 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating Zipf's law to textual information
Paper and Code
Sep 22, 2018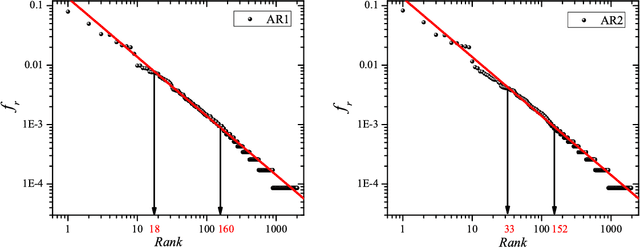
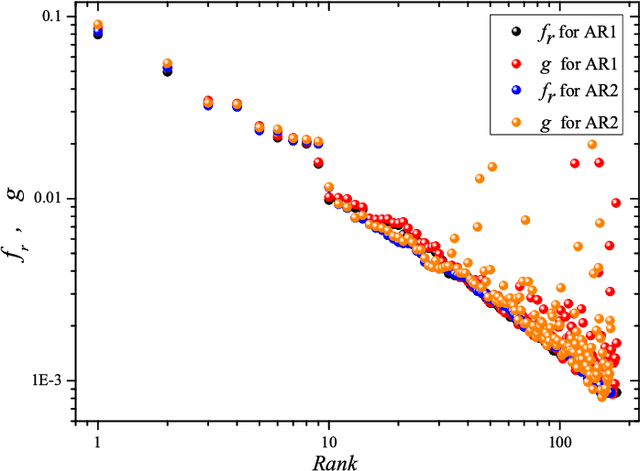
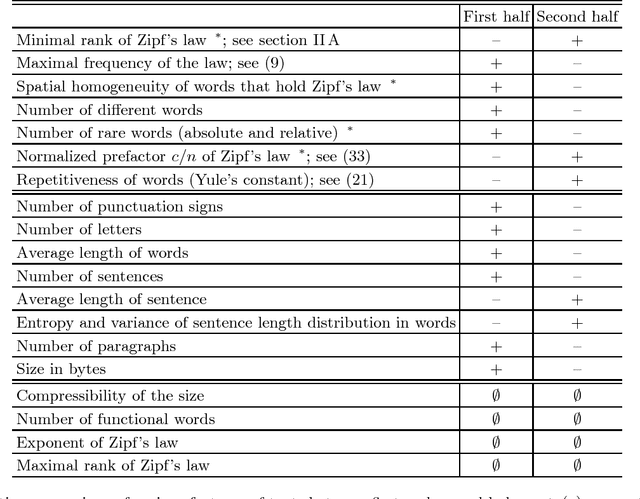
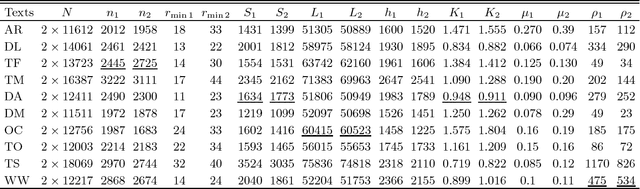
Zipf's law is the main regularity of quantitative linguistics. Despite of many works devoted to foundations of this law, it is still unclear whether it is only a statistical regularity, or it has deeper relations with information-carrying structures of the text. This question relates to that of distinguishing a meaningful text (written in an unknown system) from a meaningless set of symbols that mimics statistical features of a text. Here we contribute to resolving these questions by comparing features of the first half of a text (from the beginning to the middle) to its second half. This comparison can uncover hidden effects, because the halves have the same values of many parameters (style, genre, author's vocabulary {\it etc}). In all studied texts we saw that for the first half Zipf's law applies from smaller ranks than in the second half, i.e. the law applies better to the first half. Also, words that hold Zipf's law in the first half are distributed more homogeneously over the text. These features do allow to distinguish a meaningful text from a random sequence of words. Our findings correlate with a number of textual characteristics that hold in most cases we studied: the first half is lexically richer, has longer and less repetitive words, more and shorter sentences, more punctuation signs and more paragraphs. These differences between the halves indicate on a higher hierarchic level of text organization that so far went unnoticed in text linguistics. They relate the validity of Zipf's law to textual information. A complete description of this effect requires new models, though one existing model can account for some of its aspects.