 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomize to Generalize: Domain Randomization for Runway FOD Detection
Sep 23, 2023Tiny Object Detection is challenging due to small size, low resolution, occlusion, background clutter, lighting conditions and small object-to-image ratio. Further, object detection methodologies often make underlying assumption that both training and testing data remain congruent. However, this presumption often leads to decline in performance when model is applied to out-of-domain(unseen) data. Techniques like synthetic image generation are employed to improve model performance by leveraging variations in input data. Such an approach typically presumes access to 3D-rendered datasets. In contrast, we propose a novel two-stage methodology Synthetic Randomized Image Augmentation (SRIA), carefully devised to enhance generalization capabilities of models encountering 2D datasets, particularly with lower resolution which is more practical in real-world scenarios. The first stage employs a weakly supervised technique to generate pixel-level segmentation masks. Subsequently, the second stage generates a batch-wise synthesis of artificial images, carefully designed with an array of diverse augmentations. The efficacy of proposed technique is illustrated on challenging foreign object debris (FOD) detection. We compare our results with several SOTA models including CenterNet, SSD, YOLOv3, YOLOv4, YOLOv5, and Outer Vit on a publicly available FOD-A dataset. We also construct an out-of-distribution test set encompassing 800 annotated images featuring a corpus of ten common categories. Notably, by harnessing merely 1.81% of objects from source training data and amalgamating with 29 runway background images, we generate 2227 synthetic images. Subsequent model retraining via transfer learning, utilizing enriched dataset generated by domain randomization, demonstrates significant improvement in detection accuracy. We report that detection accuracy improved from an initial 41% to 92% for OOD test set.
Controlled Caption Generation for Images Through Adversarial Attacks
Jul 07, 2021

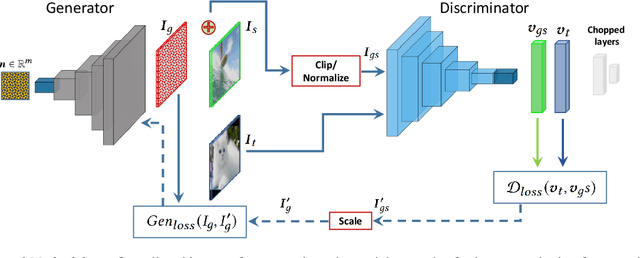
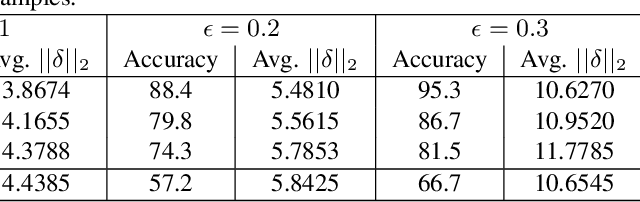
Deep learning is found to be vulnerable to adversarial examples. However, its adversarial susceptibility in image caption generation is under-explored. We study adversarial examples for vision and language models, which typically adopt an encoder-decoder framework consisting of two major components: a Convolutional Neural Network (i.e., CNN) for image feature extraction and a Recurrent Neural Network (RNN) for caption generation. In particular, we investigate attacks on the visual encoder's hidden layer that is fed to the subsequent recurrent network. The existing methods either attack the classification layer of the visual encoder or they back-propagate the gradients from the language model. In contrast, we propose a GAN-based algorithm for crafting adversarial examples for neural image captioning that mimics the internal representation of the CNN such that the resulting deep features of the input image enable a controlled incorrect caption generation through the recurrent network. Our contribution provides new insights for understanding adversarial attacks on vision systems with language component. The proposed method employs two strategies for a comprehensive evaluation. The first examines if a neural image captioning system can be misled to output targeted image captions. The second analyzes the possibility of keywords into the predicted captions. Experiments show that our algorithm can craft effective adversarial images based on the CNN hidden layers to fool captioning framework. Moreover, we discover the proposed attack to be highly transferable. Our work leads to new robustness implications for neural image captioning.
