 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Unique Recovery of Transport Maps and Vector Fields from Finite Measure-Valued Data
Apr 09, 2026We establish guarantees for the unique recovery of vector fields and transport maps from finite measure-valued data, yielding new insights into generative models, data-driven dynamical systems, and PDE inverse problems. In particular, we provide general conditions under which a diffeomorphism can be uniquely identified from its pushforward action on finitely many densities, i.e., when the data $\{(ρ_j,f_\#ρ_j)\}_{j=1}^m$ uniquely determines $f$. As a corollary, we introduce a new metric which compares diffeomorphisms by measuring the discrepancy between finitely many pushforward densities in the space of probability measures. We also prove analogous results in an infinitesimal setting, where derivatives of the densities along a smooth vector field are observed, i.e., when $\{(ρ_j,\text{div} (ρ_j v))\}_{j=1}^m$ uniquely determines $v$. Our analysis makes use of the Whitney and Takens embedding theorems, which provide estimates on the required number of densities $m$, depending only on the intrinsic dimension of the problem. We additionally interpret our results through the lens of Perron--Frobenius and Koopman operators and demonstrate how our techniques lead to new guarantees for the well-posedness of certain PDE inverse problems related to continuity, advection, Fokker--Planck, and advection-diffusion-reaction equations. Finally, we present illustrative numerical experiments demonstrating the unique identification of transport maps from finitely many pushforward densities, and of vector fields from finitely many weighted divergence observations.
HV Metric For Time-Domain Full Waveform Inversion
Aug 23, 2025Full-waveform inversion (FWI) is a powerful technique for reconstructing high-resolution material parameters from seismic or ultrasound data. The conventional least-squares (\(L^{2}\)) misfit suffers from pronounced non-convexity that leads to \emph{cycle skipping}. Optimal-transport misfits, such as the Wasserstein distance, alleviate this issue; however, their use requires artificially converting the wavefields into probability measures, a preprocessing step that can modify critical amplitude and phase information of time-dependent wave data. We propose the \emph{HV metric}, a transport-based distance that acts naturally on signed signals, as an alternative metric for the \(L^{2}\) and Wasserstein objectives in time-domain FWI. After reviewing the metric's definition and its relationship to optimal transport, we derive closed-form expressions for the Fr\'echet derivative and Hessian of the map \(f \mapsto d_{\text{HV}}^2(f,g)\), enabling efficient adjoint-state implementations. A spectral analysis of the Hessian shows that, by tuning the hyperparameters \((\kappa,\lambda,\epsilon)\), the HV misfit seamlessly interpolates between \(L^{2}\), \(H^{-1}\), and \(H^{-2}\) norms, offering a tunable trade-off between the local point-wise matching and the global transport-based matching. Synthetic experiments on the Marmousi and BP benchmark models demonstrate that the HV metric-based objective function yields faster convergence and superior tolerance to poor initial models compared to both \(L^{2}\) and Wasserstein misfits. These results demonstrate the HV metric as a robust, geometry-preserving alternative for large-scale waveform inversion.
Learning Where to Learn: Training Distribution Selection for Provable OOD Performance
May 27, 2025Out-of-distribution (OOD) generalization remains a fundamental challenge in machine learning. Models trained on one data distribution often experience substantial performance degradation when evaluated on shifted or unseen domains. To address this challenge, the present paper studies the design of training data distributions that maximize average-case OOD performance. First, a theoretical analysis establishes a family of generalization bounds that quantify how the choice of training distribution influences OOD error across a predefined family of target distributions. These insights motivate the introduction of two complementary algorithmic strategies: (i) directly formulating OOD risk minimization as a bilevel optimization problem over the space of probability measures and (ii) minimizing a theoretical upper bound on OOD error. Last, the paper evaluates the two approaches across a range of function approximation and operator learning examples. The proposed methods significantly improve OOD accuracy over standard empirical risk minimization with a fixed distribution. These results highlight the potential of distribution-aware training as a principled and practical framework for robust OOD generalization.
Invariant Measures in Time-Delay Coordinates for Unique Dynamical System Identification
Nov 30, 2024



