 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINER++: Building a Family of Variable-periodic Functions for Activating Implicit Neural Representation
Jul 28, 2024



Implicit Neural Representation (INR), which utilizes a neural network to map coordinate inputs to corresponding attributes, is causing a revolution in the field of signal processing. However, current INR techniques suffer from the "frequency"-specified spectral bias and capacity-convergence gap, resulting in imperfect performance when representing complex signals with multiple "frequencies". We have identified that both of these two characteristics could be handled by increasing the utilization of definition domain in current activation functions, for which we propose the FINER++ framework by extending existing periodic/non-periodic activation functions to variable-periodic ones. By initializing the bias of the neural network with different ranges, sub-functions with various frequencies in the variable-periodic function are selected for activation. Consequently, the supported frequency set can be flexibly tuned, leading to improved performance in signal representation. We demonstrate the generalization and capabilities of FINER++ with different activation function backbones (Sine, Gauss. and Wavelet) and various tasks (2D image fitting, 3D signed distance field representation, 5D neural radiance fields optimization and streamable INR transmission), and we show that it improves existing INRs. Project page: {https://liuzhen0212.github.io/finerpp/}
FINER: Flexible spectral-bias tuning in Implicit NEural Representation by Variable-periodic Activation Functions
Dec 05, 2023Implicit Neural Representation (INR), which utilizes a neural network to map coordinate inputs to corresponding attributes, is causing a revolution in the field of signal processing. However, current INR techniques suffer from a restricted capability to tune their supported frequency set, resulting in imperfect performance when representing complex signals with multiple frequencies. We have identified that this frequency-related problem can be greatly alleviated by introducing variable-periodic activation functions, for which we propose FINER. By initializing the bias of the neural network within different ranges, sub-functions with various frequencies in the variable-periodic function are selected for activation. Consequently, the supported frequency set of FINER can be flexibly tuned, leading to improved performance in signal representation. We demonstrate the capabilities of FINER in the contexts of 2D image fitting, 3D signed distance field representation, and 5D neural radiance fields optimization, and we show that it outperforms existing INRs.
Two halves of a meaningful text are statistically different
Apr 09, 2020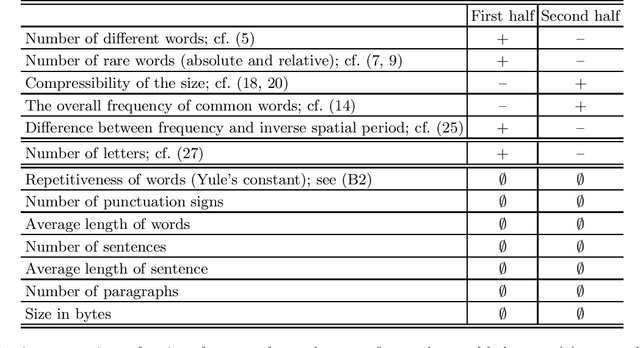
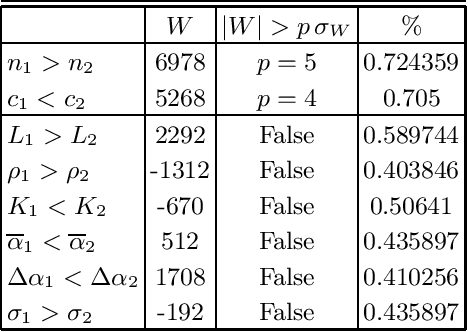
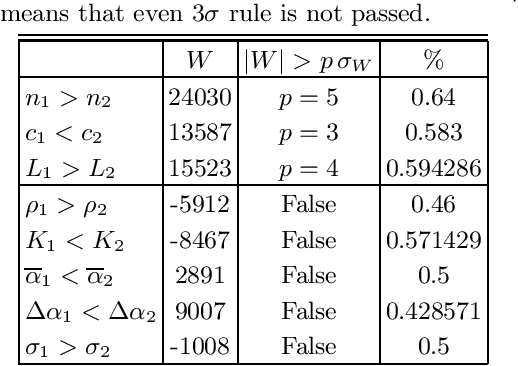
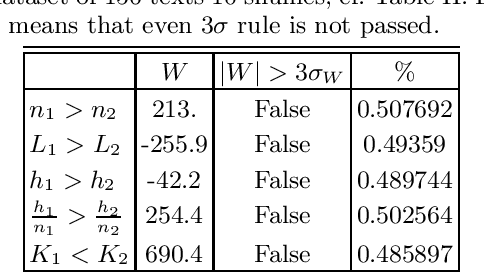
Which statistical features distinguish a meaningful text (possibly written in an unknown system) from a meaningless set of symbols? Here we answer this question by comparing features of the first half of a text to its second half. This comparison can uncover hidden effects, because the halves have the same values of many parameters (style, genre {\it etc}). We found that the first half has more different words and more rare words than the second half. Also, words in the first half are distributed less homogeneously over the text in the sense of of the difference between the frequency and the inverse spatial period. These differences hold for the significant majority of several hundred relatively short texts we studied. The statistical significance is confirmed via the Wilcoxon test. Differences disappear after random permutation of words that destroys the linear structure of the text. The differences reveal a temporal asymmetry in meaningful texts, which is confirmed by showing that texts are much better compressible in their natural way (i.e. along the narrative) than in the word-inverted form. We conjecture that these results connect the semantic organization of a text (defined by the flow of its narrative) to its statistical features.