Empirical Autopsy of Deep Video Captioning Frameworks
Nov 21, 2019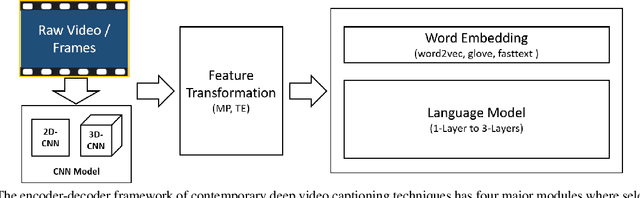
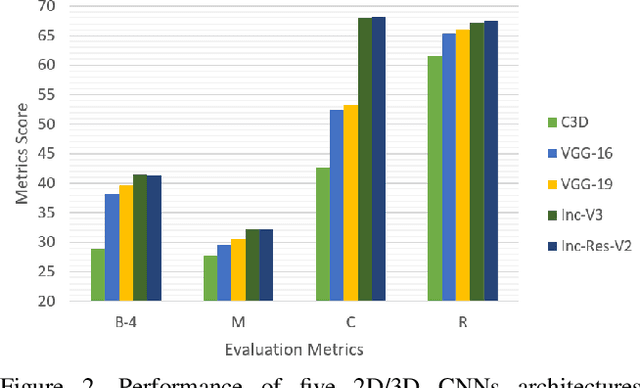
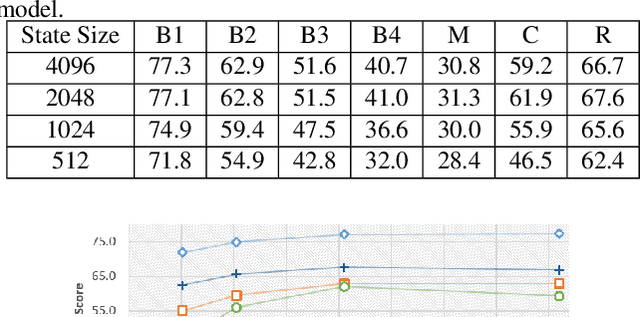
Contemporary deep learning based video captioning follows encoder-decoder framework. In encoder, visual features are extracted with 2D/3D Convolutional Neural Networks (CNNs) and a transformed version of those features is passed to the decoder. The decoder uses word embeddings and a language model to map visual features to natural language captions. Due to its composite nature, the encoder-decoder pipeline provides the freedom of multiple choices for each of its components, e.g the choices of CNNs models, feature transformations, word embeddings, and language models etc. Component selection can have drastic effects on the overall video captioning performance. However, current literature is void of any systematic investigation in this regard. This article fills this gap by providing the first thorough empirical analysis of the role that each major component plays in a contemporary video captioning pipeline. We perform extensive experiments by varying the constituent components of the video captioning framework, and quantify the performance gains that are possible by mere component selection. We use the popular MSVD dataset as the test-bed, and demonstrate that substantial performance gains are possible by careful selection of the constituent components without major changes to the pipeline itself. These results are expected to provide guiding principles for future research in the fast growing direction of video captioning.
Spatio-Temporal Dynamics and Semantic Attribute Enriched Visual Encoding for Video Captioning
Feb 27, 2019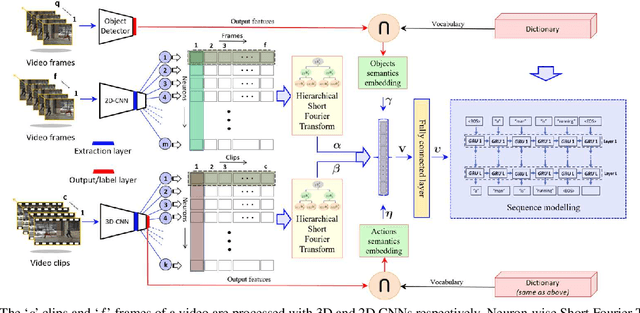
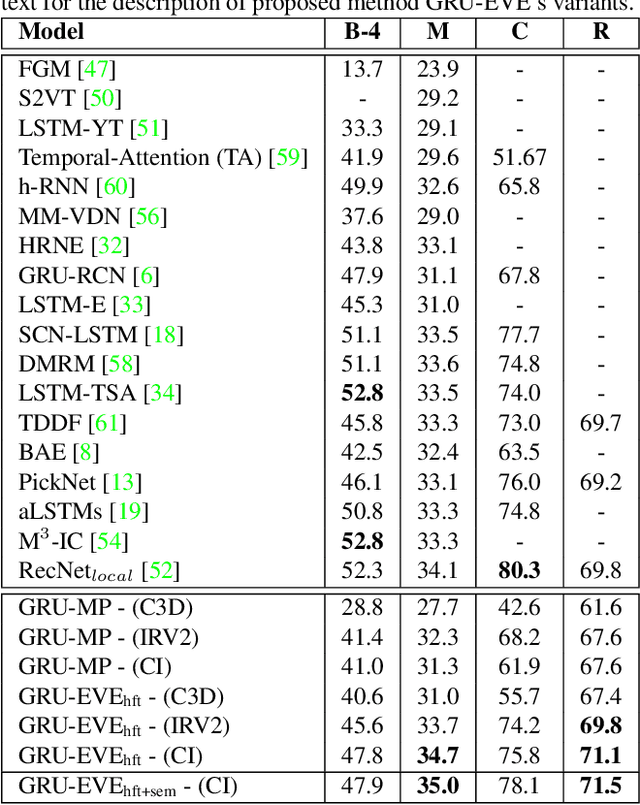
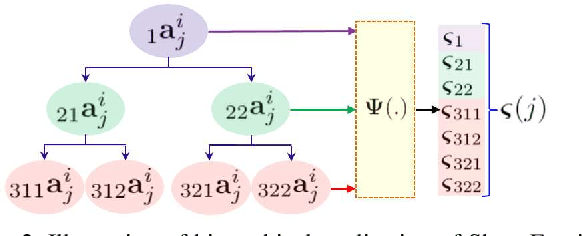
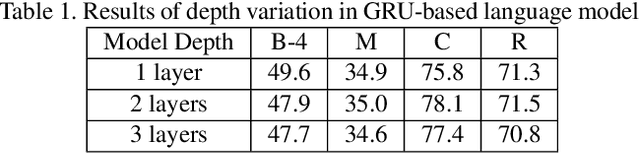
Automatic generation of video captions is a fundamental challenge in computer vision. Recent techniques typically employ a combination of Convolutional Neural Networks (CNNs) and Recursive Neural Networks (RNNs) for video captioning. These methods mainly focus on tailoring sequence learning through RNNs for better caption generation, whereas off-the-shelf visual features are borrowed from CNNs. We argue that careful designing of visual features for this task is equally important, and present a visual feature encoding technique to generate semantically rich captions using Gated