Invariant measures are widely used to compare chaotic dynamical systems, as they offer robustness to noisy data, uncertain initial conditions, and irregular sampling. However, large classes of systems with distinct transient dynamics can still exhibit the same asymptotic statistical behavior, which poses challenges when invariant measures alone are used to perform system identification. Motivated by Takens' seminal embedding theory, we propose studying invariant measures in time-delay coordinates, which exhibit enhanced sensitivity to the underlying dynamics. Our first result demonstrates that a single invariant measure in time-delay coordinates can be used to perform system identification up to a topological conjugacy. This result already surpasses the capabilities of invariant measures in the original state coordinate. Continuing to explore the power of delay-coordinates, we eliminate all ambiguity from the conjugacy relation by showing that unique system identification can be achieved using additional invariant measures in time-delay coordinates constructed from different observables. Our findings improve the effectiveness of invariant measures in system identification and broaden the scope of measure-theoretic approaches to modeling dynamical systems.
Sampling with Adaptive Variance for Multimodal Distributions
Nov 20, 2024
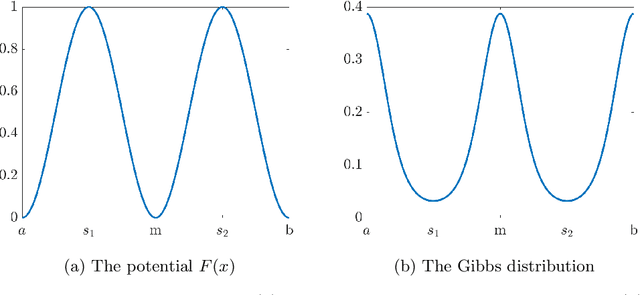
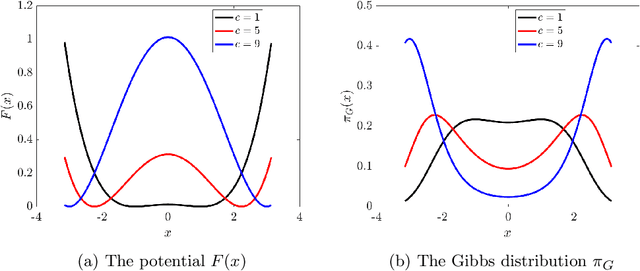
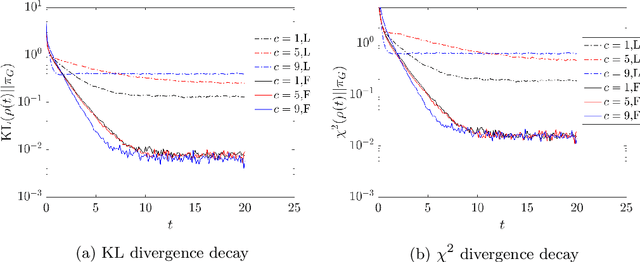
We propose and analyze a class of adaptive sampling algorithms for multimodal distributions on a bounded domain, which share a structural resemblance to the classic overdamped Langevin dynamics. We first demonstrate that this class of linear dynamics with adaptive diffusion coefficients and vector fields can be interpreted and analyzed as weighted Wasserstein gradient flows of the Kullback--Leibler (KL) divergence between the current distribution and the target Gibbs distribution, which directly leads to the exponential convergence of both the KL and $\chi^2$ divergences, with rates depending on the weighted Wasserstein metric and the Gibbs potential. We then show that a derivative-free version of the dynamics can be used for sampling without gradient information of the Gibbs potential and that for Gibbs distributions with nonconvex potentials, this approach could achieve significantly faster convergence than the classical overdamped Langevin dynamics. A comparison of the mean transition times between local minima of a nonconvex potential further highlights the better efficiency of the derivative-free dynamics in sampling.
Measure-Theoretic Time-Delay Embedding
Sep 13, 2024



The celebrated Takens' embedding theorem provides a theoretical foundation for reconstructing the full state of a dynamical system from partial observations. However, the classical theorem assumes that the underlying system is deterministic and that observations are noise-free, limiting its applicability in real-world scenarios. Motivated by these limitations, we rigorously establish a measure-theoretic generalization that adopts an Eulerian description of the dynamics and recasts the embedding as a pushforward map between probability spaces. Our mathematical results leverage recent advances in optimal transportation theory. Building on our novel measure-theoretic time-delay embedding theory, we have developed a new computational framework that forecasts the full state of a dynamical system from time-lagged partial observations, engineered with better robustness to handle sparse and noisy data. We showcase the efficacy and versatility of our approach through several numerical examples, ranging from the classic Lorenz-63 system to large-scale, real-world applications such as NOAA sea surface temperature forecasting and ERA5 wind field reconstruction.
Generative Modeling of Time-Dependent Densities via Optimal Transport and Projection Pursuit
Apr 19, 2023



Motivated by the computational difficulties incurred by popular deep learning algorithms for the generative modeling of temporal densities, we propose a cheap alternative which requires minimal hyperparameter tuning and scales favorably to high dimensional problems. In particular, we use a projection-based optimal transport solver [Meng et al., 2019] to join successive samples and subsequently use transport splines [Chewi et al., 2020] to interpolate the evolving density. When the sampling frequency is sufficiently high, the optimal maps are close to the identity and are thus computationally efficient to compute. Moreover, the training process is highly parallelizable as all optimal maps are independent and can thus be learned simultaneously. Finally, the approach is based solely on numerical linear algebra rather than minimizing a nonconvex objective function, allowing us to easily analyze and control the algorithm. We present several numerical experiments on both synthetic and real-world datasets to demonstrate the efficiency of our method. In particular, these experiments show that the proposed approach is highly competitive compared with state-of-the-art normalizing flows conditioned on time across a wide range of dimensionalities.
Adaptive State-Dependent Diffusion for Derivative-Free Optimization
Feb 08, 2023



