 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-COAL: A Unified Framework for Cross-Modality Synthesis and Super-Resolution of MR Images
Nov 14, 2023



Cross-modality synthesis (CMS), super-resolution (SR), and their combination (CMSR) have been extensively studied for magnetic resonance imaging (MRI). Their primary goals are to enhance the imaging quality by synthesizing the desired modality and reducing the slice thickness. Despite the promising synthetic results, these techniques are often tailored to specific tasks, thereby limiting their adaptability to complex clinical scenarios. Therefore, it is crucial to build a unified network that can handle various image synthesis tasks with arbitrary requirements of modality and resolution settings, so that the resources for training and deploying the models can be greatly reduced. However, none of the previous works is capable of performing CMS, SR, and CMSR using a unified network. Moreover, these MRI reconstruction methods often treat alias frequencies improperly, resulting in suboptimal detail restoration. In this paper, we propose a Unified Co-Modulated Alias-free framework (Uni-COAL) to accomplish the aforementioned tasks with a single network. The co-modulation design of the image-conditioned and stochastic attribute representations ensures the consistency between CMS and SR, while simultaneously accommodating arbitrary combinations of input/output modalities and thickness. The generator of Uni-COAL is also designed to be alias-free based on the Shannon-Nyquist signal processing framework, ensuring effective suppression of alias frequencies. Additionally, we leverage the semantic prior of Segment Anything Model (SAM) to guide Uni-COAL, ensuring a more authentic preservation of anatomical structures during synthesis. Experiments on three datasets demonstrate that Uni-COAL outperforms the alternatives in CMS, SR, and CMSR tasks for MR images, which highlights its generalizability to wide-range applications.
RCPS: Rectified Contrastive Pseudo Supervision for Semi-Supervised Medical Image Segmentation
Jan 13, 2023



Medical image segmentation methods are generally designed as fully-supervised to guarantee model performance, which require a significant amount of expert annotated samples that are high-cost and laborious. Semi-supervised image segmentation can alleviate the problem by utilizing a large number of unlabeled images along with limited labeled images. However, learning a robust representation from numerous unlabeled images remains challenging due to potential noise in pseudo labels and insufficient class separability in feature space, which undermines the performance of current semi-supervised segmentation approaches. To address the issues above, we propose a novel semi-supervised segmentation method named as Rectified Contrastive Pseudo Supervision (RCPS), which combines a rectified pseudo supervision and voxel-level contrastive learning to improve the effectiveness of semi-supervised segmentation. Particularly, we design a novel rectification strategy for the pseudo supervision method based on uncertainty estimation and consistency regularization to reduce the noise influence in pseudo labels. Furthermore, we introduce a bidirectional voxel contrastive loss to the network to ensure intra-class consistency and inter-class contrast in feature space, which increases class separability in the segmentation. The proposed RCPS segmentation method has been validated on two public datasets and an in-house clinical dataset. Experimental results reveal that the proposed method yields better segmentation performance compared with the state-of-the-art methods in semi-supervised medical image segmentation. The source code is available at https://github.com/hsiangyuzhao/RCPS.
TBI-GAN: An Adversarial Learning Approach for Data Synthesis on Traumatic Brain Segmentation
Aug 12, 2022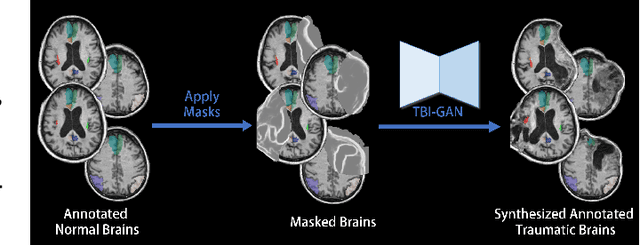
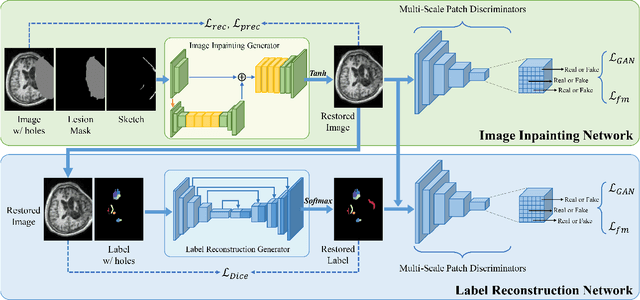
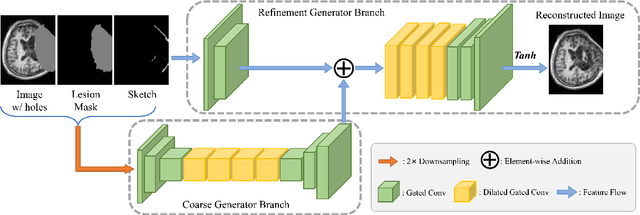
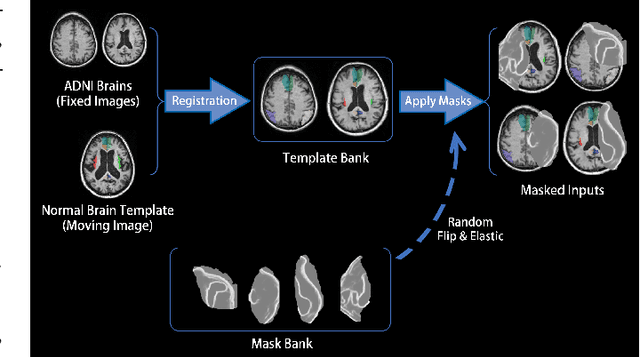
Brain network analysis for traumatic brain injury (TBI) patients is critical for its consciousness level assessment and prognosis evaluation, which requires the segmentation of certain consciousness-related brain regions. However, it is difficult to construct a TBI segmentation model as manually annotated MR scans of TBI patients are hard to collect. Data augmentation techniques can be applied to alleviate the issue of data scarcity. However, conventional data augmentation strategies such as spatial and intensity transformation are unable to mimic the deformation and lesions in traumatic brains, which limits the performance of the subsequent segmentation task. To address these issues, we propose a novel medical image inpainting model named TBI-GAN to synthesize TBI MR scans with paired brain label maps. The main strength of our TBI-GAN method is that it can generate TBI images and corresponding label maps simultaneously, which has not been achieved in the previous inpainting methods for medical images. We first generate the inpainted image under the guidance of edge information following a coarse-to-fine manner, and then the synthesized intensity image is used as the prior for label inpainting. Furthermore, we introduce a registration-based template augmentation pipeline to increase the diversity of the synthesized image pairs and enhance the capacity of data augmentation. Experimental results show that the proposed TBI-GAN method can produce sufficient synthesized TBI images with high quality and valid label maps, which can greatly improve the 2D and 3D traumatic brain segmentation performance compared with the alternatives.