 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEWT
Papers and Code
Linear Reservoir: A Diagonalization-Based Optimization
Feb 23, 2026We introduce a diagonalization-based optimization for Linear Echo State Networks (ESNs) that reduces the per-step computational complexity of reservoir state updates from O(N^2) to O(N). By reformulating reservoir dynamics in the eigenbasis of the recurrent matrix, the recurrent update becomes a set of independent element-wise operations, eliminating the matrix multiplication. We further propose three methods to use our optimization depending on the situation: (i) Eigenbasis Weight Transformation (EWT), which preserves the dynamics of standard and trained Linear ESNs, (ii) End-to-End Eigenbasis Training (EET), which directly optimizes readout weights in the transformed space and (iii) Direct Parameter Generation (DPG), that bypasses matrix diagonalization by directly sampling eigenvalues and eigenvectors, achieving comparable performance than standard Linear ESNs. Across all experiments, both our methods preserve predictive accuracy while offering significant computational speedups, making them a replacement of standard Linear ESNs computations and training, and suggesting a shift of paradigm in linear ESN towards the direct selection of eigenvalues.
EWT: Efficient Wavelet-Transformer for Single Image Denoising
Apr 13, 2023Transformer-based image denoising methods have achieved encouraging results in the past year. However, it must uses linear operations to model long-range dependencies, which greatly increases model inference time and consumes GPU storage space. Compared with convolutional neural network-based methods, current Transformer-based image denoising methods cannot achieve a balance between performance improvement and resource consumption. In this paper, we propose an Efficient Wavelet Transformer (EWT) for image denoising. Specifically, we use Discrete Wavelet Transform (DWT) and Inverse Wavelet Transform (IWT) for downsampling and upsampling, respectively. This method can fully preserve the image features while reducing the image resolution, thereby greatly reducing the device resource consumption of the Transformer model. Furthermore, we propose a novel Dual-stream Feature Extraction Block (DFEB) to extract image features at different levels, which can further reduce model inference time and GPU memory usage. Experiments show that our method speeds up the original Transformer by more than 80%, reduces GPU memory usage by more than 60%, and achieves excellent denoising results. All code will be public.
A Novel Method Combines Moving Fronts, Data Decomposition and Deep Learning to Forecast Intricate Time Series
Mar 11, 2023A univariate time series with high variability can pose a challenge even to Deep Neural Network (DNN). To overcome this, a univariate time series is decomposed into simpler constituent series, whose sum equals the original series. As demonstrated in this article, the conventional one-time decomposition technique suffers from a leak of information from the future, referred to as a data leak. In this work, a novel Moving Front (MF) method is proposed to prevent data leakage, so that the decomposed series can be treated like other time series. Indian Summer Monsoon Rainfall (ISMR) is a very complex time series, which poses a challenge to DNN and is therefore selected as an example. From the many signal processing tools available, Empirical Wavelet Transform (EWT) was chosen for decomposing the ISMR into simpler constituent series, as it was found to be more effective than the other popular algorithm, Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN). The proposed MF method was used to generate the constituent leakage-free time series. Predictions and forecasts were made by state-of-the-art Long and Short-Term Memory (LSTM) network architecture, especially suitable for making predictions of sequential patterns. The constituent MF series has been divided into training, testing, and forecasting. It has been found that the model (EWT-MF-LSTM) developed here made exceptionally good train and test predictions, as well as Walk-Forward Validation (WFV), forecasts with Performance Parameter ($PP$) values of 0.99, 0.86, and 0.95, respectively, where $PP$ = 1.0 signifies perfect reproduction of the data.