Active image restoration
Sep 22, 2018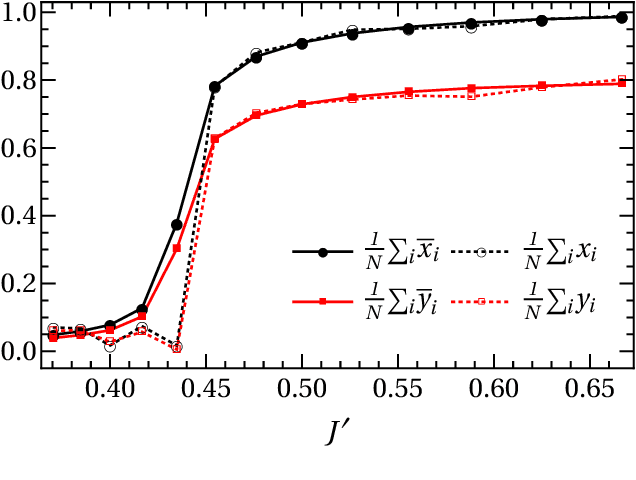


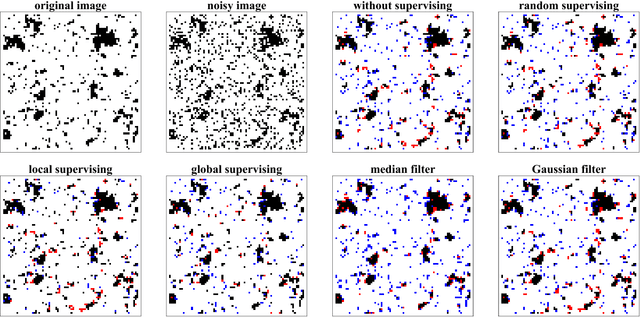
We study active restoration of noise-corrupted images generated via the Gibbs probability of an Ising ferromagnet in external magnetic field. Ferromagnetism accounts for the prior expectation of data smoothness, i.e. a positive correlation between neighbouring pixels (Ising spins), while the magnetic field refers to the bias. The restoration is actively supervised by requesting the true values of certain pixels after a noisy observation. This additional information improves restoration of other pixels. The optimal strategy of active inference is not known for realistic (two-dimensional) images. We determine this strategy for the mean-field version of the model and show that it amounts to supervising the values of spins (pixels) that do not agree with the sign of the average magnetization. The strategy leads to a transparent analytical expression for the minimal Bayesian risk, and shows that there is a maximal number of pixels beyond of which the supervision is useless. We show numerically that this strategy applies for two-dimensional images away from the critical regime. Within this regime the strategy is outperformed by its local (adaptive) version, which supervises pixels that do not agree with their Bayesian estimate. We show on transparent examples how active supervising can be essential in recovering noise-corrupted images and advocate for a wider usage of active methods in image restoration.
