 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo halves of a meaningful text are statistically different
Paper and Code
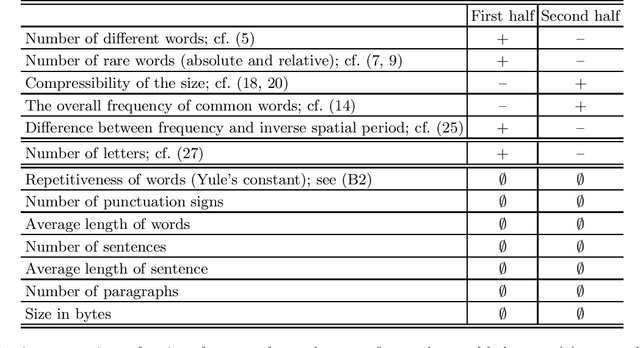
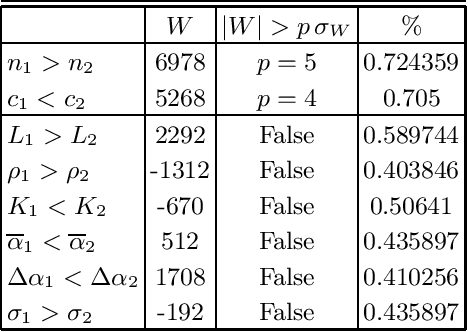
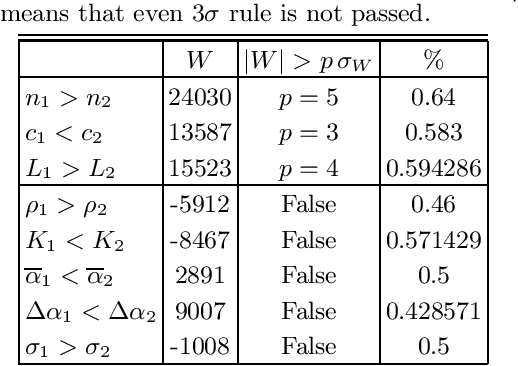
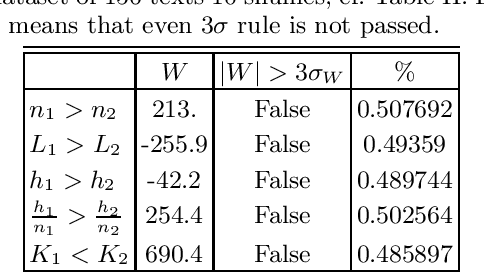
Which statistical features distinguish a meaningful text (possibly written in an unknown system) from a meaningless set of symbols? Here we answer this question by comparing features of the first half of a text to its second half. This comparison can uncover hidden effects, because the halves have the same values of many parameters (style, genre {\it etc}). We found that the first half has more different words and more rare words than the second half. Also, words in the first half are distributed less homogeneously over the text in the sense of of the difference between the frequency and the inverse spatial period. These differences hold for the significant majority of several hundred relatively short texts we studied. The statistical significance is confirmed via the Wilcoxon test. Differences disappear after random permutation of words that destroys the linear structure of the text. The differences reveal a temporal asymmetry in meaningful texts, which is confirmed by showing that texts are much better compressible in their natural way (i.e. along the narrative) than in the word-inverted form. We conjecture that these results connect the semantic organization of a text (defined by the flow of its narrative) to its statistical features.