Random vector functional link neural network based ensemble deep learning for short-term load forecasting
Jul 30, 2021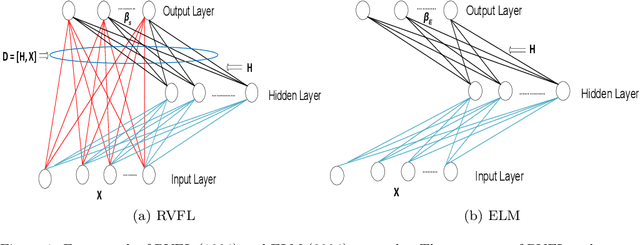
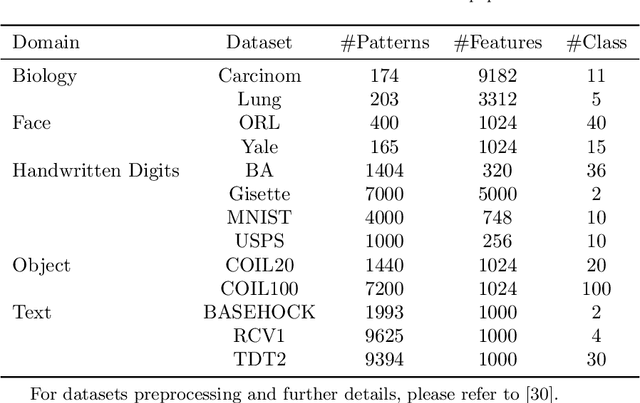
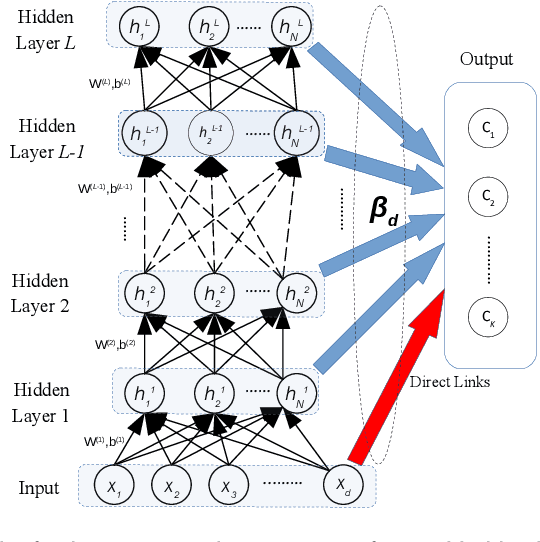
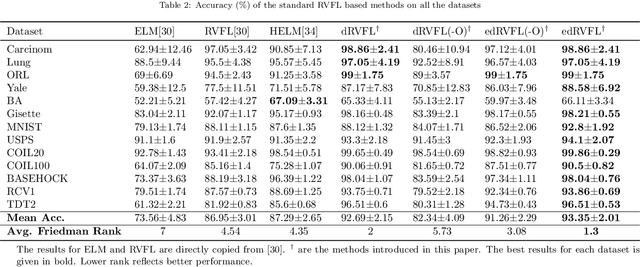
Electricity load forecasting is crucial for the power systems' planning and maintenance. However, its un-stationary and non-linear characteristics impose significant difficulties in anticipating future demand. This paper proposes a novel ensemble deep Random Vector Functional Link (edRVFL) network for electricity load forecasting. The weights of hidden layers are randomly initialized and kept fixed during the training process. The hidden layers are stacked to enforce deep representation learning. Then, the model generates the forecasts by ensembling the outputs of each layer. Moreover, we also propose to augment the random enhancement features by empirical wavelet transformation (EWT). The raw load data is decomposed by EWT in a walk-forward fashion, not introducing future data leakage problems in the decomposition process. Finally, all the sub-series generated by the EWT, including raw data, are fed into the edRVFL for forecasting purposes. The proposed model is evaluated on twenty publicly available time series from the Australian Energy Market Operator of the year 2020. The simulation results demonstrate the proposed model's superior performance over eleven forecasting methods in three error metrics and statistical tests on electricity load forecasting tasks.
