 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRational Neural Networks have Expressivity Advantages
Feb 12, 2026We study neural networks with trainable low-degree rational activation functions and show that they are more expressive and parameter-efficient than modern piecewise-linear and smooth activations such as ELU, LeakyReLU, LogSigmoid, PReLU, ReLU, SELU, CELU, Sigmoid, SiLU, Mish, Softplus, Tanh, Softmin, Softmax, and LogSoftmax. For an error target of $\varepsilon>0$, we establish approximation-theoretic separations: Any network built from standard fixed activations can be uniformly approximated on compact domains by a rational-activation network with only $\mathrm{poly}(\log\log(1/\varepsilon))$ overhead in size, while the converse provably requires $Ω(\log(1/\varepsilon))$ parameters in the worst case. This exponential gap persists at the level of full networks and extends to gated activations and transformer-style nonlinearities. In practice, rational activations integrate seamlessly into standard architectures and training pipelines, allowing rationals to match or outperform fixed activations under identical architectures and optimizers.
Operator learning without the adjoint
Jan 31, 2024



There is a mystery at the heart of operator learning: how can one recover a non-self-adjoint operator from data without probing the adjoint? Current practical approaches suggest that one can accurately recover an operator while only using data generated by the forward action of the operator without access to the adjoint. However, naively, it seems essential to sample the action of the adjoint. In this paper, we partially explain this mystery by proving that without querying the adjoint, one can approximate a family of non-self-adjoint infinite-dimensional compact operators via projection onto a Fourier basis. We then apply the result to recovering Green's functions of elliptic partial differential operators and derive an adjoint-free sample complexity bound. While existing theory justifies low sample complexity in operator learning, ours is the first adjoint-free analysis that attempts to close the gap between theory and practice.
Operator learning for hyperbolic partial differential equations
Dec 29, 2023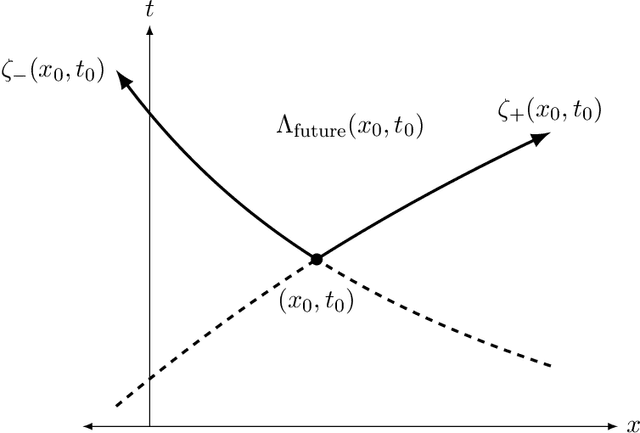
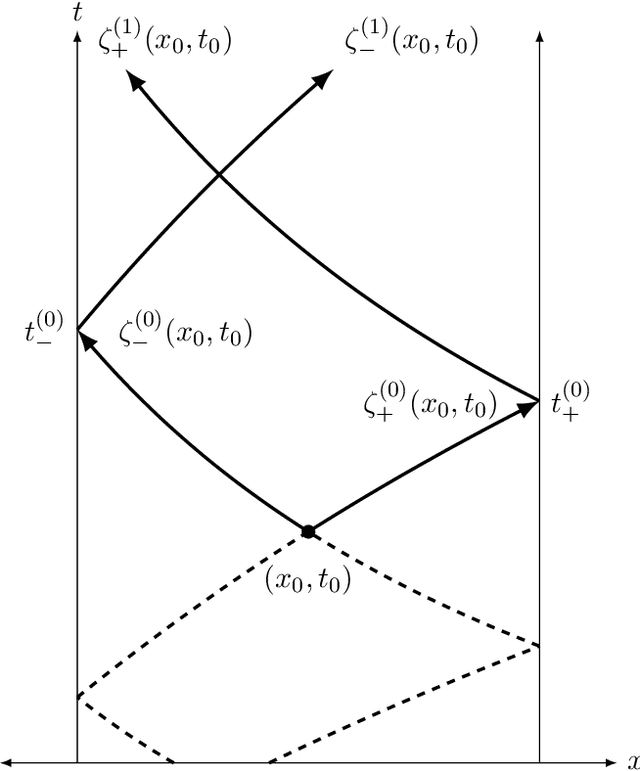
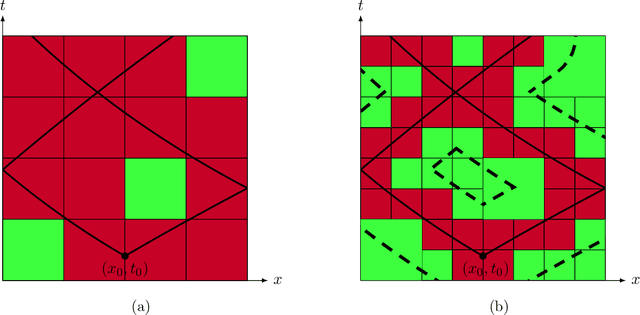
We construct the first rigorously justified probabilistic algorithm for recovering the solution operator of a hyperbolic partial differential equation (PDE) in two variables from input-output training pairs. The primary challenge of recovering the solution operator of hyperbolic PDEs is the presence of characteristics, along which the associated Green's function is discontinuous. Therefore, a central component of our algorithm is a rank detection scheme that identifies the approximate location of the characteristics. By combining the randomized singular value decomposition with an adaptive hierarchical partition of the domain, we construct an approximant to the solution operator using $O(\Psi_\epsilon^{-1}\epsilon^{-7}\log(\Xi_\epsilon^{-1}\epsilon^{-1}))$ input-output pairs with relative error $O(\Xi_\epsilon^{-1}\epsilon)$ in the operator norm as $\epsilon\to0$, with high probability. Here, $\Psi_\epsilon$ represents the existence of degenerate singular values of the solution operator, and $\Xi_\epsilon$ measures the quality of the training data. Our assumptions on the regularity of the coefficients of the hyperbolic PDE are relatively weak given that hyperbolic PDEs do not have the ``instantaneous smoothing effect'' of elliptic and parabolic PDEs, and our recovery rate improves as the regularity of the coefficients increases.
A Mathematical Guide to Operator Learning
Dec 22, 2023Operator learning aims to discover properties of an underlying dynamical system or partial differential equation (PDE) from data. Here, we present a step-by-step guide to operator learning. We explain the types of problems and PDEs amenable to operator learning, discuss various neural network architectures, and explain how to employ numerical PDE solvers effectively. We also give advice on how to create and manage training data and conduct optimization. We offer intuition behind the various neural network architectures employed in operator learning by motivating them from the point-of-view of numerical linear algebra.
Beyond expectations: Residual Dynamic Mode Decomposition and Variance for Stochastic Dynamical Systems
Sep 09, 2023



Koopman operators linearize nonlinear dynamical systems, making their spectral information of crucial interest. Numerous algorithms have been developed to approximate these spectral properties, and Dynamic Mode Decomposition (DMD) stands out as the poster child of projection-based methods. Although the Koopman operator itself is linear, the fact that it acts in an infinite-dimensional space of observables poses challenges. These include spurious modes, essential spectra, and the verification of Koopman mode decompositions. While recent work has addressed these challenges for deterministic systems, there remains a notable gap in verified DMD methods for stochastic systems, where the Koopman operator measures the expectation of observables. We show that it is necessary to go beyond expectations to address these issues. By incorporating variance into the Koopman framework, we address these challenges. Through an additional DMD-type matrix, we approximate the sum of a squared residual and a variance term, each of which can be approximated individually using batched snapshot data. This allows verified computation of the spectral properties of stochastic Koopman operators, controlling the projection error. We also introduce the concept of variance-pseudospectra to gauge statistical coherency. Finally, we present a suite of convergence results for the spectral information of stochastic Koopman operators. Our study concludes with practical applications using both simulated and experimental data. In neural recordings from awake mice, we demonstrate how variance-pseudospectra can reveal physiologically significant information unavailable to standard expectation-based dynamical models.
