 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D Tiny Object Detection
Papers and Code
Learning to See Inside Opaque Liquid Containers using Speckle Vibrometry
Jul 28, 2025Computer vision seeks to infer a wide range of information about objects and events. However, vision systems based on conventional imaging are limited to extracting information only from the visible surfaces of scene objects. For instance, a vision system can detect and identify a Coke can in the scene, but it cannot determine whether the can is full or empty. In this paper, we aim to expand the scope of computer vision to include the novel task of inferring the hidden liquid levels of opaque containers by sensing the tiny vibrations on their surfaces. Our method provides a first-of-a-kind way to inspect the fill level of multiple sealed containers remotely, at once, without needing physical manipulation and manual weighing. First, we propose a novel speckle-based vibration sensing system for simultaneously capturing scene vibrations on a 2D grid of points. We use our system to efficiently and remotely capture a dataset of vibration responses for a variety of everyday liquid containers. Then, we develop a transformer-based approach for analyzing the captured vibrations and classifying the container type and its hidden liquid level at the time of measurement. Our architecture is invariant to the vibration source, yielding correct liquid level estimates for controlled and ambient scene sound sources. Moreover, our model generalizes to unseen container instances within known classes (e.g., training on five Coke cans of a six-pack, testing on a sixth) and fluid levels. We demonstrate our method by recovering liquid levels from various everyday containers.
Randomize to Generalize: Domain Randomization for Runway FOD Detection
Sep 23, 2023Tiny Object Detection is challenging due to small size, low resolution, occlusion, background clutter, lighting conditions and small object-to-image ratio. Further, object detection methodologies often make underlying assumption that both training and testing data remain congruent. However, this presumption often leads to decline in performance when model is applied to out-of-domain(unseen) data. Techniques like synthetic image generation are employed to improve model performance by leveraging variations in input data. Such an approach typically presumes access to 3D-rendered datasets. In contrast, we propose a novel two-stage methodology Synthetic Randomized Image Augmentation (SRIA), carefully devised to enhance generalization capabilities of models encountering 2D datasets, particularly with lower resolution which is more practical in real-world scenarios. The first stage employs a weakly supervised technique to generate pixel-level segmentation masks. Subsequently, the second stage generates a batch-wise synthesis of artificial images, carefully designed with an array of diverse augmentations. The efficacy of proposed technique is illustrated on challenging foreign object debris (FOD) detection. We compare our results with several SOTA models including CenterNet, SSD, YOLOv3, YOLOv4, YOLOv5, and Outer Vit on a publicly available FOD-A dataset. We also construct an out-of-distribution test set encompassing 800 annotated images featuring a corpus of ten common categories. Notably, by harnessing merely 1.81% of objects from source training data and amalgamating with 29 runway background images, we generate 2227 synthetic images. Subsequent model retraining via transfer learning, utilizing enriched dataset generated by domain randomization, demonstrates significant improvement in detection accuracy. We report that detection accuracy improved from an initial 41% to 92% for OOD test set.
DirectMHP: Direct 2D Multi-Person Head Pose Estimation with Full-range Angles
Feb 14, 2023Existing head pose estimation (HPE) mainly focuses on single person with pre-detected frontal heads, which limits their applications in real complex scenarios with multi-persons. We argue that these single HPE methods are fragile and inefficient for Multi-Person Head Pose Estimation (MPHPE) since they rely on the separately trained face detector that cannot generalize well to full viewpoints, especially for heads with invisible face areas. In this paper, we focus on the full-range MPHPE problem, and propose a direct end-to-end simple baseline named DirectMHP. Due to the lack of datasets applicable to the full-range MPHPE, we firstly construct two benchmarks by extracting ground-truth labels for head detection and head orientation from public datasets AGORA and CMU Panoptic. They are rather challenging for having many truncated, occluded, tiny and unevenly illuminated human heads. Then, we design a novel end-to-end trainable one-stage network architecture by joint regressing locations and orientations of multi-head to address the MPHPE problem. Specifically, we regard pose as an auxiliary attribute of the head, and append it after the traditional object prediction. Arbitrary pose representation such as Euler angles is acceptable by this flexible design. Then, we jointly optimize these two tasks by sharing features and utilizing appropriate multiple losses. In this way, our method can implicitly benefit from more surroundings to improve HPE accuracy while maintaining head detection performance. We present comprehensive comparisons with state-of-the-art single HPE methods on public benchmarks, as well as superior baseline results on our constructed MPHPE datasets. Datasets and code are released in https://github.com/hnuzhy/DirectMHP.