Relating Zipf's law to textual information
Sep 22, 2018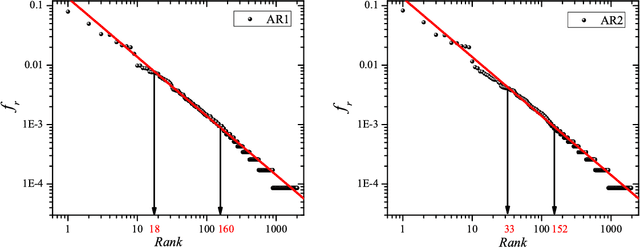
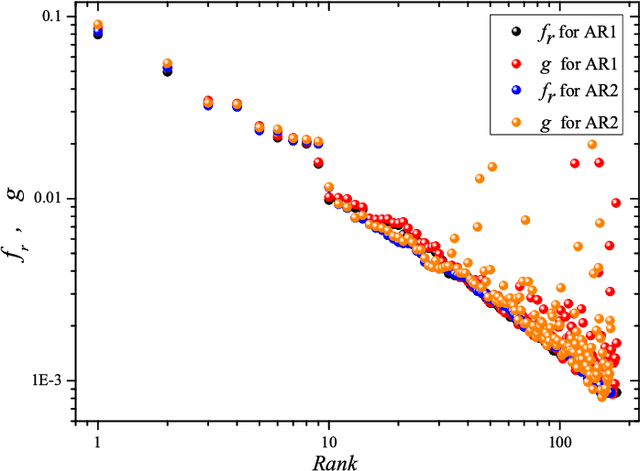
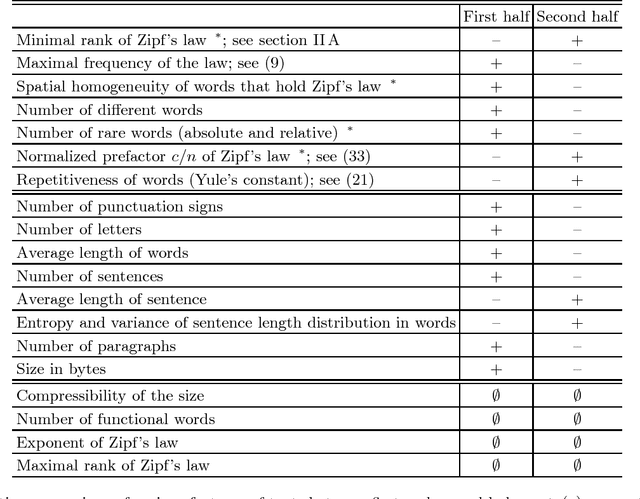
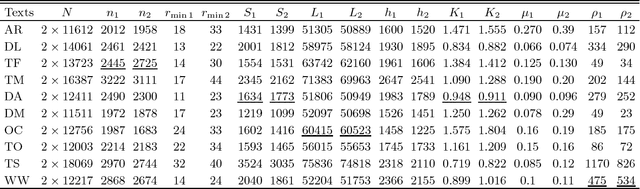
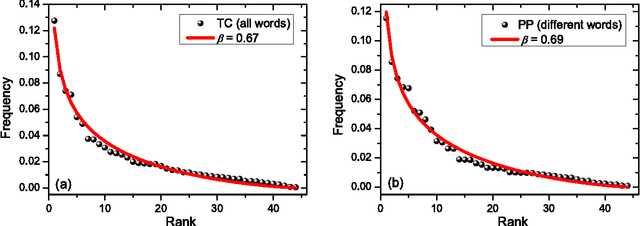
Zipf's law is the main regularity of quantitative linguistics. Despite of many works devoted to foundations of this law, it is still unclear whether it is only a statistical regularity, or it has deeper relations with information-carrying structures of the text. This question relates to that of distinguishing a meaningful text (written in an unknown system) from a meaningless set of symbols that mimics statistical features of a text. Here we contribute to resolving these questions by comparing features of the first half of a text (from the beginning to the middle) to its second half. This comparison can uncover hidden effects, because the halves have the same values of many parameters (style, genre, author's vocabulary {\it etc}). In all studied texts we saw that for the first half Zipf's law applies from smaller ranks than in the second half, i.e. the law applies better to the first half. Also, words that hold Zipf's law in the first half are distributed more homogeneously over the text. These features do allow to distinguish a meaningful text from a random sequence of words. Our findings correlate with a number of textual characteristics that hold in most cases we studied: the first half is lexically richer, has longer and less repetitive words, more and shorter sentences, more punctuation signs and more paragraphs. These differences between the halves indicate on a higher hierarchic level of text organization that so far went unnoticed in text linguistics. They relate the validity of Zipf's law to textual information. A complete description of this effect requires new models, though one existing model can account for some of its aspects.
