 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Learning for Generation with Long Source Sequences
Apr 15, 2021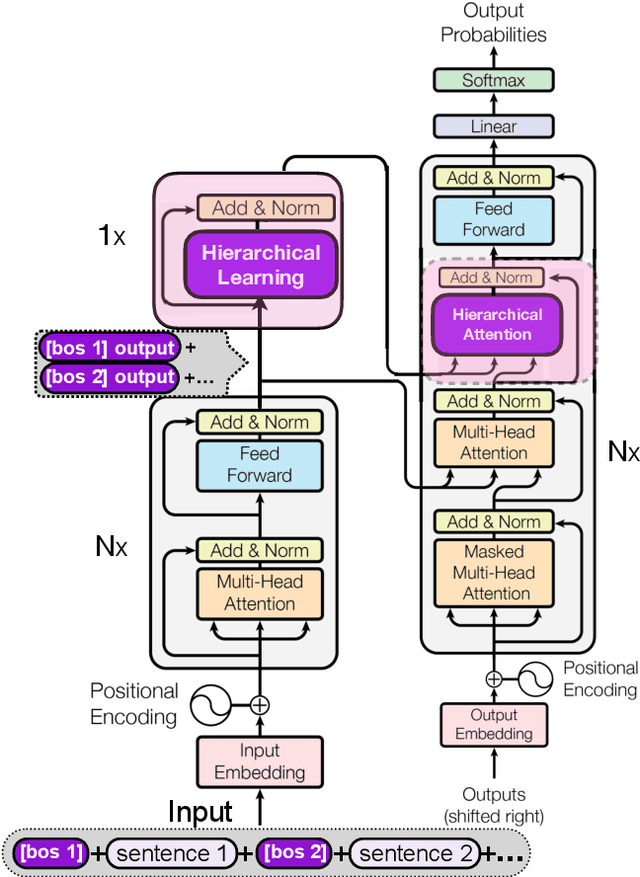



One of the challenges for current sequence to sequence (seq2seq) models is processing long sequences, such as those in summarization and document level machine translation tasks. These tasks require the model to reason at the token level as well as the sentence and paragraph level. We design and study a new Hierarchical Attention Transformer-based architecture (HAT) that outperforms standard Transformers on several sequence to sequence tasks. In particular, our model achieves stateof-the-art results on four summarization tasks, including ArXiv, CNN/DM, SAMSum, and AMI, and we push PubMed R1 & R2 SOTA further. Our model significantly outperforms our document-level machine translation baseline by 28 BLEU on the WMT19 EN-DE document translation task. We also investigate what the hierarchical layers learn by visualizing the hierarchical encoder-decoder attention. Finally, we study hierarchical learning on encoder-only pre-training and analyze its performance on classification downstream tasks.
Recipes for building an open-domain chatbot
Apr 30, 2020

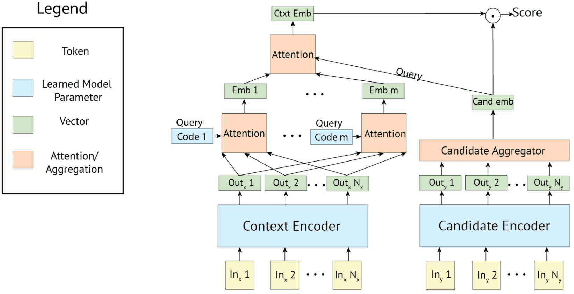

Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that scaling neural models in the number of parameters and the size of the data they are trained on gives improved results, we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent persona. We show that large scale models can learn these skills when given appropriate training data and choice of generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing failure cases of our models.
Multilingual Denoising Pre-training for Neural Machine Translation
Jan 23, 2020
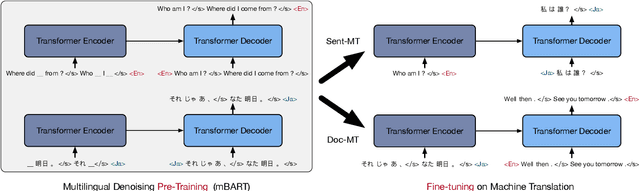


This paper demonstrates that multilingual denoising pre-training produces significant performance gains across a wide variety of machine translation (MT) tasks. We present mBART -- a sequence-to-sequence denoising auto-encoder pre-trained on large-scale monolingual corpora in many languages using the BART objective. mBART is one of the first methods for pre-training a complete sequence-to-sequence model by denoising full texts in multiple languages, while previous approaches have focused only on the encoder, decoder, or reconstructing parts of the text. Pre-training a complete model allows it to be directly fine tuned for supervised (both sentence-level and document-level) and unsupervised machine translation, with no task-specific modifications. We demonstrate that adding mBART initialization produces performance gains in all but the highest-resource settings, including up to 12 BLEU points for low resource MT and over 5 BLEU points for many document-level and unsupervised models. We also show it also enables new types of transfer to language pairs with no bi-text or that were not in the pre-training corpus, and present extensive analysis of which factors contribute the most to effective pre-training.
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Oct 29, 2019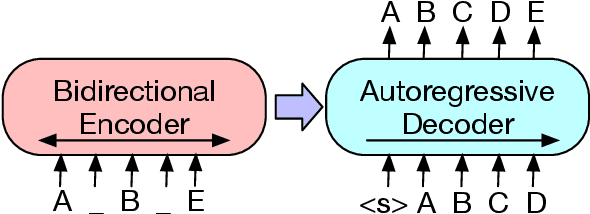

