 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Efficient Chest X-ray Report Generation with One-step Block Diffusion
Apr 10, 2026Chest X-ray report generation (CXR-RG) has the potential to substantially alleviate radiologists' workload. However, conventional autoregressive vision--language models (VLMs) suffer from high inference latency due to sequential token decoding. Diffusion-based models offer a promising alternative through parallel generation, but they still require multiple denoising iterations. Compressing multi-step denoising to a single step could further reduce latency, but often degrades textual coherence due to the mean-field bias introduced by token-factorized denoisers. To address this challenge, we propose \textbf{ECHO}, an efficient diffusion-based VLM (dVLM) for chest X-ray report generation. ECHO enables stable one-step-per-block inference via a novel Direct Conditional Distillation (DCD) framework, which mitigates the mean-field limitation by constructing unfactorized supervision from on-policy diffusion trajectories to encode joint token dependencies. In addition, we introduce a Response-Asymmetric Diffusion (RAD) training strategy that further improves training efficiency while maintaining model effectiveness. Extensive experiments demonstrate that ECHO surpasses state-of-the-art autoregressive methods, improving RaTE and SemScore by \textbf{64.33\%} and \textbf{60.58\%} respectively, while achieving an \textbf{$8\times$} inference speedup without compromising clinical accuracy.
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
Jul 01, 2024



Visual mathematical reasoning, as a fundamental visual reasoning ability, has received widespread attention from the Large Multimodal Models (LMMs) community. Existing benchmarks, such as MathVista and MathVerse, focus more on the result-oriented performance but neglect the underlying principles in knowledge acquisition and generalization. Inspired by human-like mathematical reasoning, we introduce WE-MATH, the first benchmark specifically designed to explore the problem-solving principles beyond end-to-end performance. We meticulously collect and categorize 6.5K visual math problems, spanning 67 hierarchical knowledge concepts and five layers of knowledge granularity. We decompose composite problems into sub-problems according to the required knowledge concepts and introduce a novel four-dimensional metric, namely Insufficient Knowledge (IK), Inadequate Generalization (IG), Complete Mastery (CM), and Rote Memorization (RM), to hierarchically assess inherent issues in LMMs' reasoning process. With WE-MATH, we conduct a thorough evaluation of existing LMMs in visual mathematical reasoning and reveal a negative correlation between solving steps and problem-specific performance. We confirm the IK issue of LMMs can be effectively improved via knowledge augmentation strategies. More notably, the primary challenge of GPT-4o has significantly transitioned from IK to IG, establishing it as the first LMM advancing towards the knowledge generalization stage. In contrast, other LMMs exhibit a marked inclination towards Rote Memorization - they correctly solve composite problems involving multiple knowledge concepts yet fail to answer sub-problems. We anticipate that WE-MATH will open new pathways for advancements in visual mathematical reasoning for LMMs. The WE-MATH data and evaluation code are available at https://github.com/We-Math/We-Math.
Point-Voxel Absorbing Graph Representation Learning for Event Stream based Recognition
Jun 08, 2023Considering the balance of performance and efficiency, sampled point and voxel methods are usually employed to down-sample dense events into sparse ones. After that, one popular way is to leverage a graph model which treats the sparse points/voxels as nodes and adopts graph neural networks (GNNs) to learn the representation for event data. Although good performance can be obtained, however, their results are still limited mainly due to two issues. (1) Existing event GNNs generally adopt the additional max (or mean) pooling layer to summarize all node embeddings into a single graph-level representation for the whole event data representation. However, this approach fails to capture the importance of graph nodes and also fails to be fully aware of the node representations. (2) Existing methods generally employ either a sparse point or voxel graph representation model which thus lacks consideration of the complementary between these two types of representation models. To address these issues, in this paper, we propose a novel dual point-voxel absorbing graph representation learning for event stream data representation. To be specific, given the input event stream, we first transform it into the sparse event cloud and voxel grids and build dual absorbing graph models for them respectively. Then, we design a novel absorbing graph convolutional network (AGCN) for our dual absorbing graph representation and learning. The key aspect of the proposed AGCN is its ability to effectively capture the importance of nodes and thus be fully aware of node representations in summarizing all node representations through the introduced absorbing nodes. Finally, the event representations of dual learning branches are concatenated together to extract the complementary information of two cues. The output is then fed into a linear layer for event data classification.