Stochastic model for phonemes uncovers an author-dependency of their usage
Mar 20, 2016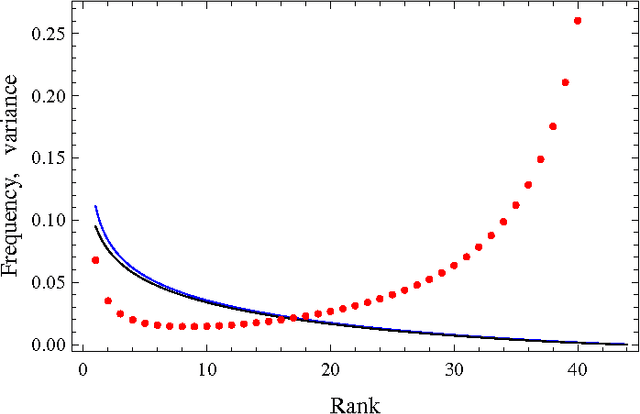
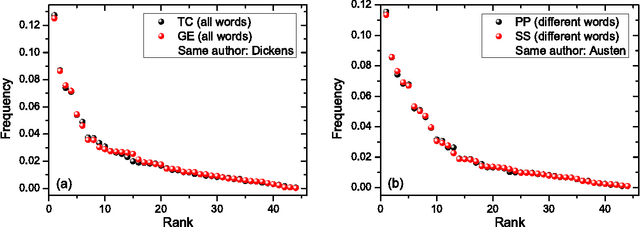
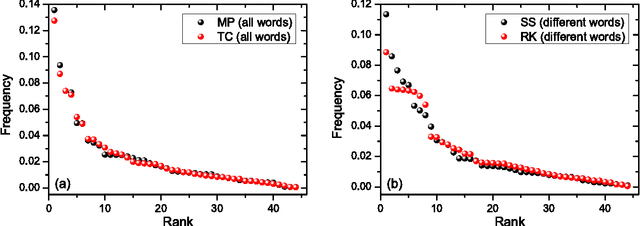
We study rank-frequency relations for phonemes, the minimal units that still relate to linguistic meaning. We show that these relations can be described by the Dirichlet distribution, a direct analogue of the ideal-gas model in statistical mechanics. This description allows us to demonstrate that the rank-frequency relations for phonemes of a text do depend on its author. The author-dependency effect is not caused by the author's vocabulary (common words used in different texts), and is confirmed by several alternative means. This suggests that it can be directly related to phonemes. These features contrast to rank-frequency relations for words, which are both author and text independent and are governed by the Zipf's law.
* 16 pages, 4 figures
Explaining Zipf's Law via Mental Lexicon
Feb 18, 2013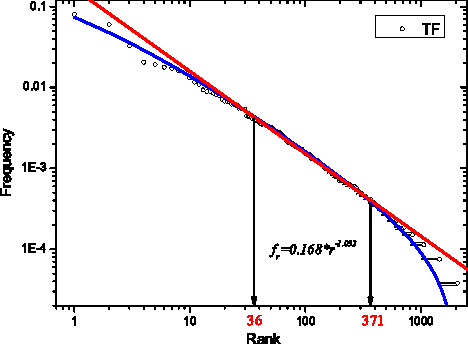
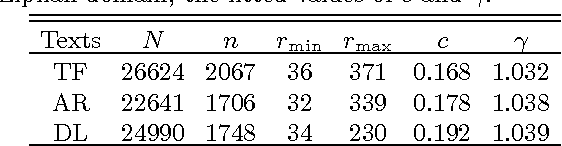
The Zipf's law is the major regularity of statistical linguistics that served as a prototype for rank-frequency relations and scaling laws in natural sciences. Here we show that the Zipf's law -- together with its applicability for a single text and its generalizations to high and low frequencies including hapax legomena -- can be derived from assuming that the words are drawn into the text with random probabilities. Their apriori density relates, via the Bayesian statistics, to general features of the mental lexicon of the author who produced the text.