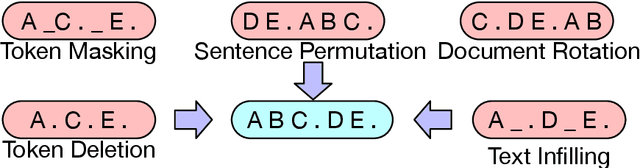

We present BART, a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. It uses a standard Tranformer-based neural machine translation architecture which, despite its simplicity, can be seen as generalizing BERT (due to the bidirectional encoder), GPT (with the left-to-right decoder), and many other more recent pretraining schemes. We evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token. BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains of up to 6 ROUGE. BART also provides a 1.1 BLEU increase over a back-translation system for machine translation, with only target language pretraining. We also report ablation experiments that replicate other pretraining schemes within the BART framework, to better measure which factors most influence end-task performance.
SpanBERT: Improving Pre-training by Representing and Predicting Spans
Jul 31, 2019
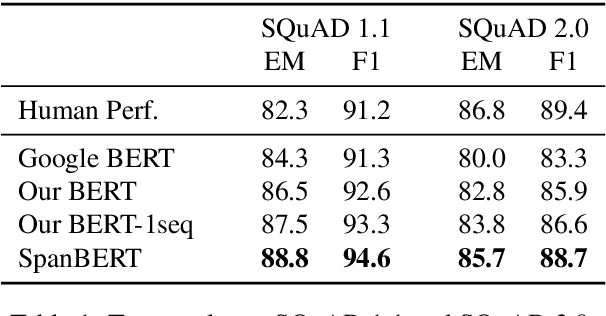
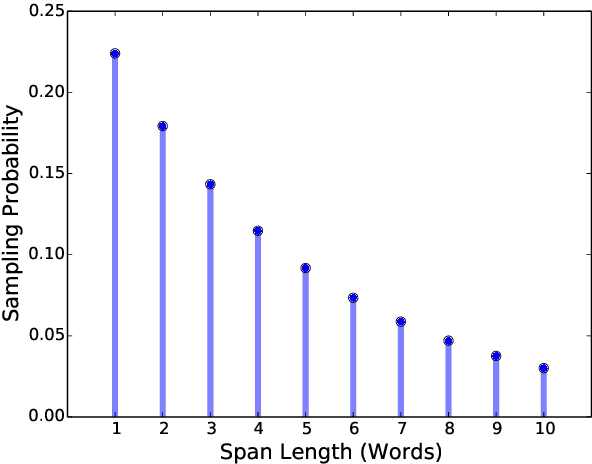

We present SpanBERT, a pre-training method that is designed to better represent and predict spans of text. Our approach extends BERT by (1) masking contiguous random spans, rather than random tokens, and (2) training the span boundary representations to predict the entire content of the masked span, without relying on the individual token representations within it. SpanBERT consistently outperforms BERT and our better-tuned baselines, with substantial gains on span selection tasks such as question answering and coreference resolution. In particular, with the same training data and model size as BERT-large, our single model obtains 94.6% and 88.7% F1 on SQuAD 1.1 and 2.0, respectively. We also achieve a new state of the art on the OntoNotes coreference resolution task (79.6\% F1), strong performance on the TACRED relation extraction benchmark, and even show gains on GLUE.
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Jul 26, 2019
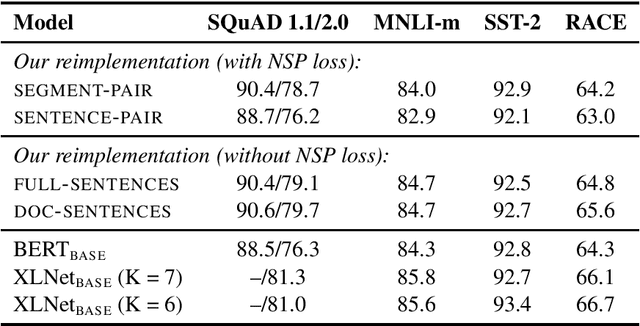

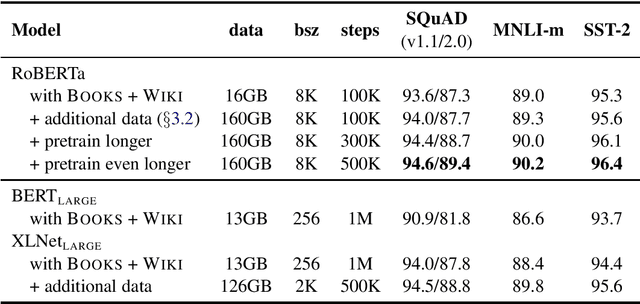
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results highlight the importance of previously overlooked design choices, and raise questions about the source of recently reported improvements. We release our models and code.
Constant-Time Machine Translation with Conditional Masked Language Models
Apr 19, 2019



Most machine translation systems generate text autoregressively, by sequentially predicting tokens from left to right. We, instead, use a masked language modeling objective to train a model to predict any subset of the target words, conditioned on both the input text and a partially masked target translation. This approach allows for efficient iterative decoding, where we first predict all of the target words non-autoregressively, and then repeatedly mask out and regenerate the subset of words that the model is least confident about. By applying this strategy for a constant number of iterations, our model improves state-of-the-art performance levels for constant-time translation models by over 3 BLEU on average. It is also able to reach 92-95% of the performance of a typical left-to-right transformer model, while decoding significantly faster.
Cloze-driven Pretraining of Self-attention Networks
Mar 19, 2019



We present a new approach for pretraining a bi-directional transformer model that provides significant performance gains across a variety of language understanding problems. Our model solves a cloze-style word reconstruction task, where each word is ablated and must be predicted given the rest of the text. Experiments demonstrate large performance gains on GLUE and new state of the art results on NER as well as constituency parsing benchmarks, consistent with the concurrently introduced BERT model. We also present a detailed analysis of a number of factors that contribute to effective pretraining, including data domain and size, model capacity, and variations on the cloze objective.