Elliptic PDE learning is provably data-efficient
Feb 24, 2023

PDE learning is an emerging field that combines physics and machine learning to recover unknown physical systems from experimental data. While deep learning models traditionally require copious amounts of training data, recent PDE learning techniques achieve spectacular results with limited data availability. Still, these results are empirical. Our work provides theoretical guarantees on the number of input-output training pairs required in PDE learning, explaining why these methods can be data-efficient. Specifically, we exploit randomized numerical linear algebra and PDE theory to derive a provably data-efficient algorithm that recovers solution operators of 3D elliptic PDEs from input-output data and achieves an exponential convergence rate with respect to the size of the training dataset with an exceptionally high probability of success.
A Quadrature Perspective on Frequency Bias in Neural Network Training with Nonuniform Data
May 28, 2022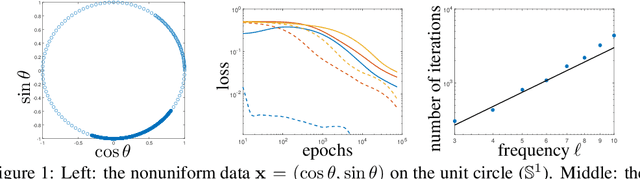
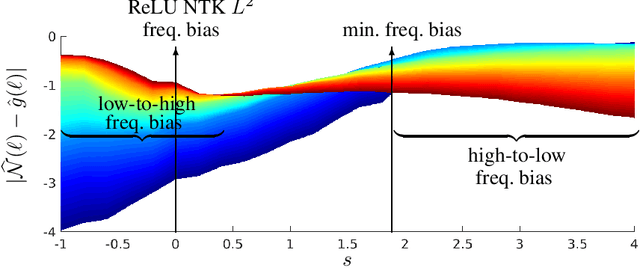


Small generalization errors of over-parameterized neural networks (NNs) can be partially explained by the frequency biasing phenomenon, where gradient-based algorithms minimize the low-frequency misfit before reducing the high-frequency residuals. Using the Neural Tangent Kernel (NTK), one can provide a theoretically rigorous analysis for training where data are drawn from constant or piecewise-constant probability densities. Since most training data sets are not drawn from such distributions, we use the NTK model and a data-dependent quadrature rule to theoretically quantify the frequency biasing of NN training given fully nonuniform data. By replacing the loss function with a carefully selected Sobolev norm, we can further amplify, dampen, counterbalance, or reverse the intrinsic frequency biasing in NN training.
Learning Green's functions associated with parabolic partial differential equations
Apr 27, 2022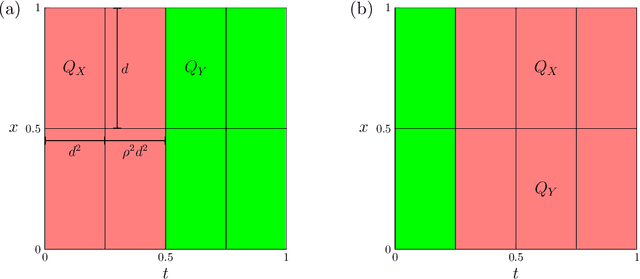
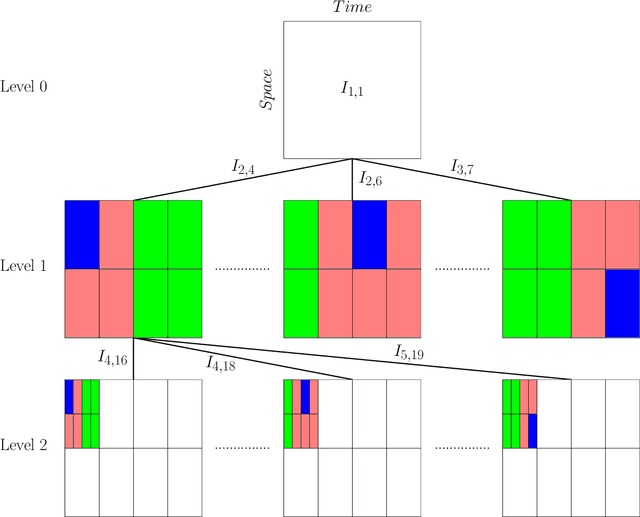
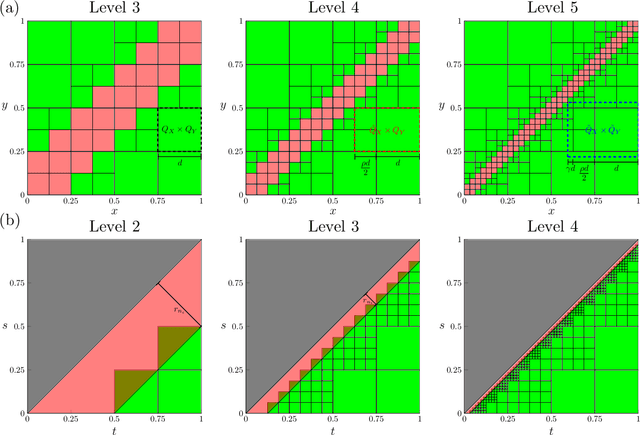
