properties of both GPs and DNNs and are much more robust to adversarial examples. When extrapolating to adversarial examples and testing in domain shift settings, GPDNNs frequently output high entropy class probabilities corresponding to essentially "don't know". GPDNNs are therefore promising as deep architectures that know when they don't know.
GPflow: A Gaussian process library using TensorFlow
Oct 27, 2016
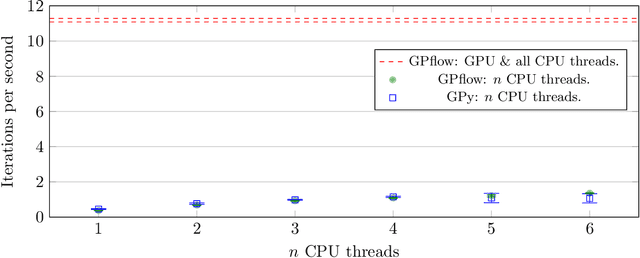

GPflow is a Gaussian process library that uses TensorFlow for its core computations and Python for its front end. The distinguishing features of GPflow are that it uses variational inference as the primary approximation method, provides concise code through the use of automatic differentiation, has been engineered with a particular emphasis on software testing and is able to exploit GPU hardware.
On Sparse variational methods and the Kullback-Leibler divergence between stochastic processes
Dec 04, 2015The variational framework for learning inducing variables (Titsias, 2009a) has had a large impact on the Gaussian process literature. The framework may be interpreted as minimizing a rigorously defined Kullback-Leibler divergence between the approximating and posterior processes. To our knowledge this connection has thus far gone unremarked in the literature. In this paper we give a substantial generalization of the literature on this topic. We give a new proof of the result for infinite index sets which allows inducing points that are not data points and likelihoods that depend on all function values. We then discuss augmented index sets and show that, contrary to previous works, marginal consistency of augmentation is not enough to guarantee consistency of variational inference with the original model. We then characterize an extra condition where such a guarantee is obtainable. Finally we show how our framework sheds light on interdomain sparse approximations and sparse approximations for Cox processes.
MCMC for Variationally Sparse Gaussian Processes
Jun 12, 2015
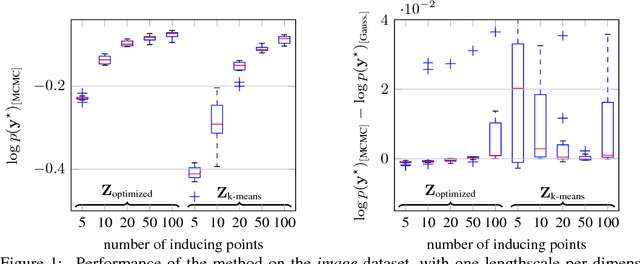
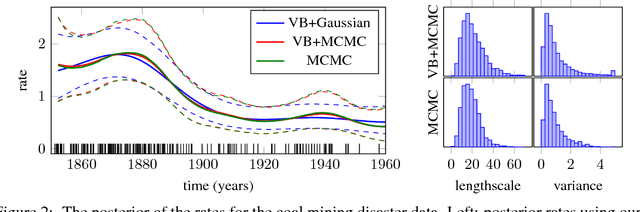

Gaussian process (GP) models form a core part of probabilistic machine learning. Considerable research effort has been made into attacking three issues with GP models: how to compute efficiently when the number of data is large; how to approximate the posterior when the likelihood is not Gaussian and how to estimate covariance function parameter posteriors. This paper simultaneously addresses these, using a variational approximation to the posterior which is sparse in support of the function but otherwise free-form. The result is a Hybrid Monte-Carlo sampling scheme which allows for a non-Gaussian approximation over the function values and covariance parameters simultaneously, with efficient computations based on inducing-point sparse GPs. Code to replicate each experiment in this paper will be available shortly.