 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Description: A Survey of Methods, Datasets and Evaluation Metrics
Paper and Code
Jun 01, 2018
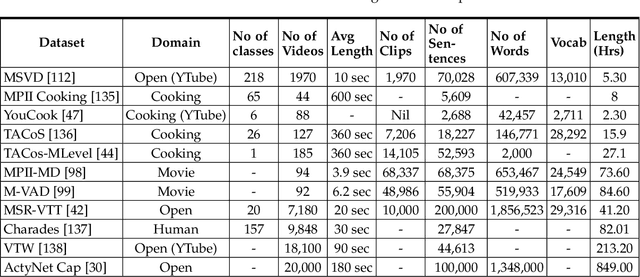

Automatic video description is useful for assisting the visually impaired, human computer interaction, robotics and video indexing. The past few years have seen a surge of research interest in this area due to the unprecedented success of deep learning in computer vision and natural language processing. Numerous methods, datasets and evaluation measures have been proposed in the literature calling the need for a comprehensive survey to better focus research efforts in this flourishing direction. This paper answers exactly to this need by surveying state of the art approaches including deep learning models; comparing benchmark datasets in terms of their domain, number of classes, and repository size; and identifying the pros and cons of various evaluation metrics such as BLEU, ROUGE, METEOR, CIDEr, SPICE and WMD. Our survey shows that video description research has a long way to go before it can match human performance and that the main reasons for this shortfall are twofold. Firstly, existing datasets do not adequately represent the diversity in open domain videos and complex linguistic structures. Secondly, current measures of evaluation are not aligned with human judgement. For example, the same video can have very different, yet correct descriptions. We conclude that there is a need for improvement in evaluation measures as well as datasets in terms of size, diversity and annotation accuracy because they directly influence the development of better video description models. From an algorithmic point of view, diagnosis of the description quality is challenging because of the difficultly to assess the level of contribution from visual features compared to the bias that comes naturally from the language model adopted.