A Normalized Gaussian Wasserstein Distance for Tiny Object Detection
Oct 26, 2021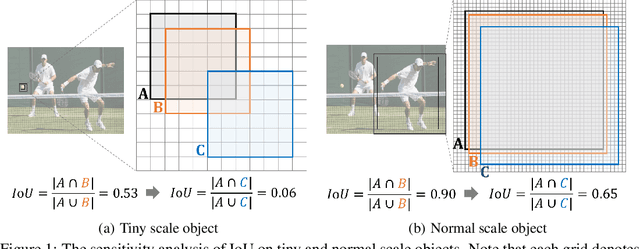
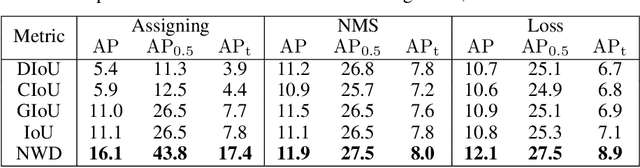
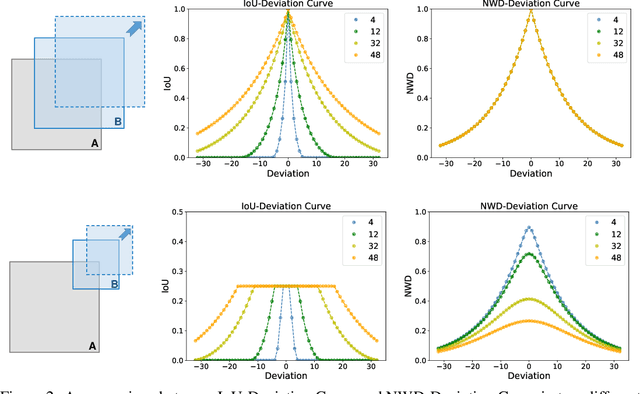

Detecting tiny objects is a very challenging problem since a tiny object only contains a few pixels in size. We demonstrate that state-of-the-art detectors do not produce satisfactory results on tiny objects due to the lack of appearance information. Our key observation is that Intersection over Union (IoU) based metrics such as IoU itself and its extensions are very sensitive to the location deviation of the tiny objects, and drastically deteriorate the detection performance when used in anchor-based detectors. To alleviate this, we propose a new evaluation metric using Wasserstein distance for tiny object detection. Specifically, we first model the bounding boxes as 2D Gaussian distributions and then propose a new metric dubbed Normalized Wasserstein Distance (NWD) to compute the similarity between them by their corresponding Gaussian distributions. The proposed NWD metric can be easily embedded into the assignment, non-maximum suppression, and loss function of any anchor-based detector to replace the commonly used IoU metric. We evaluate our metric on a new dataset for tiny object detection (AI-TOD) in which the average object size is much smaller than existing object detection datasets. Extensive experiments show that, when equipped with NWD metric, our approach yields performance that is 6.7 AP points higher than a standard fine-tuning baseline, and 6.0 AP points higher than state-of-the-art competitors.
One-stage Video Instance Segmentation: From Frame-in Frame-out to Clip-in Clip-out
Mar 12, 2022
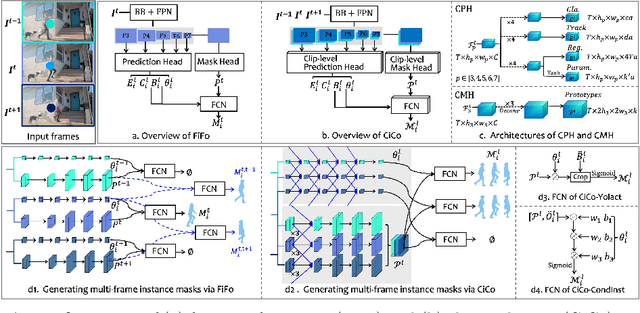


Many video instance segmentation (VIS) methods partition a video sequence into individual frames to detect and segment objects frame by frame. However, such a frame-in frame-out (FiFo) pipeline is ineffective to exploit the temporal information. Based on the fact that adjacent frames in a short clip are highly coherent in content, we propose to extend the one-stage FiFo framework to a clip-in clip-out (CiCo) one, which performs VIS clip by clip. Specifically, we stack FPN features of all frames in a short video clip to build a spatio-temporal feature cube, and replace the 2D conv layers in the prediction heads and the mask branch with 3D conv layers, forming clip-level prediction heads (CPH) and clip-level mask heads (CMH). Then the clip-level masks of an instance can be generated by feeding its box-level predictions from CPH and clip-level features from CMH into a small fully convolutional network. A clip-level segmentation loss is proposed to ensure that the generated instance masks are temporally coherent in the clip. The proposed CiCo strategy is free of inter-frame alignment, and can be easily embedded into existing FiFo based VIS approaches. To validate the generality and effectiveness of our CiCo strategy, we apply it to two representative FiFo methods, Yolact \cite{bolya2019yolact} and CondInst \cite{tian2020conditional}, resulting in two new one-stage VIS models, namely CiCo-Yolact and CiCo-CondInst, which achieve 37.1/37.3\%, 35.2/35.4\% and 17.2/18.0\% mask AP using the ResNet50 backbone, and 41.8/41.4\%, 38.0/38.9\% and 18.0/18.2\% mask AP using the Swin Transformer tiny backbone on YouTube-VIS 2019, 2021 and OVIS valid sets, respectively, recording new state-of-the-arts. Code and video demos of CiCo can be found at \url{https://github.com/MinghanLi/CiCo}.