HARDVS: Revisiting Human Activity Recognition with Dynamic Vision Sensors
Nov 17, 2022



The main streams of human activity recognition (HAR) algorithms are developed based on RGB cameras which are suffered from illumination, fast motion, privacy-preserving, and large energy consumption. Meanwhile, the biologically inspired event cameras attracted great interest due to their unique features, such as high dynamic range, dense temporal but sparse spatial resolution, low latency, low power, etc. As it is a newly arising sensor, even there is no realistic large-scale dataset for HAR. Considering its great practical value, in this paper, we propose a large-scale benchmark dataset to bridge this gap, termed HARDVS, which contains 300 categories and more than 100K event sequences. We evaluate and report the performance of multiple popular HAR algorithms, which provide extensive baselines for future works to compare. More importantly, we propose a novel spatial-temporal feature learning and fusion framework, termed ESTF, for event stream based human activity recognition. It first projects the event streams into spatial and temporal embeddings using StemNet, then, encodes and fuses the dual-view representations using Transformer networks. Finally, the dual features are concatenated and fed into a classification head for activity prediction. Extensive experiments on multiple datasets fully validated the effectiveness of our model. Both the dataset and source code will be released on \url{https://github.com/Event-AHU/HARDVS}.
NomMer: Nominate Synergistic Context in Vision Transformer for Visual Recognition
Nov 25, 2021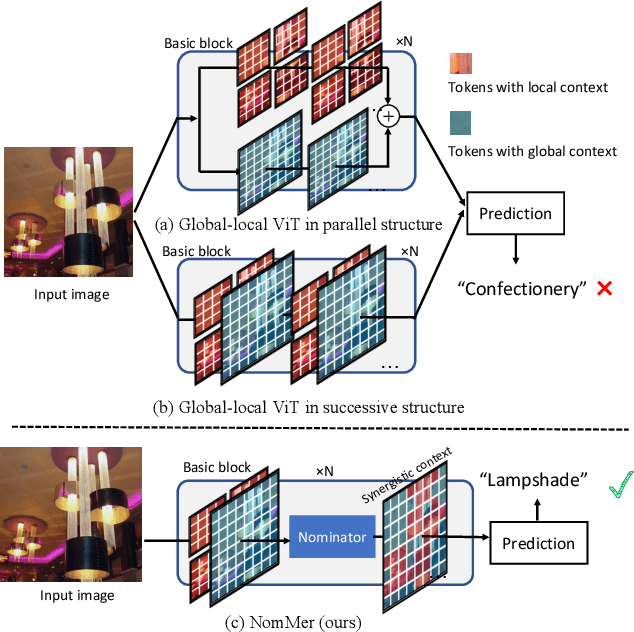