Recurrent Units (GRUs). Our method embeds rich temporal dynamics in visual features by hierarchically applying Short Fourier Transform to CNN features of the whole video. It additionally derives high level semantics from an object detector to enrich the representation with spatial dynamics of the detected objects. The final representation is projected to a compact space and fed to a language model. By learning a relatively simple language model comprising two GRU layers, we establish new state-of-the-art on MSVD and MSR-VTT datasets for METEOR and ROUGE_L metrics.
Video Description: A Survey of Methods, Datasets and Evaluation Metrics
Jun 01, 2018
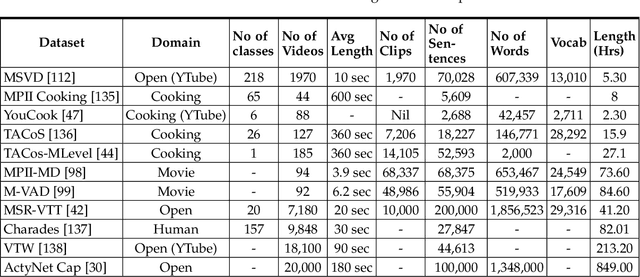

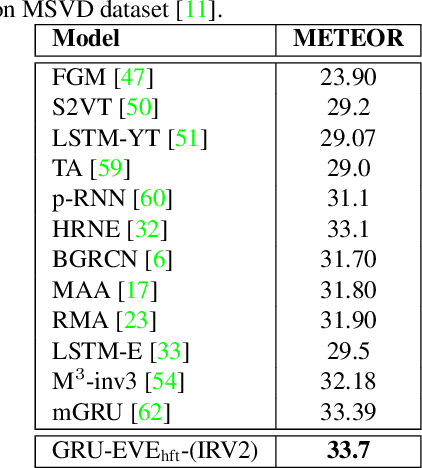
Automatic video description is useful for assisting the visually impaired, human computer interaction, robotics and video indexing. The past few years have seen a surge of research interest in this area due to the unprecedented success of deep learning in computer vision and natural language processing. Numerous methods, datasets and evaluation measures have been proposed in the literature calling the need for a comprehensive survey to better focus research efforts in this flourishing direction. This paper answers exactly to this need by surveying state of the art approaches including deep learning models; comparing benchmark datasets in terms of their domain, number of classes, and repository size; and identifying the pros and cons of various evaluation metrics such as BLEU, ROUGE, METEOR, CIDEr, SPICE and WMD. Our survey shows that video description research has a long way to go before it can match human performance and that the main reasons for this shortfall are twofold. Firstly, existing datasets do not adequately represent the diversity in open domain videos and complex linguistic structures. Secondly, current measures of evaluation are not aligned with human judgement. For example, the same video can have very different, yet correct descriptions. We conclude that there is a need for improvement in evaluation measures as well as datasets in terms of size, diversity and annotation accuracy because they directly influence the development of better video description models. From an algorithmic point of view, diagnosis of the description quality is challenging because of the difficultly to assess the level of contribution from visual features compared to the bias that comes naturally from the language model adopted.