Given input-output pairs from a parabolic partial differential equation (PDE) in any spatial dimension $n\geq 1$, we derive the first theoretically rigorous scheme for learning the associated Green's function $G$. Until now, rigorously learning Green's functions associated with parabolic operators has been a major challenge in the field of scientific machine learning because $G$ may not be square-integrable when $n>1$, and time-dependent PDEs have transient dynamics. By combining the hierarchical low-rank structure of $G$ together with the randomized singular value decomposition, we construct an approximant to $G$ that achieves a relative error of $\smash{\mathcal{O}(\Gamma_\epsilon^{-1/2}\epsilon)}$ in the $L^1$-norm with high probability by using at most $\smash{\mathcal{O}(\epsilon^{-\frac{n+2}{2}}\log(1/\epsilon))}$ input-output training pairs, where $\Gamma_\epsilon$ is a measure of the quality of the training dataset for learning $G$, and $\epsilon>0$ is sufficiently small. Along the way, we extend the low-rank theory of Bebendorf and Hackbusch from elliptic PDEs in dimension $1\leq n\leq 3$ to parabolic PDEs in any dimensions, which shows that Green's functions associated with parabolic PDEs admit a low-rank structure on well-separated domains.
Rigorous data-driven computation of spectral properties of Koopman operators for dynamical systems
Nov 29, 2021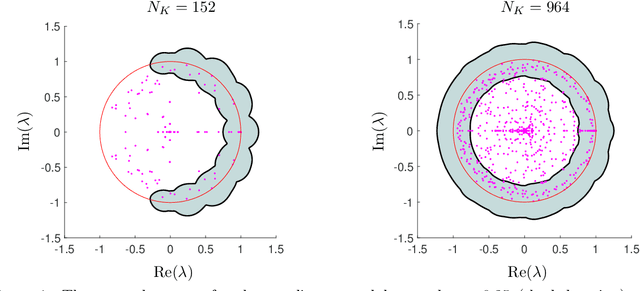
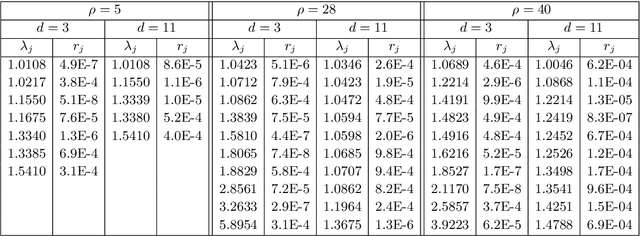
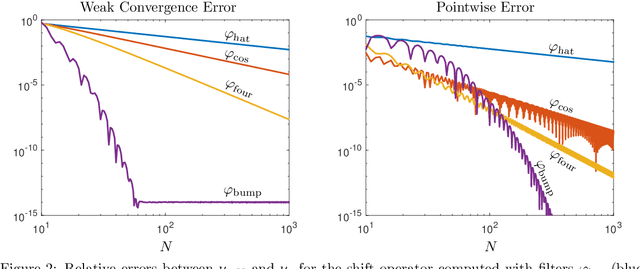

Koopman operators are infinite-dimensional operators that globally linearize nonlinear dynamical systems, making their spectral information useful for understanding dynamics. However, Koopman operators can have continuous spectra and infinite-dimensional invariant subspaces, making computing their spectral information a considerable challenge. This paper describes data-driven algorithms with rigorous convergence guarantees for computing spectral information of Koopman operators from trajectory data. We introduce residual dynamic mode decomposition (ResDMD), which provides the first scheme for computing