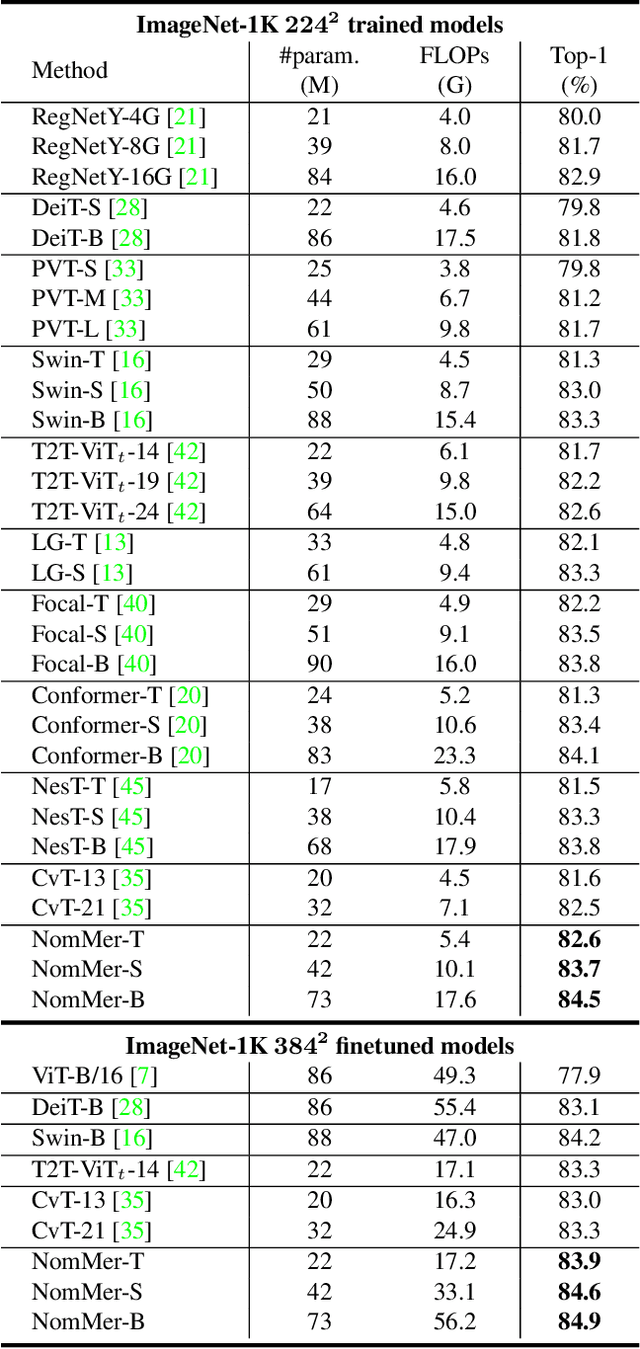
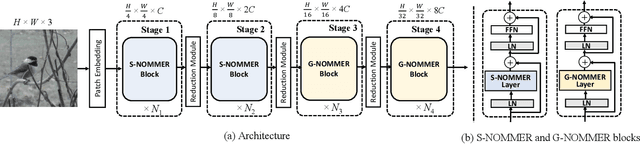
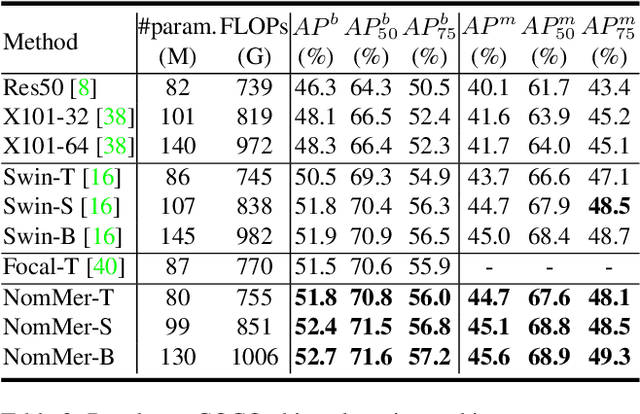
Recently, Vision Transformers (ViT), with the self-attention (SA) as the de facto ingredients, have demonstrated great potential in the computer vision community. For the sake of trade-off between efficiency and performance, a group of works merely perform SA operation within local patches, whereas the global contextual information is abandoned, which would be indispensable for visual recognition tasks. To solve the issue, the subsequent global-local ViTs take a stab at marrying local SA with global one in parallel or alternative way in the model. Nevertheless, the exhaustively combined local and global context may exist redundancy for various visual data, and the receptive field within each layer is fixed. Alternatively, a more graceful way is that global and local context can adaptively contribute per se to accommodate different visual data. To achieve this goal, we in this paper propose a novel ViT architecture, termed NomMer, which can dynamically Nominate the synergistic global-local context in vision transforMer. By investigating the working pattern of our proposed NomMer, we further explore what context information is focused. Beneficial from this "dynamic nomination" mechanism, without bells and whistles, the NomMer can not only achieve 84.5% Top-1 classification accuracy on ImageNet with only 73M parameters, but also show promising performance on dense prediction tasks, i.e., object detection and semantic segmentation. The code and models will be made publicly available at~\url{https://github.com/NomMer1125/NomMer.