 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are biased to overestimate profoundness
Oct 22, 2023



Recent advancements in natural language processing by large language models (LLMs), such as GPT-4, have been suggested to approach Artificial General Intelligence. And yet, it is still under dispute whether LLMs possess similar reasoning abilities to humans. This study evaluates GPT-4 and various other LLMs in judging the profoundness of mundane, motivational, and pseudo-profound statements. We found a significant statement-to-statement correlation between the LLMs and humans, irrespective of the type of statements and the prompting technique used. However, LLMs systematically overestimate the profoundness of nonsensical statements, with the exception of Tk-instruct, which uniquely underestimates the profoundness of statements. Only few-shot learning prompts, as opposed to chain-of-thought prompting, draw LLMs ratings closer to humans. Furthermore, this work provides insights into the potential biases induced by Reinforcement Learning from Human Feedback (RLHF), inducing an increase in the bias to overestimate the profoundness of statements.
GPflow: A Gaussian process library using TensorFlow
Oct 27, 2016
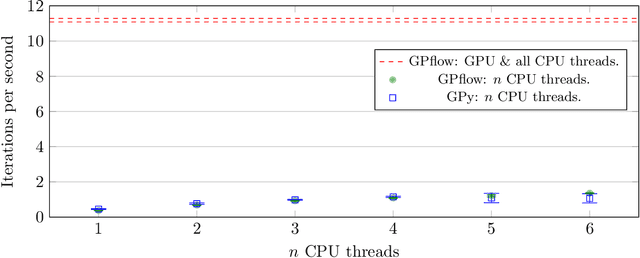

GPflow is a Gaussian process library that uses TensorFlow for its core computations and Python for its front end. The distinguishing features of GPflow are that it uses variational inference as the primary approximation method, provides concise code through the use of automatic differentiation, has been engineered with a particular emphasis on software testing and is able to exploit GPU hardware.