 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled Caption Generation for Images Through Adversarial Attacks
Paper and Code


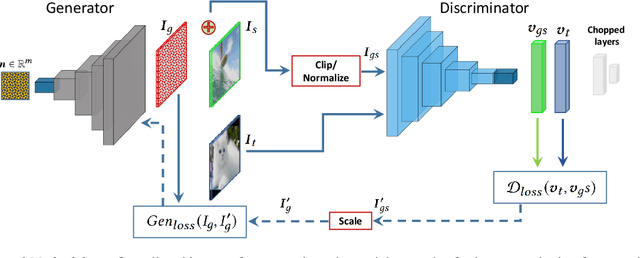
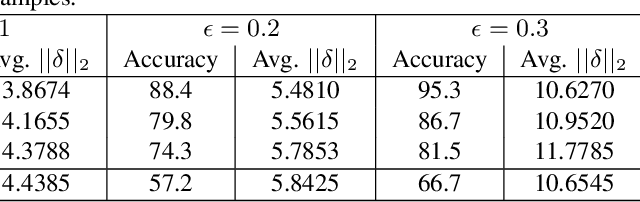
Deep learning is found to be vulnerable to adversarial examples. However, its adversarial susceptibility in image caption generation is under-explored. We study adversarial examples for vision and language models, which typically adopt an encoder-decoder framework consisting of two major components: a Convolutional Neural Network (i.e., CNN) for image feature extraction and a Recurrent Neural Network (RNN) for caption generation. In particular, we investigate attacks on the visual encoder's hidden layer that is fed to the subsequent recurrent network. The existing methods either attack the classification layer of the visual encoder or they back-propagate the gradients from the language model. In contrast, we propose a GAN-based algorithm for crafting adversarial examples for neural image captioning that mimics the internal representation of the CNN such that the resulting deep features of the input image enable a controlled incorrect caption generation through the recurrent network. Our contribution provides new insights for understanding adversarial attacks on vision systems with language component. The proposed method employs two strategies for a comprehensive evaluation. The first examines if a neural image captioning system can be misled to output targeted image captions. The second analyzes the possibility of keywords into the predicted captions. Experiments show that our algorithm can craft effective adversarial images based on the CNN hidden layers to fool captioning framework. Moreover, we discover the proposed attack to be highly transferable. Our work leads to new robustness implications for neural image captioning.