Improved Pillar with Fine-grained Feature for 3D Object Detection
Oct 12, 2021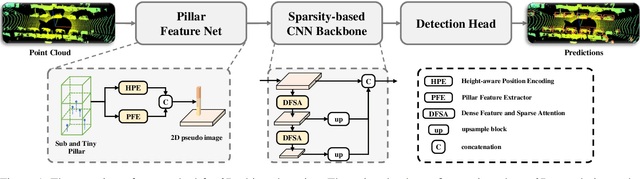
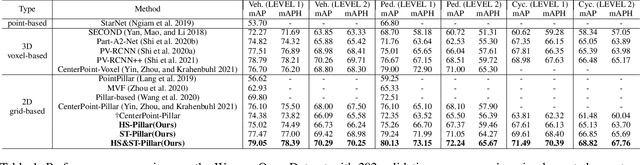
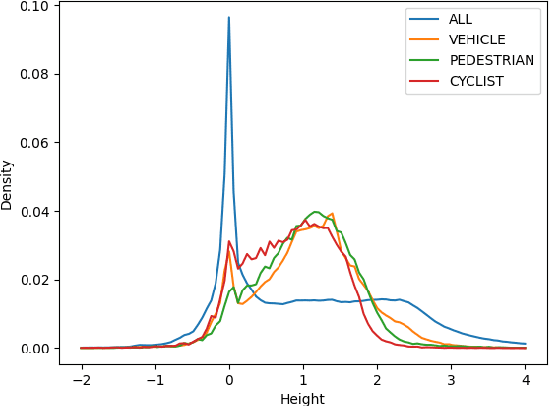
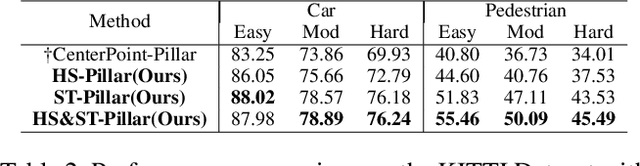
3D object detection with LiDAR point clouds plays an important role in autonomous driving perception module that requires high speed, stability and accuracy. However, the existing point-based methods are challenging to reach the speed requirements because of too many raw points, and the voxel-based methods are unable to ensure stable speed because of the 3D sparse convolution. In contrast, the 2D grid-based methods, such as PointPillar, can easily achieve a stable and efficient speed based on simple 2D convolution, but it is hard to get the competitive accuracy limited by the coarse-grained point clouds representation. So we propose an improved pillar with fine-grained feature based on PointPillar that can significantly improve detection accuracy. It consists of two modules, including height-aware sub-pillar and sparsity-based tiny-pillar, which get fine-grained representation respectively in the vertical and horizontal direction of 3D space. For height-aware sub-pillar, we introduce a height position encoding to keep height information of each sub-pillar during projecting to a 2D pseudo image. For sparsity-based tiny-pillar, we introduce sparsity-based CNN backbone stacked by dense feature and sparse attention module to extract feature with larger receptive field efficiently. Experimental results show that our proposed method significantly outperforms previous state-of-the-art 3D detection methods on the Waymo Open Dataset. The related code will be released to facilitate the academic and industrial study.