the spectra and pseudospectra of general Koopman operators from snapshot data without spectral pollution. Using the resolvent operator and ResDMD, we also compute smoothed approximations of spectral measures associated with measure-preserving dynamical systems. We prove explicit convergence theorems for our algorithms, which can achieve high-order convergence even for chaotic systems, when computing the density of the continuous spectrum and the discrete spectrum. We demonstrate our algorithms on the tent map, Gauss iterated map, nonlinear pendulum, double pendulum, Lorenz system, and an $11$-dimensional extended Lorenz system. Finally, we provide kernelized variants of our algorithms for dynamical systems with a high-dimensional state-space. This allows us to compute the spectral measure associated with the dynamics of a protein molecule that has a 20,046-dimensional state-space, and compute nonlinear Koopman modes with error bounds for turbulent flow past aerofoils with Reynolds number $>10^5$ that has a 295,122-dimensional state-space.
Arbitrary-Depth Universal Approximation Theorems for Operator Neural Networks
Sep 23, 2021
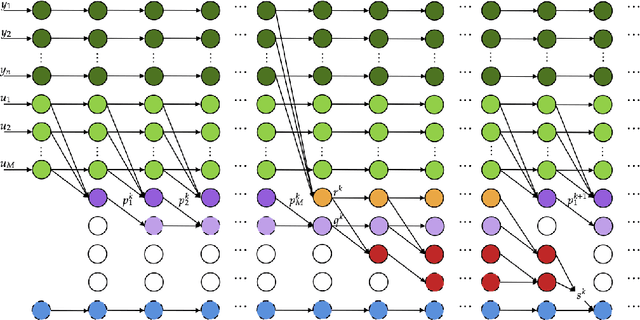
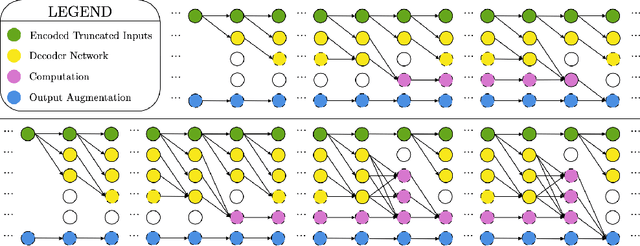
The standard Universal Approximation Theorem for operator neural networks (NNs) holds for arbitrary width and bounded depth. Here, we prove that operator NNs of bounded width and arbitrary depth are universal approximators for continuous nonlinear operators. In our main result, we prove that for non-polynomial activation functions that are continuously differentiable at a point with a nonzero derivative, one can construct an operator NN of width five, whose inputs are real numbers with finite decimal representations, that is arbitrarily close to any given continuous nonlinear operator. We derive an analogous result for non-affine polynomial activation functions. We also show that depth has theoretical advantages by constructing operator ReLU NNs of depth $2k^3+8$ and constant width that cannot be well-approximated by any operator ReLU NN of depth $k$, unless its width is exponential in $k$.