This paper develops and analyzes a stochastic derivative-free optimization strategy. A key feature is the state-dependent adaptive variance. We prove global convergence in probability with algebraic rate and give the quantitative results in numerical examples. A striking fact is that convergence is achieved without explicit information of the gradient and even without comparing different objective function values as in established methods such as the simplex method and simulated annealing. It can otherwise be compared to annealing with state-dependent temperature.
Neural Inverse Operators for Solving PDE Inverse Problems
Jan 26, 2023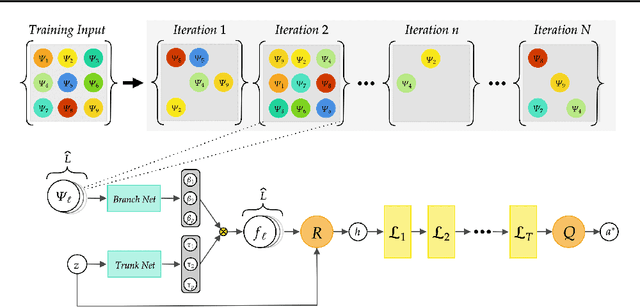
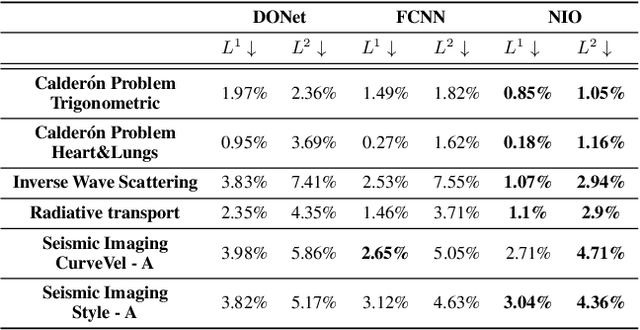

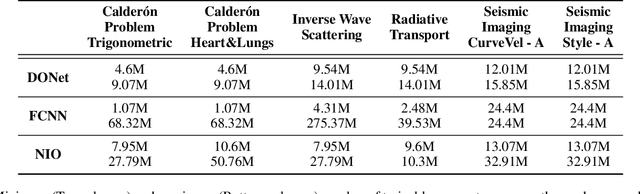
A large class of inverse problems for PDEs are only well-defined as mappings from operators to functions. Existing operator learning frameworks map functions to functions and need to be modified to learn inverse maps from data. We propose a novel architecture termed Neural Inverse Operators (NIOs) to solve these PDE inverse problems. Motivated by the underlying mathematical structure, NIO is based on a suitable composition of DeepONets and FNOs to approximate mappings from operators to functions. A variety of experiments are presented to demonstrate that NIOs significantly outperform baselines and solve PDE inverse problems robustly, accurately and are several orders of magnitude faster than existing direct and PDE-constrained optimization methods.
A Quadrature Perspective on Frequency Bias in Neural Network Training with Nonuniform Data
May 28, 2022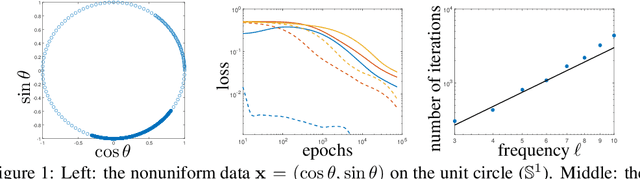
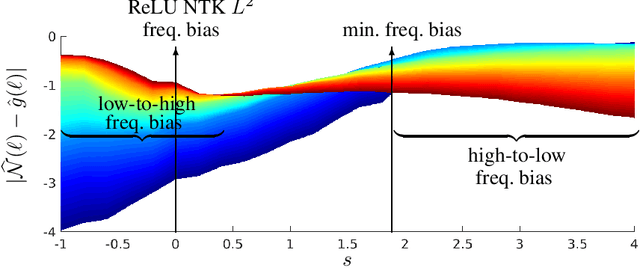


Small generalization errors of over-parameterized neural networks (NNs) can be partially explained by the frequency biasing phenomenon, where gradient-based algorithms minimize the low-frequency misfit before reducing the high-frequency residuals. Using the Neural Tangent Kernel (NTK), one can provide a theoretically rigorous analysis for training where data are drawn from constant or piecewise-constant probability densities. Since most training data sets are not drawn from such distributions, we use the NTK model and a data-dependent quadrature rule to theoretically quantify the frequency biasing of NN training given fully nonuniform data. By replacing the loss function with a carefully selected Sobolev norm, we can further amplify, dampen, counterbalance, or reverse the intrinsic frequency biasing in NN training.