Refining Implicit Argument Annotation For UCCA
May 26, 2020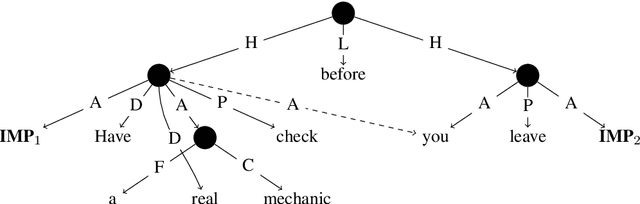
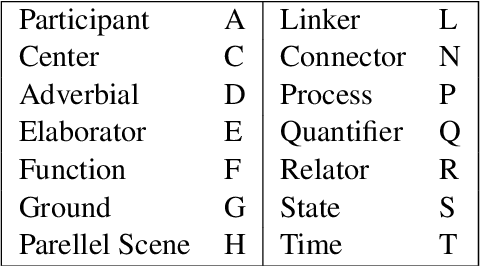

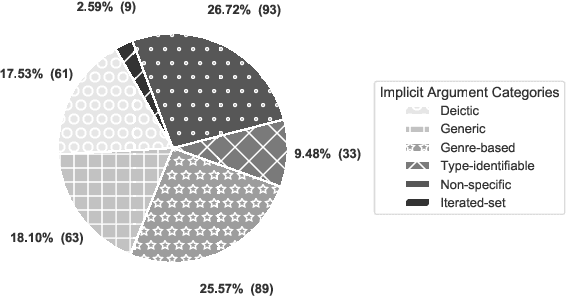
Few resources represent implicit roles for natural language understanding, and existing studies in NLP only make coarse distinctions between categories of arguments omitted from linguistic form. In this paper, we design a typology for fine-grained implicit argument annotation on top of Universal Conceptual Cognitive Annotation's foundational layer (Abend and Rappoport, 2013). Our design aligns with O'Gorman (2019)'s implicit role interpretation in a linguistic and computational model. The proposed implicit argument categorisation set consists of six types: Deictic, Generic, Genre-based, Type-identifiable, Non-specific, and Iterated-set. We corroborate the theory by reviewing and refining part of the UCCA EWT corpus and providing a new dataset alongside comparative analysis with other schemes. It is anticipated that our study will inspire tailored design of implicit role annotation in other meaning representation frameworks, and stimulate research in relevant fields, such as coreference resolution and question answering.
Parsing as Pretraining
Feb 05, 2020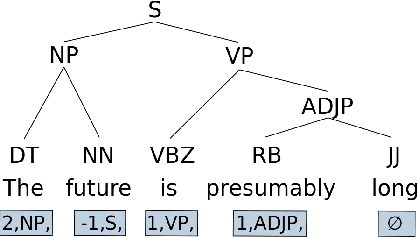
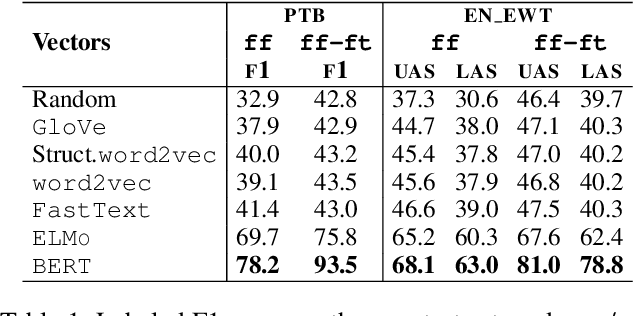
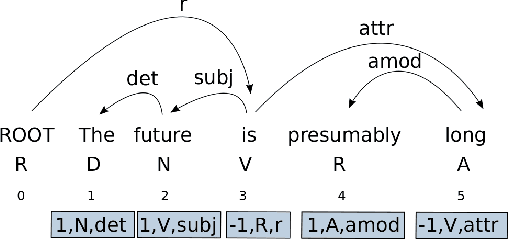
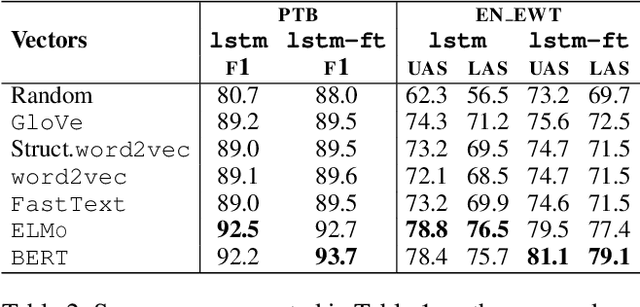
Recent analyses suggest that encoders pretrained for language modeling capture certain morpho-syntactic structure. However, probing frameworks for word vectors still do not report results on standard setups such as constituent and dependency parsing. This paper addresses this problem and does full parsing (on English) relying only on pretraining architectures -- and no decoding. We first cast constituent and dependency parsing as sequence tagging. We then use a single feed-forward layer to directly map word vectors to labels that encode a linearized tree. This is used to: (i) see how far we can reach on syntax modelling with just pretrained encoders, and (ii) shed some light about the syntax-sensitivity of different word vectors (by freezing the weights of the pretraining network during training). For evaluation, we use bracketing F1-score and LAS, and analyze in-depth differences across representations for span lengths and dependency displacements. The overall results surpass existing sequence tagging parsers on the PTB (93.5%) and end-to-end EN-EWT UD (78.8%).